hadoop(一)hadoop简介
1. Hadoop 版本衍化历史
Hadoop 是一个由 Apache 基金会所开发的开源分布式系统基础架构。用户可以在不了解 分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。解 决了大数据(大到一台计算机无法进行存储,一台计算机无法在要求的时间内进行处理)的 可靠存储和处理。适合处理非结构化数据,包括 HDFS,MapReduce 基本组件。
1. Hadoop 版本衍化历史 由于 Hadoop 版本混乱多变对初级用户造成一定困扰,所以对其版本衍化历史有个大概 了解,有助于在实践过程中选择合适的 Hadoop 版本。 Apache Hadoop 版本分为分为 1.0 和 2.0 两代版本,我们将第一代 Hadoop 称为 Hadoop 1.0,第二代 Hadoop 称为 Hadoop 2.0。下图是 Apache Hadoop的版本衍化史:
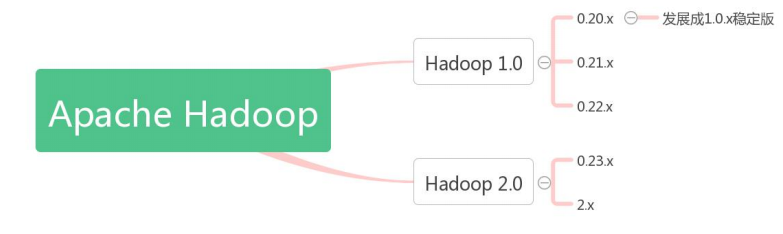
第一代 Hadoop 包含三个大版本,分别是 0.20.x,0.21.x 和 0.22.x,其中,0.20.x 最后演 化成 1.0.x,变成了稳定版。 第二代 Hadoop 包含两个版本,分别是 0.23.x 和 2.x,它们完全不同于 Hadoop 1.0,是 一套全新的架构,均包含 HDFS Federation 和 YARN 两个系统,相比于 0.23.x,2.x 增加了 NameNode HA 和 Wire-compatibility 两个重大特性。

Hadoop 遵从 Apache 开源协议,用户可以免费地任意使用和修改 Hadoop,也正因此, 市面上出现了很多 Hadoop 版本,其中比较出名的一是 Cloudera 公司的发行版,该版本称为 CDH(Cloudera Distribution Hadoop)。 截至目前为止,CDH 共有 4 个版本,其中,前两个已经不再更新,最近的两个,分别是 CDH3(在 Apache Hadoop 0.20.2 版本基础上演化而来的)和 CDH4 在 Apache Hadoop 2.0.0 版本基础上演化而来的),分别对应 Apache 的 Hadoop 1.0 和 Hadoop 2.0。
2. Hadoop 生态圈
架构师和开发人员通常会使用一种软件工具,用于其特定的用途软件开发。例如,他们 可能会说,Tomcat 是 Apache Web 服务器,MySQL 是一个数据库工具。 然而,当提到 Hadoop 的时候,事情变得有点复杂。Hadoop 包括大量的工具,用来协 同工作。因此,Hadoop 可用于完成许多事情,以至于,人们常常根据他们使用的方式来定 义它。 对于一些人来说,Hadoop 是一个数据管理系统。他们认为 Hadoop 是数据分析的核心, 汇集了结构化和非结构化的数据,这些数据分布在传统的企业数据栈的每一层。对于其他人, Hadoop 是一个大规模并行处理框架,拥有超级计算能力,定位于推动企业级应用的执行。 还有一些人认为 Hadoop 作为一个开源社区,主要为解决大数据的问题提供工具和软件。因 为 Hadoop 可以用来解决很多问题,所以很多人认为 Hadoop 是一个基本框架。 虽然 Hadoop 提供了这么多的功能,但是仍然应该把它归类为多个组件组成的 Hadoop 生态圈,这些组件包括数据存储、数据集成、数据处理和其它进行数据分析的专门工具。
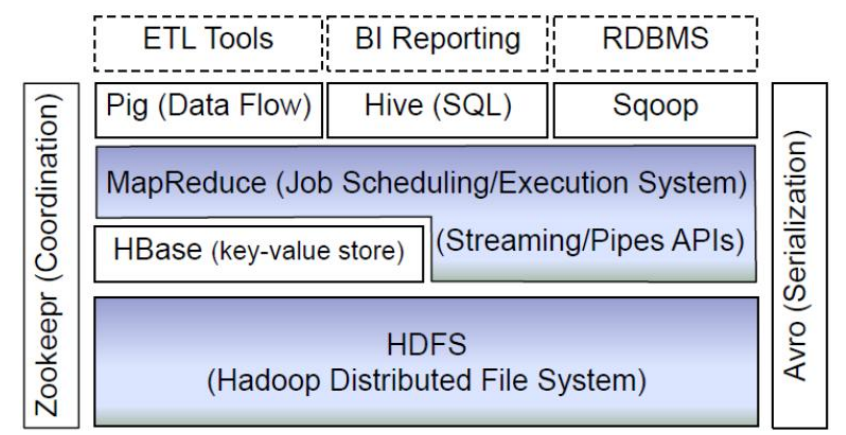
该图主要列举了生态圈内部主要的一些组件,从底部开始进行介绍:
1) HDFS:
Hadoop 生态圈的基本组成部分是 Hadoop 分布式文件系统(HDFS)。HDFS 是一 种数据分布式保存机制,数据被保存在计算机集群上。数据写入一次,读取多次。HDFS 为 HBase 等工具提供了基础。
2) MapReduce:
Hadoop 的主要执行框架是 MapReduce,它是一个分布式、并行处理的编 程模型。MapReduce 把任务分为 map(映射)阶段和 reduce(化简)。开发人员使用存储在 HDFS 中数据(可实现快速存储),编写 Hadoop 的 MapReduce 任务。由于 MapReduce 工作原理的特性, Hadoop 能以并行的方式访问数据,从而实现快速访问数据。
3) Hbase:
HBase 是一个建立在 HDFS 之上,面向列的 NoSQL 数据库,用于快速读/写大量 数据。HBase 使用 Zookeeper 进行管理,确保所有组件都正常运行。
4) ZooKeeper:
用于 Hadoop 的分布式协调服务。Hadoop 的许多组件依赖于 Zookeeper, 它运行在计算机集群上面,用于管理 Hadoop 操作。
5) Hive:
Hive 类似于 SQL 高级语言,用于运行存储在 Hadoop 上的查询语句,Hive 让不熟 悉 MapReduce 开发人员也能编写数据查询语句,然后这些语句被翻译为 Hadoop 上面 的 MapReduce 任务。像 Pig 一样,Hive 作为一个抽象层工具,吸引了很多熟悉 SQL 而 不是 Java 编程的数据分析师。
6) Pig:
它是 MapReduce 编程的复杂性的抽象。Pig 平台包括运行环境和用于分析 Hadoop 数据集的脚本语言(Pig Latin)。其编译器将 Pig Latin 翻译成 MapReduce 程序序列。
7) Sqoop:
是一个连接工具,用于在关系数据库、数据仓库和 Hadoop 之间转移数据。Sqoop 利用数据库技术描述架构,进行数据的导入/导出;利用 MapReduce 实现并行化运行和 容错技术。
hadoop(一)hadoop简介的更多相关文章
- Hadoop开发环境简介(转)
1.Hadoop开发环境简介 1.1 Hadoop集群简介 Java版本:jdk-6u31-linux-i586.bin Linux系统:CentOS6.0 Hadoop版本:hadoop-1.0.0 ...
- 【云计算 Hadoop】Hadoop 版本 生态圈 MapReduce模型
忘的差不多了, 先补概念, 然后开始搭建集群实战 ... . 一 Hadoop版本 和 生态圈 1. Hadoop版本 (1) Apache Hadoop版本介绍 Apache的开源项目开发流程 : ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- Hadoop: Hadoop Cluster配置文件
Hadoop配置文件 Hadoop的配置文件: 只读的默认配置文件:core-default.xml, hdfs-default.xml, yarn-default.xml 和 mapred-defa ...
- [Linux][Hadoop] 将hadoop跑起来
前面安装过程待补充,安装完成hadoop安装之后,开始执行相关命令,让hadoop跑起来 使用命令启动所有服务: hadoop@ubuntu:/usr/local/gz/hadoop-$ ./sb ...
- Hadoop:搭建hadoop集群
操作系统环境准备: 准备几台服务器(我这里是三台虚拟机): linux ubuntu 14.04 server x64(下载地址:http://releases.ubuntu.com/14.04.2/ ...
- [Hadoop 周边] Hadoop资料收集【转】
原文网址: http://www.iteblog.com/archives/851 最直接的学习参考网站当然是官网啦: http://hadoop.apache.org/ Hadoop http:// ...
- [Hadoop 周边] Hadoop和大数据:60款顶级大数据开源工具(2015-10-27)【转】
说到处理大数据的工具,普通的开源解决方案(尤其是Apache Hadoop)堪称中流砥柱.弗雷斯特调研公司的分析师Mike Gualtieri最近预测,在接下来几年,“100%的大公司”会采用Hado ...
- hadoop数据[Hadoop] 实际应用场景之 - 阿里
上班之余抽点时间出来写写博文,希望对新接触的朋友有帮助.明天在这里和大家一起学习一下hadoop数据 Hadoop在淘宝和支付宝的应用从09年开始,用于对海量数据的离线处置,例如对日志的分析,也涉及内 ...
- Hadoop:Hadoop单机伪分布式的安装和配置
http://blog.csdn.net/pipisorry/article/details/51623195 因为lz的linux系统已经安装好了很多开发环境,可能下面的步骤有遗漏. 之前是在doc ...
随机推荐
- C语言分步编译
在进行C语言源码至可执行程序的整个过程中,整个形成过程可以分为四步: 1.预处理 gcc -E hello.c -o hello.i 目的: (1)宏定义展开 (2)头文件展开 (3)条件编译 (4) ...
- visual studio cl -d1reportSingleClassLayout查看内存f分布
C:\Users\Administrator\Desktop\cppsrc>cl -d1reportSingleClassLayoutTeacher virtual.cpp 用于 x86 的 M ...
- 动态规划:HDU1003-Max Sum(最大子序列和)
Max Sum Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Su ...
- 水题:HDU1034-Candy Sharing Game
解题心得: 1.我是用的模拟的算法直接模拟的每一轮的分配方法的得出的答案,看到有些大神使用的链表做的,好像链表才是这道题的镇长的做法吧. 题目: Candy Sharing Game Time Lim ...
- Spring加载配置文件的几种方法(org.springframework.beans.factory.BeanDefinitionStoreException)
一:Spring中的几种容器都支持使用xml装配bean,包括:XmlBeanFactory ,ClassPathXmlApplicationContext ,FileSystemXmlApplica ...
- Python中函数参数类型和参数绑定
参数类型 Python函数的参数类型一共有五种,分别是: POSITIONAL_OR_KEYWORD(位置参数或关键字参数) VAR_POSITIONAL(可变参数) KEYWORD_ONLY(关键字 ...
- Js中的undefined和not defined
1.undefined 已经声明,但未赋值 2.not defined 未声明,报错
- leetcode 【 Add Two Numbers 】 python 实现
题目: You are given two linked lists representing two non-negative numbers. The digits are stored in r ...
- Linux 基础命令、文档树 和 bash
最近发现了一个总结得更好的:bash cheatsheet 本文只是我对 linux 基础学习的一个总结,可能仅适用于复习用.算是我的 Linux 备忘录. 最基础 tab 补全 * 通配符 ctrl ...
- [oldboy-django][2深入django]xss攻击 + csrf
1 xss攻击 xss攻击(跨站脚本攻击,用户页面提交数据来盗取cookie) - 慎用safe, 和mark_safe -- 如果要用,必须要过滤 - 定义: 用户提交内容,在页面展示用html显示 ...