光学字符识别OCR-6 光学识别
经过前面的文字定位和文本切割,我们已经能够找出图像中单个文字的区域,接下来可以建立相应的模型对单字进行识别。
模型选择
在模型方面,我们选择了深度学习中的卷积神经网络模型,通过多层卷积神经网络,构建了单字的识别模型。
卷积神经网络是人工神经网络的一种,已成为当前图像识别领域的主流模型。 它通过局部感知野和权值共享方法,降低了网络模型的复杂度,减少了权值的数量,在网络结构上更类似于生物神经网络,这也预示着它必然具有更优秀的效果。 事实上,我们选择卷积神经网络的主要原因有:
1. 对原始图像自动提取特征 卷积神经网络模型可以直接将原始图像进行输入,免除了传统模型的人工提取特征这一比较困难的核心部分;
2. 比传统模型更高的精度 比如在MNIST手写数字识别任务中,可以达到99%以上的精度,这远高于传统模型的精度;
3. 比传统模型更好的泛化能力 这意味着图像本身的形变(伸缩、旋转)以及图像上的噪音对识别的结果影响不明显,这正是一个良好的OCR系统所必需的。
训练数据
为了训练一个良好的模型,必须有足够多的训练数据。幸运的是,虽然没有现成的数据可以用,但是由于我们只是做印刷字体的识别,因此,我们可以使用计算机自动生成一批训练数据。通过以下步骤,我们构建了一批比较充分的训练数据:
1. 更多细节 由于汉字的结构比数字和英文都要复杂,因此,为了体现更多的细节信息,我使用48×48的灰度图像构建样本,作为模型的输入;
2. 常见汉字 为了保证模型的实用性,我们从网络爬取了数十万篇微信公众平台上的文章,然后合并起来统计各自的频率,最后选出了频率最高的3000个汉字(在本文中我们只考虑简体字),并且加上26个字母(大小写)和10个数字,共3062字作为模型的输出;
3. 数据充分 我们人工收集了45种不同的字体,从正规的宋体、黑体、楷体到不规范的手写体都有,基本上能够比较全面地覆盖各种印刷字体;
4. 人工噪音 每种字体都构建了5种不同字号(46到50)的图片,每种字号2张,并且为了增强模型的泛化能力,将每个样本都加上5%的随机噪音。
经过上述步骤,我们一共生成了3062×45×5×2=1377900个样本作为训练样本,可见数据量是足够充分的
模型结构
在模型结构方面,有一些前人的工作可以参考的。一个类似的例子是MNIST手写数字的识别——它往往作为一个新的图像识别模型的“试金石”——是要将六万多张大小为28×28像素的手写数字图像进行识别,这个案例跟我们实现汉字的识别系统具有一定的相似性,因此在模型的结构方面可以借鉴。一个常见的通过卷积神经网络对MNIST手写数字进行识别的模型结构如图
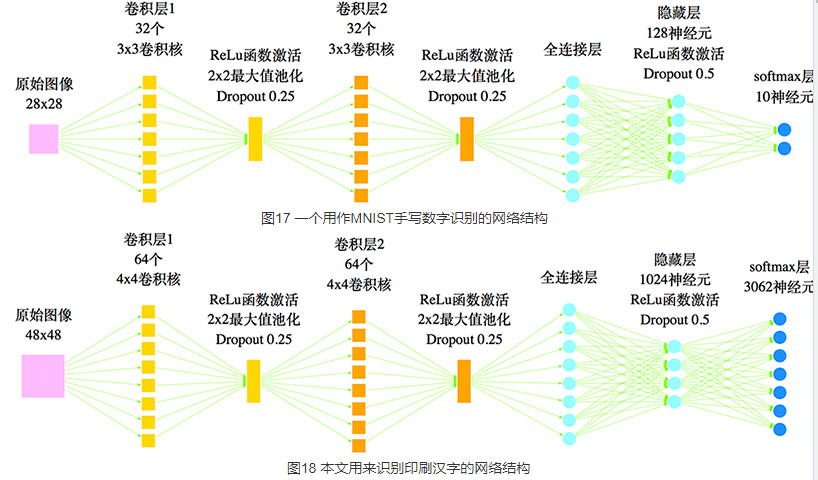
经过充分训练后,如图17的网络结构可以达到99%以上的精确度,说明这种结构确实是可取的。但是很显然,手写数字不过只有10个,而常用汉字具有数千个,在本文的分类任务中,就共有3062个目标。也就是说,汉字具有更为复杂和精细的结构,因此模型的各方面都要进行调整。首先,在模型的输入方面,我们已经将图像的大小从28x28提高为48x48,这能保留更多的细节,其次,在模型结构上要复杂化调整,包括:增加卷积核的数目,增加隐藏节点的数目、调整权重等。最终我们的网络结构如图18。
在激活函数方面,我们选取了RuLe函数为激活函数

实验表明,它相比于传统的sigmoid、tanh等激活函数,能够大大地提升模型效果[3][4];在防止过拟合方面,我们使用了深度学习网络中最常用的Dropout方式[5],即随机地让部分神经元休眠,这等价于同时训练多个不同网络,从而防止了部分节点可能出现的过拟合现象。
需要指出的是,在模型结构方面,我们事实上做了大量的筛选工作。比如隐藏层神经元的数目,我们就耗费了若干天时间,尝试了512、1024、2048、4096、8192等数目,最终得到1024这个比较适合的值。数目太多则导致模型太庞大,而且容易过拟合;太少则容易欠拟合,效果不好。我们的测试发现,从512到1024,效果有明显提升;而再增加节点效果没有明显提升,有时还会有明显下降。
模型实现
我们的模型在操作系统为CentOS 7的服务器(24核CPU+96G内存+GTX960显卡)下完成,使用Python 2。7编写代码,并且使用Keras作为深度学习库,用Theano作为GPU加速库(Tensorflow一直提示内存溢出,配置不成功。 )。
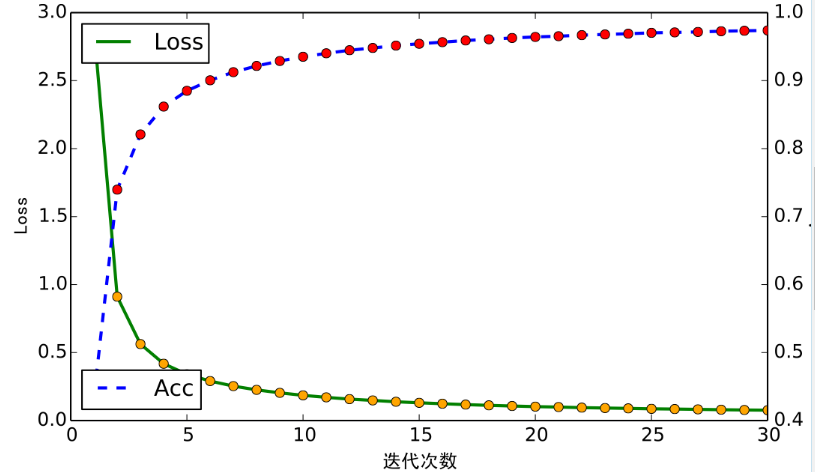
在训练算法方面,使用了Adam优化方法进行训练,batch size为1024,迭代30次,迭代一次大约需要700秒。
如果出现形近字时,应该是高频字更有可能,最典型的例子就是“日”、“曰”了,这两个的特征是很相似的,但是“日”出现的频率远高于“曰”,因此,应当优先考虑“日”。 因此,在训练模型的时候,我们还对模型最终的损失函数进行了调整,使得高频字的权重更大,这样能够提升模型的预测性能。
经过多次调试,最终得到了一个比较可靠的模型。 模型的收敛过程如下图。
模型检验
我们将从以下三个方面对模型进行检验。 实验结果表明,对于单字的识别效果,我们的模型优于Google开源的OCR系统Tesseract。
训练集检验
最终训练出来的模型,在训练集的检验报告如表1。
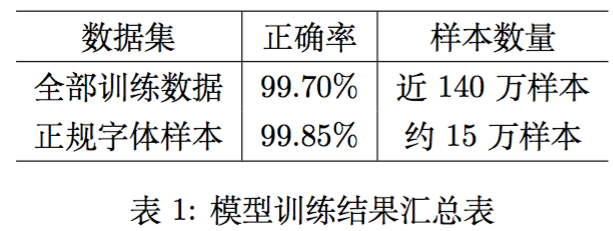
从表1可以看到,即便在加入了随机噪音的样本中,模型的正确率仍然有99。7%,因此,我们有把握地说,单纯从单字识别这部分来看,我们的结果已经达到了state of the art级别,而且在黑体、宋体等正规字体中(正规字体样本是指所有训练样本中,字体为黑体、宋体、楷体、微软雅黑和Arial unicode MS的训练样本,这几种字体常见于印刷体中。),正确率更加高!
测试集检验
我们另外挑选了5种字体,根据同样的方法生成了一批测试样本(每种字体30620张,共153100张),用来对模型进行测试,得到模型测试正确率为92.11%。 五种字体的测试结果如表2
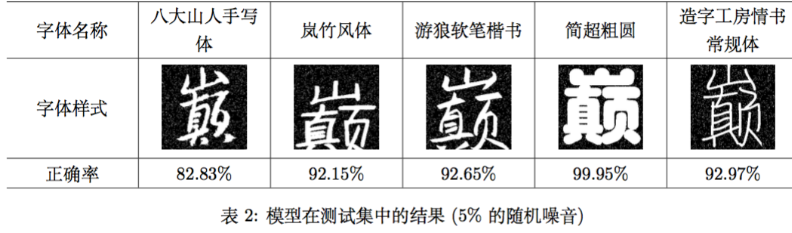
从表中可以看出,即便是对于训练集之外的样本,模型效果也相当不错。接着,我们将随机噪音增大到15%(这对于一张48×48的文字图片来说已经相当糟糕了),得到的测试结果如表3。

平均的正确率为87。59%,也就是说,噪音的影响并不明显,模型能够保持90%左右的正确率。 这说明该模型已经完全达到了实用的程度。
光学字符识别OCR-6 光学识别的更多相关文章
- 光学字符识别OCR
1.功能: 光学字符识别(OCR,Optical Character Recognition)是指对文本资料进行扫描,然后对图像文件进行分析处理,获取文字及版面信息的过程 2.典型应用: 名片扫描 3 ...
- 6 个优秀的开源 OCR 光学字符识别工具
转自:http://sigvc.org/bbs/thread-870-1-1.html 纸张在许多地方已日益失宠,无纸化办公谈论40多年,办公环境正限制纸山的生成.而过去几年,无纸化办公的概念发生了显 ...
- 开源OCR光学字符识别
纸张在 许多地方已日益失宠,无纸化办公谈论40多年,办公环境正限制纸山的生成.而过去几年,无纸化办公的概念发生了显着的转变.在计算机软件的帮助 下,包含大量重要管理数据和资讯的文档可以更方便的以电子形 ...
- 字符识别OCR研究一(模板匹配&BP神经网络训练)
摘 要 在MATLAB环境下利用USB摄像头採集字符图像.读取一帧保存为图像.然后对读取保存的字符图像,灰度化.二值化,在此基础上做倾斜矫正.对矫正的图像进行滤波平滑处理,然后对字符区域进行提取切割出 ...
- [Xcode 实际操作]七、文件与数据-(22)使用OCR光学字符识别技术识别银行卡号码
目录:[Swift]Xcode实际操作 本文将演示如何使用光学字符识别技术,识别信用卡上的卡号. OCR技术是光学字符识别的缩写(Optical Character Recognition), 是通过 ...
- IT行业新名词--透明手机/OCR(光学字符识别)/夹背电池
透明手机 机身设计的一大关键部分是可替换玻璃的使用,利用导电技术,在看不到线路的环境下,让LED发光. 这样的玻璃内含液晶分子,对于内容的显示则是通过电流对分子的刺激来实现.当手机断电后,分子位置会随 ...
- 非黑即白--谷歌OCR光学字符识别
# coding=utf-8 #非黑即白--谷歌OCR光学字符识别 # 颜色的世界里,非黑即白.computer表示深信不疑. # 今天研究一下OCR光学识别庞大领域中的众多分支里的一个开源项目的一个 ...
- OCR技术(光学字符识别)
什么是OCR? OCR英文全称是optical character recognition,中文叫光学字符识别.它是利用光学技术和计算机技术把印在或者写在纸上的 文字读取出来,并转换成一种计算机能够接 ...
- OCR (Optical Character Recognition,光学字符识别)
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然后用字符识别方法将形状翻译 ...
- OCR 即 光学字符识别
OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然后用字符识别方法将形状翻译 ...
随机推荐
- linux 环境下备份oracle 数据库
登陆linux后,进入oracle的安装目录下,找到bin那个目录,进入bin目录ls -l 看这些命令的所有者: su - oracle这时会进入这个用户的主目录/home/oracle,此时,可以 ...
- JavaScript 事件对象event
什么是事件对象? 比如当用户单击某个元素的时候,我们给这个元素注册的事件就会触发,该事件的本质就是一个函数,而该函数的形参接收一个event对象. 注:事件通常与函数结合使用,函数不会在事件发生前被执 ...
- css3动画之圆形运动轨迹
css3中通过@keyframes定义动画,animation设置动画属性,从而实现动画效果: 在animation属性当中,可以规定动画的名称.整个动画的运行时间.运动的速度曲线以及其延迟时间.播放 ...
- 从wireshark数据中分析rtmp协议,并提取出H264视频流
我写的小工具 rtmp_parse.exe 使用用法如先介绍下: -sps [文件路径] 解析 sps 数据 文件当中的内容就是纯方本的hexstring: 如 42 E0 33 8D 68 05 ...
- django之session配置
session应用示例 from django.shortcuts import render from django.shortcuts import HttpResponse from djang ...
- SQLServer 2012 Always on配置全过程
AlwaysOn取数据库镜像和故障转移集群之长.AlwaysOn不再像故障转移集群那样需要共享磁盘,从而主副本和辅助副本可以更容易的部署到不同的地理位置:AlwaysOn还打破了镜像只能1对1的限制, ...
- LINQ 基础语句
去全部集合 using (dat0216DataContext con = new dat0216DataContext()) { //LoList 是转换成 List集合 List<Us ...
- (转载)WPF:DataGrid设置行、单元格的前景色
WPF:DataGrid设置行.单元格的前景色 0. 说明 /********************************** 本示例实现功能1.DataGrid基本操作2.列标题样式3.内容居中 ...
- 命令方式重新签名apk
1.(每个指令之间要有一个空格) 注:拿到一个apk后,首先删除META-INF. 1.如果你的电脑装的是jdk1.6,就用下面的命令: 打开命令符,首先直接输入: Jarsigner -keysto ...
- Win10微软帐户切换不回Administrator本地帐户的解决方法【亲测】
在Win10系统中经常会用到微软帐户登录,如应用商店等地方,不过一些用户反馈原来使用Administrator帐户被绑定微软帐户后无法切换回本地帐户,连[改用本地帐户登录]按钮都没有,那么怎么解决呢? ...