大数据自学6-Hue集成环境操作Hbase
上一章讲过,Hue集成环境是可以直接操作Hbase,但是公司的环境一直报错,虽然也可以透过写代码访问Hbase,但是看到Hue环境中无法访问,还是觉得不爽,因此决定再花些力气找找原因。
找原因要先查Log,百度里查Hue Log,发现以管理员身份登入Hue,点击About是可以看到Log的,同时还有更惊奇的发现,About的第一步就是自检(Check Configuration),如下图,会将配置错误的部分列出来
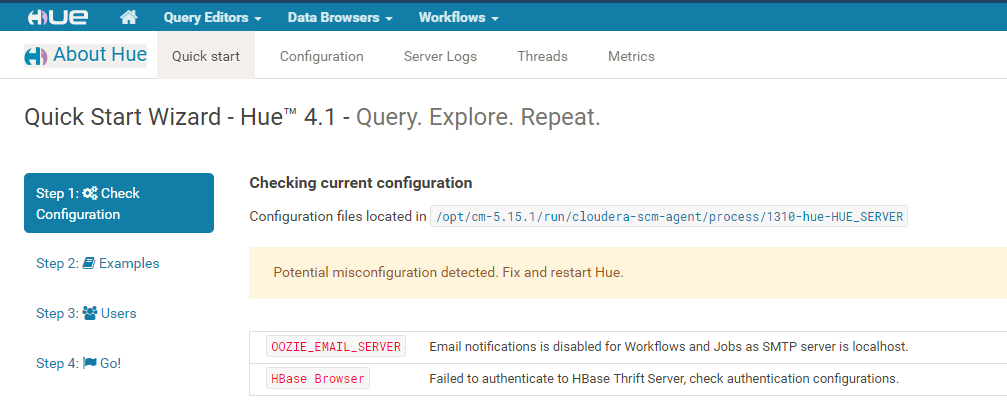
看到这里就明白了为什么在Hue 里Hbase Browser一直在转圈圈跑不出来,原因配置有误 。
按此错误信息找,在StackOverflow里有一个贴子讲到,是几个配置项的问题
hbase.regionserver.thrift.http = true
hbase.thrift.support.proxyuser = true
hbase.thrift.security.qop = auth
但是没有讲清楚,也有说只要将hbase.thrift.support.proxyuser设为false
按照上面的说法,在Hbase配置项里配置hbase.regionserver.thrift.http = true,hbase.thrift.support.proxyuser = true,hbase.thrift.security.qop = auth,重启HBase服务,再次进入Hue的Hbase Browser功能,发现还是报错,提示:

点击Hue About进行配置自检提示,才发现这样配置后Thrift Server根本就无法启动。

尝试将配置项配置hbase.thrift.security.qop改回之前的设置,hbase.regionserver.thrift.http = true,hbase.thrift.support.proxyuser = true这两项配置不变,重启HBase服务,发现Hbase Browser又报另一个错了”TSocket read 0 bytes“

我把Hue服务也重启了,结果还是提示Api Error,只是后面没有具体的错误信息,只能在Log里找原因了,查Log后再在网上找,发现有个人跟我碰到同样的问题,且有解决方法,参考链接:https://yq.aliyun.com/ask/238832,我按照其中一位网友的回复中操作,在
hue_safety_valve.ini 的 Hue 服务高级配置代码段(安全阀)这个栏目里配置以下值:
[hbase]
hbase_conf_dir={{HBASE_CONF_DIR}}
thrift_transport=buffered
重启Hbase和Hue,发现还是报错,这次看Log,提示“hbase is not allowed to impersonate ***".
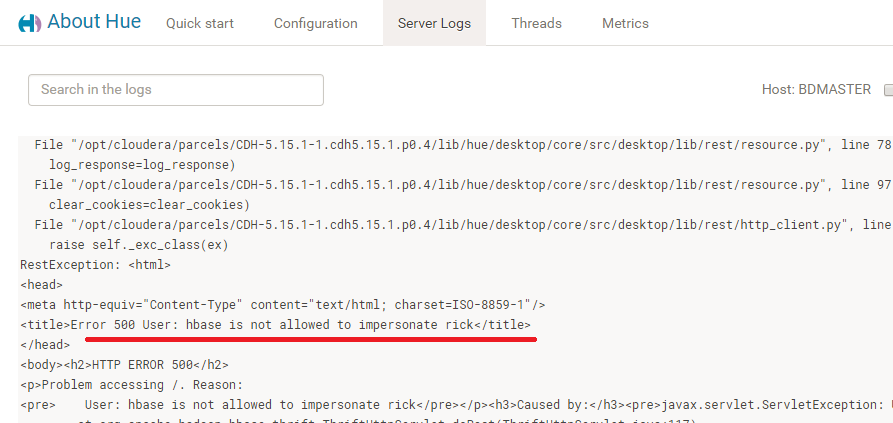
关于这个impersonate,查了很多资料 ,觉得http://hotcodeshare.com/node/81这个说得最好,按其步骤操作,要重启HDFS服务。
大数据自学6-Hue集成环境操作Hbase的更多相关文章
- 大数据自学2-Hue集成环境中使用Sqoop组件从Sql Server导数据到Hive/HDFS
安装完CDH后,发现里面的东东实在是太多了,对于一个初学大数据的来说就犹如刘姥姥进了大观园,很新奇,这些东东每个单拿出来都够喝一壶的. 接来来就是一步一步地学习了,先大致学习了每个模组大致做什么用的, ...
- 大数据自学5-Python操作Hbase
在Hue环境中本身是可以直接操作Hbase数据库的,但是公司的环境不知道什么原因一直提示"Api Error:timed out",进度条一直在跑,却显示不出表. 但是在CDH后台 ...
- 大数据技术之_11_HBase学习_01_HBase 简介+HBase 安装+HBase Shell 操作+HBase 数据结构+HBase 原理
第1章 HBase 简介1.1 什么是 HBase1.2 HBase 特点1.3 HBase 架构1.3 HBase 中的角色1.3.1 HMaster1.3.2 RegionServer1.3.3 ...
- 零基础入门到精通:Python大数据与机器学习之Pandas-数据操作
在这里还是要推荐下我自己建的Python开发学习群:483546416,群里都是学Python开发的,如果你正在学习Python ,小编欢迎你加入,大家都是软件开发党,不定期分享干货(只有Python ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据自学4-Hue集成环境中各模组说明
前面已经学习了如何将数据从关系型数据库导入到Hive/HDFS,并且在Windows客户端查询导入的数据,接下来继续学习CDH,知识点: 1.Hue环境中DB Query如何使用,DB Query这个 ...
- 《OD大数据实战》Hue环境搭建
官网: http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-cdh5.3.6/ 一.Hue环境搭建 1. 下载 http://archive.cloude ...
- 大数据自学3-Windows客户端DbVisualizer/SQuirreL配置连接hive
前面已经学习了将数据从Sql Server导入到Hive DB,并在Hue的Web界面可以查询,接下来是配置客户端工具直接连Hive数据库,常用的有DbVisualizer.SQuirreL SQL ...
- 大数据高可用集群环境安装与配置(08)——安装Ganglia监控集群
1. 安装依赖包和软件 在所有服务器上输入命令进行安装操作 yum install epel-release -y yum install ganglia-web ganglia-gmetad gan ...
随机推荐
- Python基础-编码与解码
一.什么是编码 编码是指信息从一种形式或格式转换为另一种形式或格式的过程. 在计算机中,编码,简而言之,就是将人能够读懂的信息(通常称为明文)转换为计算机能够读懂的信息.众所周知,计算机能够读懂的 ...
- Kinect2.0获取数据
最近事情真是多,今天抽空研究一下Kinec2.0的数据获取! 系统要求 https://developer.microsoft.com/en-us/windows/kinect/hardware-se ...
- NgDL:【第二周】NN基础
1.计算图的导数计算 正向比如说是计算代价函数值,反向就是增大多少a/b/c对J的影响,也就是导数的意义,这里讲的是求导链式法则. 2.向量化 节约大量计算时间 简直是100倍的时间,看来之前实现的那 ...
- CentOS6.5安装Kibana5.3.0
1.写在安装之前,安装Kibana之前需要先安装Elasticsearch,为了安装时不出错,建议选择这两者选择一样的版本,本文全部选择5.3版本. 2.首先到官网下载安装包: https://art ...
- tcpdump 选项及过滤规则
tcpdump tcp -i eth1 -t -s 0 -c 100 and dst port ! 22 and src net 192.168.1.0/24 -w ./target.cap (1)t ...
- iOS应用图标及尺寸
Icon and Image Sizes Every app needs an app icon and a launch file or image. In addition, some apps ...
- IDEA2017及DataGrip2017注册码
访问http://idea.lanyus.com/,网页中有相关说明,最简单的方式是将“0.0.0.0 account.jetbrains.com”添加到hosts文件中,然后点击页面底部的“获得注册 ...
- Asp.netCore之安装centos7 资料收集
虚拟机的安装和centos的安装看博友的文章:https://www.cnblogs.com/zhaopei/p/netcore.html ifconfig 在centons中用终端写命令比较费劲,可 ...
- JAVA8方法引用
方法引用:若Lambda方法体已经实现,我们可以使用方法引用* 主要有三种语法格式:* 对象::实例方法名* 类::实例方法名* 类::静态方法名** 注意:Lambda体中调用的方法的参数列表与返回 ...
- DataGridView控件用法二:常用属性
通常会设置的DataGridView的属性如下: AllowUserToAddRows - False指示是否向用户显示用于添加行的选项,列标题下面的一行空行将消失.一般让其消失.AllowUserT ...