SolrServer SolrRequest
SolrServer实现类

HttpSolrServer
HttpSolrServer uses the Apache Commons HTTPClient to connect to solr.
HttpSolrServer is thread-safe and if you are using the following constructor, you must re-use the same instance for all request.
if instances are created on the fly, it can cause a connection leak. The recommended practice is to keep a static instance of HttpSolrServer per solr server url and share it for all requests.
LBHttpSolrServer
LBHttpSolrServer or "LoadBalanced HttpSolrServer" is a load balancing wrapper around org.apache.solr.client.solrj.impl.HttpSolrServer. This is useful when you have multiple SolrServers and the requests need to be Load Balanced among them. Do NOT use this class for indexing in master/slave scenarios since documents must be sent to the correct master; no inter-node routing is done. In SolrCloud (leader/replica) scenarios, this class may be used for updates since updates will be forwarded to the appropriate leader. Also see the wiki page.
It offers automatic failover when a server goes down and it detects when the server comes back up.【容灾】
Load balancing is done using a simple round-robin on the list of servers.【负载均衡】
If a request to a server fails by an IOException due to a connection timeout or read timeout then the host is taken off the list of live servers and moved to a 'dead server list' and the request is resent to the next live server. This process is continued till it tries all the live servers. If at least one server is alive, the request succeeds, and if not it fails.
SolrServer lbHttpSolrServer = new LBHttpSolrServer("http://host1:8080/solr/","http://host2:8080/solr","http://host2:8080/solr");
//or if you wish to pass the HttpClient do as follows
httpClient httpClient = new HttpClient();
SolrServer lbHttpSolrServer = new LBHttpSolrServer(httpClient,"http://host1:8080/solr/","http://host2:8080/solr","http://host2:8080/solr");
This detects if a dead server comes alive automatically. The check is done in fixed intervals in a dedicated thread. This interval can be set using setAliveCheckInterval , the default is set to one minute.【容灾,自感知节点复活】
When to use this?
This can be used as a software load balancer when
you do not wish to setup an external load balancer. Alternatives to this code
are to use a dedicated hardware load balancer or using Apache httpd with
mod_proxy_balancer as a load balancer. See Load balancing on
Wikipedia
CloudSolrServer
SolrJ client class to communicate with SolrCloud. Instances of this class communicate with Zookeeper to discover Solr endpoints for SolrCloud collections, and then use the LBHttpSolrServer to issue requests. This class assumes the id field for your documents is called 'id' - if this is not the case, you must set the right name with setIdField(String).
-- SolrJ includes a 'smart' client for SolrCloud, which is ZooKeeper aware. This means that your Java application only needs to know about your Zookeeper instances, and not where your Solr instances are, as this can be derived from Zookeeper.
ConcurrentUpdateSolrServer
ConcurrentUpdateSolrServer buffers all added documents and writes them into open HTTP connections. This class is thread safe. Params from UpdateRequest are converted to http request parameters. When params change between UpdateRequests a new HTTP request is started. Although any SolrServer request can be made with this implementation, it is only recommended to use ConcurrentUpdateSolrServer with /update requests. The class HttpSolrServer is better suited for the query interface.
SolrServer主要方法
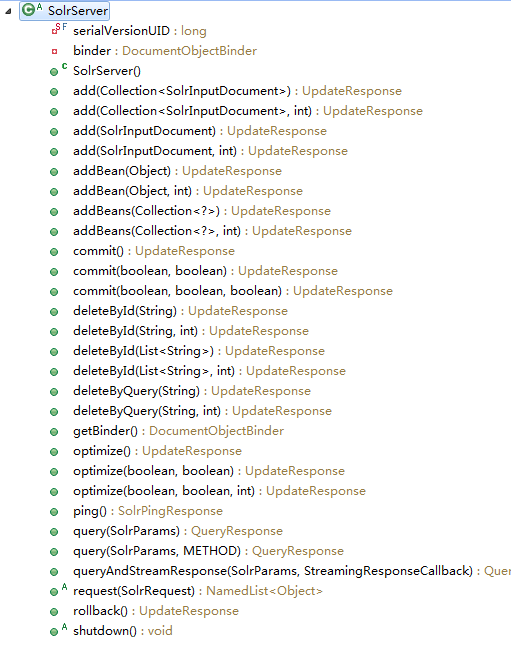
主要方法add、delete、query、commit、optimize等。
这些方法都是根据请求构建对应的SolrRequest,然后执行SolrRequest的process方法。
public abstract SolrResponse process( SolrServer server ) throws SolrServerException, IOException;
SolrRequest的类结构

例如,QueryRequest的process重载:
@Override
public QueryResponse process( SolrServer server ) throws SolrServerException
{
try {
long startTime = TimeUnit.MILLISECONDS.convert(System.nanoTime(), TimeUnit.NANOSECONDS);
QueryResponse res = new QueryResponse( server.request( this ), server );
long endTime = TimeUnit.MILLISECONDS.convert(System.nanoTime(), TimeUnit.NANOSECONDS);
res.setElapsedTime(endTime - startTime);
return res;
} catch (SolrServerException e){
throw e;
} catch (SolrException s){
throw s;
} catch (Exception e) {
throw new SolrServerException("Error executing query", e);
}
}
-----------------------------
http://wiki.apache.org/solr/Solrj
http://wiki.apache.org/solr/LBHttpSolrServer
SolrServer SolrRequest的更多相关文章
- Solr入门之SolrServer实例化方式
随着solr版本的不断升级, 差异越来越大, 从以前的 solr1.2 到现在的 solr4.3, 无论是类还是功能都有很大的变换, 为了能及时跟上新版本的步伐, 在此将新版本的使用做一个简单的入门说 ...
- solrserver实例化
以下是httpClient实例化方式,需要tomcat运行Solr服务 1.ConcurrentUpdateSolrServer实例化SolrServer,该类实例化多用于更新删除索引操作 Concu ...
- Solr 02 - 最详细的solrconfig.xml配置文件解读
目录 1 luceneMatchVersion - 指定Lucene版本 2 lib - 配置扩展jar包 3 dataDir - 索引数据路径 4 directoryFactory - 索引存储工厂 ...
- solr中facet及facet.pivot理解(整合两篇文章保留参考)
Facet['fæsɪt]很难翻译,只能靠例子来理解了.Solr作者Yonik Seeley也给出更为直接的名字:导航(Guided Navigation).参数化查询(Paramatic Searc ...
- solr中facet及facet.pivot理解
Facet['fæsɪt]很难翻译,只能靠例子来理解了.Solr作者Yonik Seeley也给出更为直接的名字:导航(Guided Navigation).参数化查询(Paramatic Searc ...
- 8.solr学习速成之FacetPivot
什么是Facet.pivot Facet.pivot就是按照多个维度进行分组查询,是Facet的加强,在实际运用中经常用到,一个典型的例子就是商品目录树 NamedList解释: NamedList ...
- solr开发之基本操作
package zr.com.util; import java.io.IOException; import java.util.List; import java.util.Map; import ...
- (三)Solrj4到Solrj5的升级之路
(三)Solrj4到Solrj5的升级之路 Solr5发布了,带来了许多激动人心的新特性,但Solrj的许多接口也发生了变化,升级是痛苦的,但也是必须的,下面就赶紧来看看有哪些代码需要升级吧. 变化1 ...
- Solr分组查询
项目中需要实时的返回一下统计的东西,因此就要进行分组,在获取一些东西,代码拿不出来,因此分享一篇,还是很使用的. facet搜索 /** * * 搜索功能优化-关键词搜索 * 搜索范围:商品名称.店 ...
随机推荐
- 快排 - 快速排序算法 (Chinar出品 简单易懂)
Quicksort 快排的简单讲解 本文提供全流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- ...
- Gym.102059: 2018-2019 XIX Open Cup, Grand Prix of Korea(寒假gym自训第一场)
整体来说,这一场的质量比较高,但是题意也有些难懂. E.Electronic Circuit 题意: 给你N个点,M根线,问它是否是一个合法的电路. 思路: 一个合法的电路,经过一些串联并联关系, ...
- PTA——输出各位数字
PTA 7-37 输出整数各位数字 方法1: #include <stdio.h> #define N 10000 int main(){ long n, temp; ; scanf(&q ...
- (13)自定意义标签和过滤器 (templatetags)
过滤器分内置和自定意义 PS:过滤器可以用在for循环和if判断后,但是标签不能使用在for循环和if判断后 内置过滤器: add(在模板中实现加减法) default(就是当传入的变量是False的 ...
- 《DSP using MATLAB》Problem 5.38
代码: %% ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ %% Output In ...
- 找工作String类(重点,背诵)(本质是一个类)
一个顶层设计者眼中只有2个东西接口,类(属性,方法) 无论String 类 , HashMap实现类 , Map接口 String str = "Hello" ; // 定义 ...
- LinkedList(实现了queue,deque接口,List接口)实现栈和队列的功能
LinkedList是用双向链表结构存储数据的,很适合数据的动态插入和删除,随机访问和遍历速度比较慢. 底层是一个双向链表,链表擅长插入和删除操作,队列和栈最常用的2种操作都设计到插入和删除 impo ...
- shell dict 操作
shell 读取文件,利用dict 合并第一列 . #!/bin/bash result_file="a" declare -A mydict total=`cat ${resul ...
- python之路---12 生成器 推导式
三十.函数进阶 1.生成器 函数中有yield 的就是生成器函数(替代了return) 本质就是迭代器 一个一个的创建对象 节省内存 ①创建生成器 最后以yield结束 ...
- angular学习第一天——安装batarang踩到的那些坑儿
angularjs作为一个新兴的JavaScript框架,因其具有不少新特性,比如mvc开发模块,双向数据绑定等等,使其名声大噪.我也久闻其大名,然而因为时间问题,一直都没有去接触过他.这几天工作 ...