对需要聚类的数据使用canopy做初步的计算
K值聚类的时候,需要自己指定cluster的数目。
这个cluster数目一般是通过canopy算法进行预处理来确定的。
canopy具体描述可以参考这里。
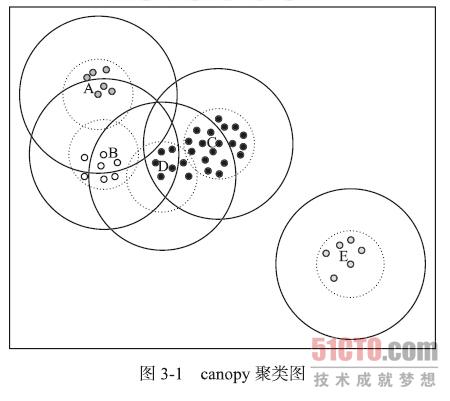
下面是 golang语言的一个实现(对经纬度距离计算进行cluster)。
package main import (
"fmt"
"math"
) const (
EARTH_RADIUS =
) type Point struct {
lat float64
lng float64
} func Pop(points []Point) (p Point, newPoints []Point) {
if len(points) > {
p = points[]
newPoints = points[:]
}
return
} func Push(p Point, points []Point) []Point {
points = append(points, p)
return points
} // Calculates the Haversine distance between two points in kilometers.
// Original Implementation from: http://www.movable-type.co.uk/scripts/latlong.html
func GreatCircleDistance(p1, p2 Point) float64 {
dLat := (p2.lat - p1.lat) * (math.Pi / 180.0)
dLon := (p2.lng - p1.lng) * (math.Pi / 180.0) lat1 := p1.lat * (math.Pi / 180.0)
lat2 := p2.lat * (math.Pi / 180.0) a1 := math.Sin(dLat/) * math.Sin(dLat/)
a2 := math.Sin(dLon/) * math.Sin(dLon/) * math.Cos(lat1) * math.Cos(lat2) a := a1 + a2 c := * math.Atan2(math.Sqrt(a), math.Sqrt(-a))
return EARTH_RADIUS * c
} /*
while(没有标记的数据点){
选择一个没有强标记的数据点p
把p看作一个新Canopy c的中心
离p距离<x1的所有点都认为在c中,给这些点做上弱标记 //纳入canopy,有可能会纳入其它canopy
离p距离<x2的所有点都认为在c中,给这些点做上强标记 //不会再纳入其它canopy
}
*/ //目前只实现了经纬度以及经纬度的距离计算,这里可以是一个向量
func CanopyCluster(points []Point, x1, x2 float64) {
var tmp []Point
var cluster [][]Point for len(points) > {
var center Point
center, points = Pop(points)
index := len(cluster)
var cpList []Point
cpList = append(cpList, center)
cluster = append(cluster, cpList)
var cur Point
for len(points) > {
cur, points = Pop(points)
distance := GreatCircleDistance(center, cur)
if distance <= x1 {
cluster[index] = append(cluster[index], cur)
if distance > x2 {
tmp = Push(cur, tmp)
}
} else {
tmp = Push(cur, tmp)
}
}
fmt.Printf("current number of items in this canopy %d\n", center)
var t []Point
points = tmp
tmp = t
}
for k, c := range cluster {
fmt.Println("canopy", k, "has", len(c), "items:")
for _, v := range c {
fmt.Println("\t", v.lat, v.lng)
}
}
} func main() {
pointsList := []Point{
{34.28637, -110.12059},
{34.28638, -110.1206},
{34.29077, -110.12078},
{34.29111, -110.11941},
{34.29113, -110.11938},
{34.29116, -110.1194},
{34.29145, -110.12043},
{34.29146, -110.12063},
{34.29154, -110.11873},
{34.3141, -110.11556},
{34.31411, -110.11557},
{34.31411, -110.11556},
{34.31412, -110.11556},
{34.31412, -110.11557},
{34.31415, -110.11552},
{34.31415, -110.11556},
}
CanopyCluster(pointsList, 1.0, 0.8)
}
对需要聚类的数据使用canopy做初步的计算的更多相关文章
- 抓取摩拜单车API数据,并做可视化分析
抓取摩拜单车API数据,并做可视化分析 纵聊天下 百家号|04-19 15:16 关注 警告:此篇文章仅作为学习研究参考用途,请不要用于非法目的. 摩拜是最早进入成都的共享单车,每天我从地铁站下来的时 ...
- 领导满意,客户喜欢的数据报表怎么做,交给Smartbi!
财务分析是以会计核算和报表资料及其他相关资料为依据,采用一系列专门的分析技术和方法,对企业等经济组织过去和现在有关筹资活动.投资活动.经营活动.分配活动的盈利能力.营运能力.偿债能力和增长能力状况等进 ...
- 从 Hadoop 到云原生, 大数据平台如何做存算分离
Hadoop 的诞生改变了企业对数据的存储.处理和分析的过程,加速了大数据的发展,受到广泛的应用,给整个行业带来了变革意义的改变:随着云计算时代的到来, 存算分离的架构受到青睐,企业开开始对 Hado ...
- Java中浮点型数据Float和Double进行精确计算的问题
Java中浮点型数据Float和Double进行精确计算的问题 来源 https://www.cnblogs.com/banxian/p/3781130.html 一.浮点计算中发生精度丢失 ...
- 斯坦福机器学习视频笔记 Week8 无监督学习:聚类与数据降维 Clusting & Dimensionality Reduction
监督学习算法需要标记的样本(x,y),但是无监督学习算法只需要input(x). 您将了解聚类 - 用于市场分割,文本摘要,以及许多其他应用程序. Principal Components Analy ...
- 关于淘宝的数据来源,针对做淘宝客网站的淘宝api调用方法
上次写了个淘宝返利模式的博客,直接被移除首页,不知道何故啊.可能是真的跟技术不太刮边. 众所周知,能够支撑一个网站运营的最基础不是程序写的多么好.也不是有多么牛X的运营人员,最主要的是数据,如果没有数 ...
- 基于Kafka Connect框架DataPipeline在实时数据集成上做了哪些提升?
在不断满足当前企业客户数据集成需求的同时,DataPipeline也基于Kafka Connect 框架做了很多非常重要的提升. 1. 系统架构层面. DataPipeline引入DataPipeli ...
- 单细胞数据高级分析之初步降维和聚类 | Dimensionality reduction | Clustering
个人的一些碎碎念: 聚类,直觉就能想到kmeans聚类,另外还有一个hierarchical clustering,但是单细胞里面都用得不多,为什么?印象中只有一个scoring model是用kme ...
- freemarker 数据做加减计算
controller的部分: @Controller@RequestMapping("/ContactsFrameIndex")public class ContactsFrame ...
随机推荐
- 每日学习心得:SharePoint 2013 自定义列表项添加Callout菜单项、文档关注、SharePoint服务端对象模型查询
前言: 前一段时间一直都比较忙,没有什么时间进行总结,刚好节前项目上线,同时趁着放假可以好好的对之前遇到的一些问题进行总结.主要内容有使用SharePoint服务端对象模型进行查询.为SharePoi ...
- winform里dataGridView分页代码,access数据库
winform里dataGridView分页,默认dataGridView是不分页的和webform里不一样,webform中GridView自带自带了分页. 现在c/s的程序很多时候也需要webfo ...
- 【mysql元数据库】使用information_schema.tables查询数据库和数据表信息
概述 对于mysql和Infobright等数据库,information_schema数据库中的表都是只读的,不能进行更新.删除和插入等操作,也不能加触发器,因为它们实际只是一个视图,不是基本表,没 ...
- [家里蹲大学数学杂志]第049期2011年广州偏微分方程暑期班试题---随机PDE-可压NS-几何
随机偏微分方程 Throughout this section, let $(\Omega, \calF, \calF_t,\ P)$ be a complete filtered probabili ...
- rsync+sersync实现文件实时同步
前言: 一.为什么要用Rsync+sersync架构? 1.sersync是基于Inotify开发的,类似于Inotify-tools的工具 2.sersync可以记录下被监听目录中发生变化的(包括增 ...
- CSS3图片缩放
鼠标指上去,图片放大,鼠标离开图片恢复原样,并且有放大.缩小效果 Css代码实现:
- oracle的char和varchar类型
源地址:https://zhidao.baidu.com/question/140310197.html varchar与char的区别就在于是否可变长度.char(5)就是定义一个5个字符长度的字符 ...
- MYSQL C API : mysql_real_escape_string 二进制数据存储
#include <iostream> #include <string> #include <string.h> #include <mysql.h> ...
- maven部署tomcat项目,403错误解决
maven部署tomcat项目时403错误的解决方法 web模块的pom文件 pom.xml <plugin> <groupId>org.apache.tomcat.maven ...
- Symfony2 资料篇
http://www.chrisyue.com/symfony2-in-action-day-1.html 由于Symfony2现在还没有很完善的中文文档,所以不想看文档的同学可以直接进行点击上面的链 ...