DQN-深度Q网络
深度Q网络是用深度学习来解决强化中Q学习的问题,可以先了解一下Q学习的过程是一个怎样的过程,实际上就是不断的试错,从试错的经验之中寻找最优解
关于Q学习,我看到一个非常好的例子,另外知乎上面也有相关的讨论
其实早在13年的时候,deepmind出来了第一篇用深度学习来解决Q学习的问题的paper,那个时候deepmind还不够火,和一般的Q学习不同的是,由于12年Alex率先用CNN解决图像中的high level的语义的提取,deepmind也同时采用了CNN来直接对图像进行特征提取,而非传统的进行手工特征提取
我想从代码的角度来看一下DQN是如何实现的
pytorcyh的代码在官网上是有的,我也贴出了自己添加了注释的代码,以及写一下自己的对于代码的理解
# -*-coding:utf-8-*-
import gym
import math
import random
import numpy as np
import matplotlib
import matplotlib.pyplot as plt
from collections import namedtuple
from itertools import count
from PIL import Image import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import torchvision.transforms as T env = gym.make('CartPole-v0').unwrapped # set up matplotlib
is_ipython = 'inline' in matplotlib.get_backend()
if is_ipython:
from IPython import display plt.ion() # if gpu is to be used
# device = torch.device("cuda" if torch.cuda.is_available() else "cpu") Transition = namedtuple('Transition',
('state', 'action', 'next_state', 'reward')) # 声明一个name为Transition,里面的变量为以下的类似dict的 class ReplayMemory(object): def __init__(self, capacity):
self.capacity = capacity
self.memory = []
self.position = 0 def push(self, *args):
"""Saves a transition."""
if len(self.memory) < self.capacity:
self.memory.append(None)
self.memory[self.position] = Transition(*args)
self.position = (self.position + 1) % self.capacity def sample(self, batch_size):
return random.sample(self.memory, batch_size) def __len__(self): # 定义__len__以便于用len函数?
return len(self.memory) class DQN(nn.Module): def __init__(self):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 32, kernel_size=5, stride=2)
self.bn3 = nn.BatchNorm2d(32)
self.head = nn.Linear(448, 2) def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
return self.head(x.view(x.size(0), -1)) resize = T.Compose([T.ToPILImage(),
T.Resize(40, interpolation=Image.CUBIC),
T.ToTensor()]) # This is based on the code from gym.
screen_width = 600 def get_cart_location():
world_width = env.x_threshold * 2
scale = screen_width / world_width
return int(env.state[0] * scale + screen_width / 2.0) # MIDDLE OF CART def get_screen():
screen = env.render(mode='rgb_array').transpose(
(2, 0, 1)) # transpose into torch order (CHW)
# Strip off the top and bottom of the screen
screen = screen[:, 160:320]
view_width = 320
cart_location = get_cart_location()
if cart_location < view_width // 2:
slice_range = slice(view_width)
elif cart_location > (screen_width - view_width // 2):
slice_range = slice(-view_width, None)
else:
slice_range = slice(cart_location - view_width // 2,
cart_location + view_width // 2)
# Strip off the edges, so that we have a square image centered on a cart
screen = screen[:, :, slice_range]
# Convert to float, rescare, convert to torch tensor
# (this doesn't require a copy)
screen = np.ascontiguousarray(screen, dtype=np.float32) / 255
screen = torch.from_numpy(screen)
# Resize, and add a batch dimension (BCHW)
return resize(screen).unsqueeze(0).cuda() env.reset()
# plt.figure()
# plt.imshow(get_screen().cpu().squeeze(0).permute(1, 2, 0).numpy(),
# interpolation='none')
# plt.title('Example extracted screen')
# plt.show()
BATCH_SIZE = 128
GAMMA = 0.999
EPS_START = 0.9
EPS_END = 0.05
EPS_DECAY = 200
TARGET_UPDATE = 10 policy_net = DQN().cuda()
target_net = DQN().cuda()
target_net.load_state_dict(policy_net.state_dict())
target_net.eval() optimizer = optim.RMSprop(policy_net.parameters())
memory = ReplayMemory(10000) steps_done = 0 def select_action(state):
global steps_done
sample = random.random()
eps_threshold = EPS_END + (EPS_START - EPS_END) * \
math.exp(-1. * steps_done / EPS_DECAY)
steps_done += 1
if sample > eps_threshold:
with torch.no_grad():
return policy_net(state).max(1)[1].view(1, 1) # policy网络的输出
else:
return torch.tensor([[random.randrange(2)]], dtype=torch.long).cuda() # 随机的选择一个网络的输出或者 episode_durations = [] def plot_durations():
plt.figure(2)
plt.clf()
durations_t = torch.tensor(episode_durations, dtype=torch.float)
plt.title('Training...')
plt.xlabel('Episode')
plt.ylabel('Duration')
plt.plot(durations_t.numpy())
# Take 100 episode averages and plot them too
if len(durations_t) >= 100:
means = durations_t.unfold(0, 100, 1).mean(1).view(-1)
means = torch.cat((torch.zeros(99), means))
plt.plot(means.numpy()) plt.pause(0.001) # pause a bit so that plots are updated
if is_ipython:
display.clear_output(wait=True)
display.display(plt.gcf()) def optimize_model():
if len(memory) < BATCH_SIZE:
return
transitions = memory.sample(BATCH_SIZE) # 进行随机的sample,序列问题是不存在的
# print(transitions)
# Transpose the batch (see http://stackoverflow.com/a/19343/3343043 for
# detailed explanation).
batch = Transition(*zip(*transitions))
# print("current")
# print(batch.state[0])
# print("next")
# print(batch.next_state[0])
# print(torch.sum(batch.state[0]))
# print(torch.sum(batch.next_state[0]))
# print(torch.sum(batch.state[1]))
# # print(type(batch))
# print("@#$%^&*") # Compute a mask of non-final states and concatenate the batch elements
non_final_mask = torch.tensor(tuple(map(lambda s: s is not None, batch.next_state)), dtype=torch.uint8).cuda() # lambda表达式返回的是否为空的二值
non_final_next_states = torch.cat([s for s in batch.next_state if s is not None]) # 空的不cat,所以长度不一定是batchsize
# print("the non_final_mask is")
# print(non_final_mask)
# none_total = 0
# total = 0
# for s in batch.next_state:
# if s is None:
# none_total = none_total + 1
# else:
# total = total + 1
# print(none_total, total)
state_batch = torch.cat(batch.state)
action_batch = torch.cat(batch.action)
reward_batch = torch.cat(batch.reward)
# print(action_batch) # 非0即1
# print(reward_batch)
# print(len(non_final_mask))
# Compute Q(s_t, a) - the model computes Q(s_t), then we select the
# columns of actions taken
state_action_values = policy_net(state_batch).gather(1, action_batch) # gather将torch.tensor的中对应于action的index取出,dim为1
# 从整体公式上而言,Q函数的值即为state_action_value的值
# print((policy_net(state_batch)))
# print(state_action_values)
# Compute V(s_{t+1}) for all next states.
next_state_values = torch.zeros(BATCH_SIZE).cuda()
# print(next_state_values)
# print("no final mask")
# print(non_final_mask)
# print("@#$%^&*")
next_state_values[non_final_mask] = target_net(non_final_next_states).max(1)[0].detach() # non_final_mask为1的地方进行赋值操作,其余仍为0
# print(target_net(non_final_next_states).max(1)[0].detach())
# print("12345")
# print(next_state_values)
# Compute the expected Q values
expected_state_action_values = (next_state_values * GAMMA) + reward_batch # Compute Huber loss
loss = F.smooth_l1_loss(state_action_values, expected_state_action_values.unsqueeze(1)) # compare the parameters of 2 networks
print(policy_net.state_dict()['head.bias'])
print("!@#$%^&*")
print(target_net.state_dict()['head.bias']) # Optimize the model
optimizer.zero_grad()
loss.backward()
for param in policy_net.parameters():
param.grad.data.clamp_(-1, 1)
optimizer.step() num_episodes = 50
for i_episode in range(num_episodes):
# print("the episode is %f" % i_episode)
# Initialize the environment and state
env.reset()
last_screen = get_screen()
# print(last_screen)
# print("#QW&*!$")
current_screen = get_screen() # 得到一张图片,而非一个batch
# print(current_screen)
state = current_screen - last_screen # 两帧之间的差值,作为一个state,并且输入网络,类比于RNN对pose的估计
for t in count(): # 创建一个无限循环迭代器,t的数值会一直增加
# Select and perform an action
action = select_action(state)
_, reward, done, _ = env.step(action.item()) # done表示游戏是否结束, reward由gym内部决定;输入action,gym展示下一个状态
reward = torch.tensor([reward]).cuda() # Observe new state
last_screen = current_screen
current_screen = get_screen()
if not done:
next_state = current_screen - last_screen
else:
next_state = None # Store the transition in memory
memory.push(state, action, next_state, reward) # memory存储state,action,next_state,以及对应的reward
# print("the length of the memory is %d" % len(memory))
# Move to the next state
state = next_state # Perform one step of the optimization (on the target network)
optimize_model()
if done:
episode_durations.append(t + 1)
plot_durations()
break
# Update the target network
if i_episode % TARGET_UPDATE == 0: # 只有在某个频率下才会update target网络结构
target_net.load_state_dict(policy_net.state_dict()) print('Complete')
env.render()
env.close()
plt.ioff()
plt.show()
env.close()
作者调用了一个gym的库,这个库可以用作强化学习的训练样本,但是蛋疼的是,在用pycharm进行debug的时候,gym库总会报错,如果直接运行则不会,我想可能是因为gym库并不可以进行调试
anyway,代码的总体流程是,调用gym,声明一个事件,在强化学习中被称为agent,这个agent会展示当前的状态,然后会接收一个action,输出下一个的状态以及这个action所得到的奖励,ok,至于这个agent采取了action之后所得到的奖励是如何计算的,
这个agent采取了这个action下一个状态是啥,gym已经给你们写好了
在定义网络结构之前,作者实际上是把自己试错的状态存储了起来,存储的内容有,当前的state,采取action,以及nextstate,以及这个action相应的reward,而state并不是当前游戏的截屏,而是两帧之间的差值,reward是gym自己返回的
至于为什么这样做?有点儿类似与用RNN解决slam的问题,为什么输入到网络中的是视频两帧之间的差值,而不是视频自己本身的内容,要给自己挖个坑
存储了这些状态之后就可以训练网络了,主体的网络结构如下
class DQN(nn.Module):
def __init__(self):
super(DQN, self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=5, stride=2)
self.bn1 = nn.BatchNorm2d(16)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5, stride=2)
self.bn2 = nn.BatchNorm2d(32)
self.conv3 = nn.Conv2d(32, 32, kernel_size=5, stride=2)
self.bn3 = nn.BatchNorm2d(32)
self.head = nn.Linear(448, 2)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
return self.head(x.view(x.size(0), -1))
网络输出的两个值,分别是对应不同的action,其实也不难理解,训练的网络最终能够产生的输出当然是决策是怎样的,不过这种自己不断的试错,并且把自己试错的数据保存下来,严格意义上来说真的是无监督学习?
anyway,作者用这些试错的数据进行训练
不过,网络的loss怎么设计?
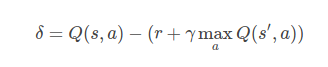
loss如上,实际上就是求取两个Q函数之间的差值,ok,前一个Q函数的自变量描述的是当前的状态s以及对应的行为a,后一个r+Q描述的是当前的reward加上,在下一个state如何采取下一步行动能够让Q最大的项
而这两项如何在代码中体现,实际上作者定义了两个网络,一个成为policy,另外一个为target网络
优化的目标是policy net,target网络为定期对policy的copy,如下
# Update the target network
if i_episode % TARGET_UPDATE == 0: # 只有在某个频率下才会update target网络结构
target_net.load_state_dict(policy_net.state_dict())
policy net输入state batch,并且将实际中的对应的action的那一列输出,action非0即1,所以policy_net输出的是batch_size的列向量
在这段代码中,这个网络的输出就是Q函数的值,
target_net网络输入的是next_state,并且因为不知道其实际的action是多少,所以取最大的,输出乘以一个gamma,并且加上当前状态的reward即可
其实永远是policy_net更新在前,更新的方向是让两个网络的输出尽可能的接近,其实也不仅仅是这样,这中间还有一个reward变量,可是为什么target_net的更新要永远滞后,一种更加极端的情况是,如果把next_state输入到policy网络中呢?
DQN-深度Q网络的更多相关文章
- 使用dlib中的深度残差网络(ResNet)实现实时人脸识别
opencv中提供的基于haar特征级联进行人脸检测的方法效果非常不好,本文使用dlib中提供的人脸检测方法(使用HOG特征或卷积神经网方法),并使用提供的深度残差网络(ResNet)实现实时人脸识别 ...
- 基于深度学习的安卓恶意应用检测----------android manfest.xml + run time opcode, use 深度置信网络(DBN)
基于深度学习的安卓恶意应用检测 from:http://www.xml-data.org/JSJYY/2017-6-1650.htm 苏志达, 祝跃飞, 刘龙 摘要: 针对传统安卓恶意程序检测 ...
- Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.3
Spark MLlib Deep Learning Deep Belief Network (深度学习-深度信念网络)2.3 http://blog.csdn.net/sunbow0 第二章Deep ...
- 深度学习(二)--深度信念网络(DBN)
深度学习(二)--深度信念网络(Deep Belief Network,DBN) 一.受限玻尔兹曼机(Restricted Boltzmann Machine,RBM) 在介绍深度信念网络之前需要先了 ...
- 深度残差网络(DRN)ResNet网络原理
一说起“深度学习”,自然就联想到它非常显著的特点“深.深.深”(重要的事说三遍),通过很深层次的网络实现准确率非常高的图像识别.语音识别等能力.因此,我们自然很容易就想到:深的网络一般会比浅的网络效果 ...
- 深度卷积网络(DCNN)和人类识别物体方法的不同
加州大学洛杉矶分校在PLOS Computing Biology上发表了一篇文章,分析了深度卷积网络(DCNN)和人类识别物体方法的不同:深度卷积网络(DCNN)是依靠物体的纹理进行识别,而人类是依靠 ...
- 深度学习Bible学习笔记:第六章 深度前馈网络
第四章 数值计算(numerical calculation)和第五章 机器学习基础下去自己看. 一.深度前馈网络(Deep Feedfarward Network,DFN)概要: DFN:深度前馈网 ...
- [DeeplearningAI笔记]卷积神经网络2.3-2.4深度残差网络
4.2深度卷积网络 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献 [残差网络]--He K, Zhang X, Ren S, et al. Deep Residual Learni ...
- 机器学习——DBN深度信念网络详解(转)
深度神经网路已经在语音识别,图像识别等领域取得前所未有的成功.本人在多年之前也曾接触过神经网络.本系列文章主要记录自己对深度神经网络的一些学习心得. 简要描述深度神经网络模型. 1. 自联想神经网络 ...
随机推荐
- hadoop -- fsck
hadoop -- fsck shell命令: hdfs fsck /1708a1 -files -blocks -locations -racks /1708a1:是hdfs 中的文件 查看hdfs ...
- Linux用户创建/磁盘挂载相关命令
命令 作用 常用参数说明 groupadd 增加用户组 -g指定组id groupmod 修饰用户组 参数和groupadd类似 groupdel 删除用户组 直接组名没参数 useradd 增加用户 ...
- 开发环境转Mac FAQ
vs2017 for mac, 默认的源代码管理工具是git, 不是svn, 安装source tree,注册bitbucket(免费1G私有空间),整合的比较好(国内的码云也能支持,不过是用账号密码 ...
- 【框架】用excel管理测试用例需要的参数数据(二)
一.总体思路 以类为excel名,测试方法名为sheet名,建立excel文件.用jxl包里的方法去读取excel文件里的内容,然后用testng里的dataprovider,将数据传递给测试用例 二 ...
- scratch如何获取透明的图片
scratch中,每个对象都有一个造型,这个造型可以是载入外部的图片,但是外部图片很多是有背景的,放入scratch舞台区,有背景,很是不爽.用wps2016的ppt演示, 把文本框等另存为图片,图片 ...
- loaclStorage、sessionStorage
这里需要注意的是这两种储存方式只能以字符串的形式来存取 html5中的Web Storage包括了两种存储方式:sessionStorage和localStorage.sessionStorage用于 ...
- bzoj2330
题解: 差分约束系统 要我们求最小值 显然就是转化为最长路 然后spfa一下即可 代码: #include<bits/stdc++.h> using namespace std; ; lo ...
- 深入理解java虚拟机---java虚拟机内存管理(六)
java虚拟机栈的理解 虚拟机栈就是我们所熟知的栈内存,栈内存属于线程独有的.而在栈内存中的局部变量表中存储的引用类型只是存储对象的内存地址.对象的创建在堆内存中,即对象在线程共享区中. 局部变量表: ...
- SQL-25 获取员工其当前的薪水比其manager当前薪水还高的相关信息
题目描述 获取员工其当前的薪水比其manager当前薪水还高的相关信息,当前表示to_date='9999-01-01',结果第一列给出员工的emp_no,第二列给出其manager的manager_ ...
- window.setTimeout和window.setInterval的区别,及用其中一个方法记录时间。
window.setTimeout(语句,时间)是在多久之后执行语句,语句只执行一次. window.setInterval(语句,时间)是每隔多久执行一次语句,语句循环执行. <!DOCTYP ...