hadoop(一)hadoop简介
1. Hadoop 版本衍化历史
Hadoop 是一个由 Apache 基金会所开发的开源分布式系统基础架构。用户可以在不了解 分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。解 决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的 可靠存储和处理。适合处理非结构化数据,包括 HDFS,MapReduce 基本组件。
1. Hadoop 版本衍化历史 由于 Hadoop 版本混乱多变对初级用户造成一定困扰,所以对其版本衍化历史有个大概 了解,有助于在实践过程中选择合适的 Hadoop 版本。 Apache Hadoop 版本分为分为 1.0 和 2.0 两代版本,我们将第一代 Hadoop 称为 Hadoop 1.0,第二代 Hadoop 称为 Hadoop 2.0。下图是 Apache Hadoop的版本衍化史:
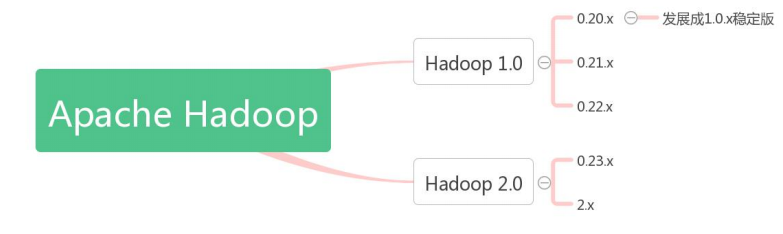
第一代 Hadoop 包含三个大版本,分别是 0.20.x,0.21.x 和 0.22.x,其中,0.20.x 最后演 化成 1.0.x,变成了稳定版。 第二代 Hadoop 包含两个版本,分别是 0.23.x 和 2.x,它们完全不同于 Hadoop 1.0,是 一套全新的架构,均包含 HDFS Federation 和 YARN 两个系统,相比于 0.23.x,2.x 增加了 NameNode HA 和 Wire-compatibility 两个重大特性。

Hadoop 遵从 Apache 开源协议,用户可以免费地任意使用和修改 Hadoop,也正因此, 市面上出现了很多 Hadoop 版本,其中比较出名的一是 Cloudera 公司的发行版,该版本称为 CDH(Cloudera Distribution Hadoop)。 截至目前为止,CDH 共有 4 个版本,其中,前两个已经不再更新,最近的两个,分别是 CDH3(在 Apache Hadoop 0.20.2 版本基础上演化而来的)和 CDH4 在 Apache Hadoop 2.0.0 版本基础上演化而来的),分别对应 Apache 的 Hadoop 1.0 和 Hadoop 2.0。
2. Hadoop 生态圈
架构师和开发人员通常会使用一种软件工具,用于其特定的用途软件开发。例如,他们 可能会说,Tomcat 是 Apache Web 服务器,MySQL 是一个数据库工具。 然而,当提到 Hadoop 的时候,事情变得有点复杂。Hadoop 包括大量的工具,用来协 同工作。因此,Hadoop 可用于完成许多事情,以至于,人们常常根据他们使用的方式来定 义它。 对于一些人来说,Hadoop 是一个数据管理系统。他们认为 Hadoop 是数据分析的核心, 汇集了结构化和非结构化的数据,这些数据分布在传统的企业数据栈的每一层。对于其他人, Hadoop 是一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行。 还有一些人认为 Hadoop 作为一个开源社区,主要为解决大数据的问题提供工具和软件。因 为 Hadoop 可以用来解决很多问题,所以很多人认为 Hadoop 是一个基本框架。 虽然 Hadoop 提供了这么多的功能,但是仍然应该把它归类为多个组件组成的 Hadoop 生态圈,这些组件包括数据存储、数据集成、数据处理和其它进行数据分析的专门工具。
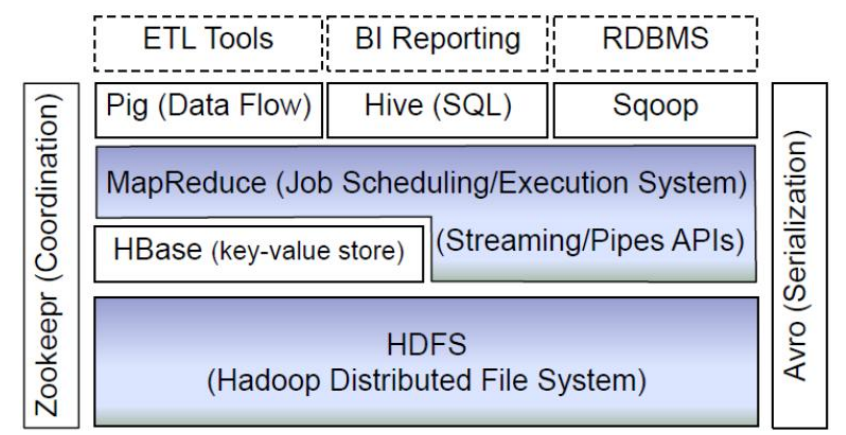
该图主要列举了生态圈内部主要的一些组件,从底部开始进行介绍:
1) HDFS:
Hadoop 生态圈的基本组成部分是 Hadoop 分布式文件系统(HDFS)。HDFS 是一 种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS 为 HBase 等工具提供了基础。
2) MapReduce:
Hadoop 的主要执行框架是 MapReduce,它是一个分布式、并行处理的编 程模型。MapReduce 把任务分为 map(映射)阶段和 reduce(化简)。开发人员使用存储在 HDFS 中数据(可实现快速存储),编写 Hadoop 的 MapReduce 任务。由于 MapReduce 工作原理的特性, Hadoop 能以并行的方式访问数据,从而实现快速访问数据。
3) Hbase:
HBase 是一个建立在 HDFS 之上,面向列的 NoSQL 数据库,用于快速读/写大量 数据。HBase 使用 Zookeeper 进行管理,确保所有组件都正常运行。
4) ZooKeeper:
用于 Hadoop 的分布式协调服务。Hadoop 的许多组件依赖于 Zookeeper, 它运行在计算机集群上面,用于管理 Hadoop 操作。
5) Hive:
Hive 类似于 SQL 高级语言,用于运行存储在 Hadoop 上的查询语句,Hive 让不熟 悉 MapReduce 开发人员也能编写数据查询语句,然后这些语句被翻译为 Hadoop 上面 的 MapReduce 任务。像 Pig 一样,Hive 作为一个抽象层工具,吸引了很多熟悉 SQL 而 不是 Java 编程的数据分析师。
6) Pig:
它是 MapReduce 编程的复杂性的抽象。Pig 平台包括运行环境和用于分析 Hadoop 数据集的脚本语言(Pig Latin)。其编译器将 Pig Latin 翻译成 MapReduce 程序序列。
7) Sqoop:
是一个连接工具,用于在关系数据库、数据仓库和 Hadoop 之间转移数据。Sqoop 利用数据库技术描述架构,进行数据的导入/导出;利用 MapReduce 实现并行化运行和 容错技术。
hadoop(一)hadoop简介的更多相关文章
- Hadoop开发环境简介(转)
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- 【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型
忘的差不多了, 先补概念, 然后开始搭建集群实战 ... . 一 Hadoop版本 和 生态圈 1. Hadoop版本 (1) Apache Hadoop版本介绍 Apache的开源项目开发流程 : ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
- [Linux][Hadoop] 将hadoop跑起来
前面安装过程待补充,安装完成hadoop安装之后,开始执行相关命令,让hadoop跑起来 使用命令启动所有服务: hadoop@ubuntu:/usr/local/gz/hadoop-$ ./sb ...
- Hadoop:搭建hadoop集群
操作系统环境准备: 准备几台服务器(我这里是三台虚拟机): linux ubuntu 14.04 server x64(下载地址:http://releases.ubuntu.com/14.04.2/ ...
- [Hadoop 周边] Hadoop资料收集【转】
原文网址: http://www.iteblog.com/archives/851 最直接的学习参考网站当然是官网啦: http://hadoop.apache.org/ Hadoop http:// ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
随机推荐
- JZOJ 4735. 最小圈
Description 对于一张有向图,要你求图中最小圈的平均值最小是多少,即若一个圈经过k个节点,那么一个圈的平均值为圈上k条边权的和除以k,现要求其中的最小值 Input 第一行2个正整数,分别为 ...
- 浅谈MapReduce工作机制
1.MapTask工作机制 整个map阶段流程大体如上图所示.简单概述:input File通过getSplits被逻辑切分为多个split文件,通通过RecordReader(默认使用lineRec ...
- 笔记-python-变量作用域
笔记-python-变量作用域 1. python变量作用域和引用范围 1.1. 变量作用域 一般而言程序的变量并不是任何对象或在任何位置都可以访问的,访问权限决定于这个变量是在哪里赋 ...
- 信号量和互斥量C语言示例理解线程同步
Table of Contents 1. 线程同步 1.1. 用信号量进行同步 1.2. 用互斥量进行同步 2. 参考资料 线程同步 了解线程信号量的基础知识,对深入理解python的线程会大有帮助. ...
- Unity 与Mono和.Net的关系
一.分析 首先,我们要知道Unity,Mono,.Net 三者的关系.需要简单说一下.Net. .Net拥有跨语言,跨平台性. 跨语言:就是只要是面向.Net平台的编程语言,用其中一种语言编写的类型就 ...
- 4 Template层-验证码
1.验证码 在用户注册.登录页面,为了防止暴力请求,可以加入验证码功能,如果验证码错误,则不需要继续处理,可以减轻一些服务器的压力 使用验证码也是一种有效的防止crsf的方法 验证码效果如下图: 官网 ...
- POJ 3041 Asteroids (二分图最小点覆盖集)
Asteroids Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 24789 Accepted: 13439 Descr ...
- loj2051 「HNOI2016」序列
ref #include <algorithm> #include <iostream> #include <cstdio> #include <cmath& ...
- Redis 配置登录密码
1. 通过配置文件进行配置 打开 redis.conf,找到 #requirepass foobared 去掉行前的注释,并修改密码为所需的密码,保存文件 重启redis sudo service r ...
- Python爬虫作业
题目如下: 请分析作业页面(https://edu.cnblogs.com/campus/hbu/Python2018Fall/homework/2420), 爬取已提交作业信息,并生成已提 ...