MYSQL之 GroupCommit
组提交(group commit)是MYSQL处理日志的一种优化方式,主要为了解决写日志时频繁刷磁盘的问题。组提交伴随着MYSQL的发展不断优化,从最初只支持redo log 组提交,到目前5.6官方版本同时支持redo log 和binlog组提交。组提交的实现大大提高了mysql的事务处理性能,下文将以innodb 存储引擎为例,详细介绍组提交在各个阶段的实现原理。
redo log的组提交
WAL(Write-Ahead-Logging)是实现事务持久性的一个常用技术,基本原理是在提交事务时,为了避免磁盘页面的随机写,只需要保证事务的redo log写入磁盘即可,这样可以通过redo log的顺序写代替页面的随机写,并且可以保证事务的持久性,提高了数据库系统的性能。虽然WAL使用顺序写替代了随机写,但是,每次事务提交,仍然需要有一次日志刷盘动作,受限于磁盘IO,这个操作仍然是事务并发的瓶颈。
组提交思想是,将多个事务redo log的刷盘动作合并,减少磁盘顺序写。Innodb的日志系统里面,每条redo log都有一个LSN(Log Sequence Number),LSN是单调递增的。每个事务执行更新操作都会包含一条或多条redo log,各个事务将日志拷贝到log_sys_buffer时(log_sys_buffer 通过log_mutex
保护),都会获取当前最大的LSN,因此可以保证不同事务的LSN不会重复。那么假设三个事务Trx1,Trx2和Trx3的日志的最大LSN分别为LSN1,LSN2,LSN3(LSN1<LSN2<LSN3),它们同时进行提交,那么如果Trx3日志先获取到log_mutex进行落盘,它就可以顺便把[LSN1---LSN3]这段日志也刷了,这样Trx1和Trx2就不用再次请求磁盘IO。组提交的基本流程如下:
- 获取 log_mutex
- 若flushed_to_disk_lsn>=lsn,表示日志已经被刷盘,跳转5
- 若 current_flush_lsn>=lsn,表示日志正在刷盘中,跳转5后进入等待状态
- 将小于LSN的日志刷盘(flush and sync)
- 退出log_mutex
备注:lsn表示事务的lsn,flushed_to_disk_lsn和current_flush_lsn分别表示已刷盘的LSN和正在刷盘的LSN。
redo log 组提交优化
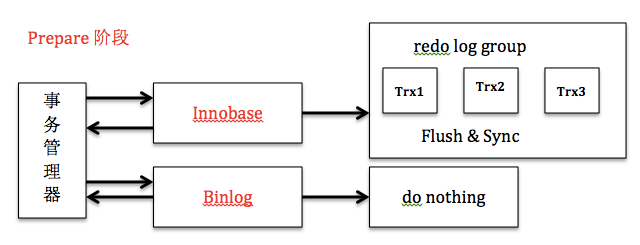
我们知道,在开启binlog的情况下,prepare阶段,会对redo log进行一次刷盘操作(innodb_flush_log_at_trx_commit=1),确保对data页和undo 页的更新已经刷新到磁盘;commit阶段,会进行刷binlog操作(sync_binlog=1),并且会对事务的undo log从prepare状态设置为提交状态(可清理状态)。通过两阶段提交方式(innodb_support_xa=1),可以保证事务的binlog和redo log顺序一致。二阶段提交过程中,mysql_binlog作为协调者,各个存储引擎和mysql_binlog作为参与者。故障恢复时,扫描最后一个binlog文件(在flush阶段,判断binlog是否超过阀值,进行rotate binlog文件,rotate的binlog文件中对应的事务一定是已经提交的,处于prepared的事务的binlog还没有刷进来,因为还没进入ordered_commit函数),提取其中的xid;重做检查点以后的redo日志,读取事务的undo段信息,搜集处于prepare阶段的事务链表,将事务的xid与binlog中的xid对比,若存在,则提交,否则就回滚。
通过上述的描述可知,每个事务提交时,都会触发一次redo flush动作,由于磁盘读写比较慢,因此很影响系统的吞吐量。淘宝童鞋做了一个优化,将prepare阶段的刷redo动作移到了commit(flush-sync-commit)的flush阶段之前,保证刷binlog之前,一定会刷redo。这样就不会违背原有的故障恢复逻辑。移到commit阶段的好处是,可以不用每个事务都刷盘,而是leader线程帮助刷一批redo。如何实现,很简单,因为log_sys->lsn始终保持了当前最大的lsn,只要我们刷redo刷到当前的log_sys->lsn,就一定能保证,将要刷binlog的事务redo日志一定已经落盘。通过延迟写redo方式,实现了redo log组提交的目的,而且减少了log_sys->mutex的竞争。目前这种策略已经被官方mysql5.7.6引入。
两阶段提交
在单机情况下,redo log组提交很好地解决了日志落盘问题,那么开启binlog后,binlog能否和redo log一样也开启组提交?首先开启binlog后,我们要解决的一个问题是,如何保证binlog和redo log的一致性。因为binlog是Master-Slave的桥梁,如果顺序不一致,意味着Master-Slave可能不一致。MYSQL通过两阶段提交很好地解决了这一问题。Prepare阶段,innodb刷redo log,并将回滚段设置为Prepared状态,binlog不作任何操作;commit阶段,innodb释放锁,释放回滚段,设置提交状态,binlog刷binlog日志。出现异常,需要故障恢复时,若发现事务处于Prepare阶段,并且binlog存在则提交,否则回滚。通过两阶段提交,保证了redo log和binlog在任何情况下的一致性。
binlog的组提交
回到上节的问题,开启binlog后,如何在保证redo log-binlog一致的基础上,实现组提交。因为这个问题,5.6以前,mysql在开启binlog的情况下,无法实现组提交,通过一个臭名昭著的prepare_commit_mutex,将redo log和binlog刷盘串行化,串行化的目的也仅仅是为了保证redo log-Binlog一致,但这种实现方式牺牲了性能。这个情况显然是不能容忍的,因此各个mysql分支,mariadb,facebook,perconal等相继出了补丁改进这一问题,mysql官方版本5.6也终于解决了这一问题。由于各个分支版本解决方法类似,我主要通过分析5.6的实现来说明实现方法。
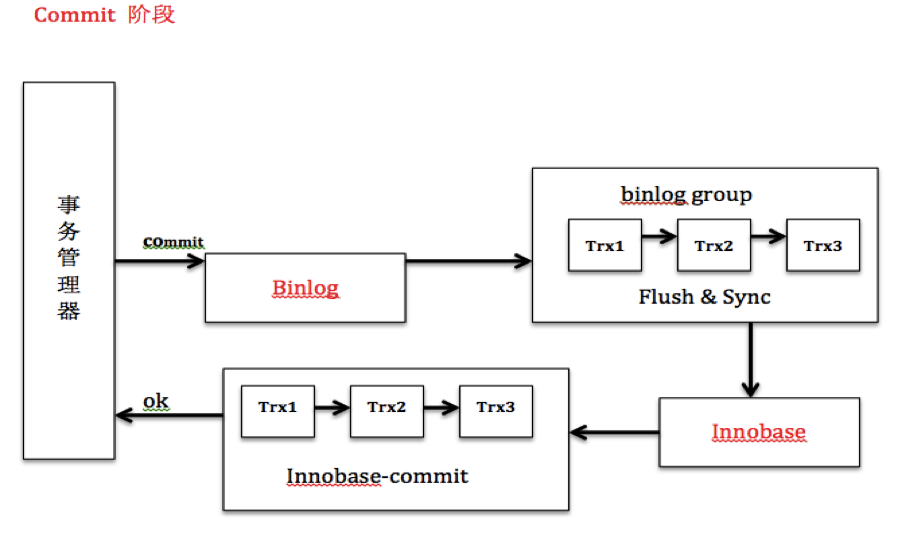
binlog组提交的基本思想是,引入队列机制保证innodb commit顺序与binlog落盘顺序一致,并将事务分组,组内的binlog刷盘动作交给一个事务进行,实现组提交目的。binlog提交将提交分为了3个阶段,FLUSH阶段,SYNC阶段和COMMIT阶段。每个阶段都有一个队列,每个队列有一个mutex保护,约定进入队列第一个线程为leader,其他线程为follower,所有事情交由leader去做,leader做完所有动作后,通知follower刷盘结束。binlog组提交基本流程如下:
FLUSH 阶段
1) 持有Lock_log mutex [leader持有,follower等待]
2) 获取队列中的一组binlog(队列中的所有事务)
3) 将binlog buffer到I/O cache
4) 通知dump线程dump binlog
SYNC阶段
1) 释放Lock_log mutex,持有Lock_sync mutex[leader持有,follower等待]
2) 将一组binlog 落盘(sync动作,最耗时,假设sync_binlog为1)
COMMIT阶段
1) 释放Lock_sync mutex,持有Lock_commit mutex[leader持有,follower等待]
2) 遍历队列中的事务,逐一进行innodb commit
3) 释放Lock_commit mutex
4) 唤醒队列中等待的线程
说明:由于有多个队列,每个队列各自有mutex保护,队列之间是顺序的,约定进入队列的一个线程为leader,因此FLUSH阶段的leader可能是SYNC阶段的follower,但是follower永远是follower。
通过上文分析,我们知道MYSQL目前的组提交方式解决了一致性和性能的问题。通过二阶段提交解决一致性,通过redo log和binlog的组提交解决磁盘IO的性能。下面我整理了Prepare阶段和Commit阶段的框架图供各位参考。
参考文档
http://mysqlmusings.blogspot.com/2012/06/binary-log-group-commit-in-mysql-56.html
http://www.lupaworld.com/portal.php?mod=view&aid=250169&page=all
http://www.oschina.net/question/12_89981
http://kristiannielsen.livejournal.com/12254.html
http://blog.chinaunix.net/uid-26896862-id-3432594.html
http://www.csdn.net/article/2015-01-16/2823591
MYSQL之 GroupCommit的更多相关文章
- MySQL 并行复制演进及 MySQL 8.0 中基于 WriteSet 的优化
MySQL 8.0 可以说是MySQL发展历史上里程碑式的一个版本,包括了多个重大更新,目前 Generally Available 版本已经已经发布,正式版本即将发布,在此将介绍8.0版本中引入的一 ...
- mysql replication /mysql 主从复制原理
一下内容均是根据leader的培训分享整理而成 ************************************我是分割线*********************************** ...
- AnalyticDB for MySQL 3.0 技术架构解析
企业数据需求不断变化,近年来变化趋势日益明显,从数据的3V特性看:体积,速度和变化:Big Data强调数据量,PB级以上,是静态数据.而Fast Data在数据量的基础上,意味着速度和和变化,意味着 ...
- Hadoop 中利用 mapreduce 读写 mysql 数据
Hadoop 中利用 mapreduce 读写 mysql 数据 有时候我们在项目中会遇到输入结果集很大,但是输出结果很小,比如一些 pv.uv 数据,然后为了实时查询的需求,或者一些 OLAP ...
- mysql每秒最多能插入多少条数据 ? 死磕性能压测
前段时间搞优化,最后瓶颈发现都在数据库单点上. 问DBA,给我的写入答案是在1W(机械硬盘)左右. 联想起前几天infoQ上一篇文章说他们最好的硬件写入速度在2W后也无法提高(SSD硬盘) 但这东西感 ...
- LINUX篇,设置MYSQL远程访问实用版
每次设置root和远程访问都容易出现问题, 总结了个通用方法, 关键在于实用 step1: # mysql -u root mysql mysql> Grant all privileges o ...
- nodejs进阶(6)—连接MySQL数据库
1. 建库连库 连接MySQL数据库需要安装支持 npm install mysql 我们需要提前安装按mysql sever端 建一个数据库mydb1 mysql> CREATE DATABA ...
- MySQL高级知识- MySQL的架构介绍
[TOC] 1.MySQL 简介 概述 MySQL是一个关系型数据库管理系统,由瑞典MySQL AB公司开发,目前属于Oracle公司. MySQL是一种关联数据库管理系统,将数据保存在不同的表中,而 ...
- 闰秒导致MySQL服务器的CPU sys过高
今天,有个哥们碰到一个问题,他有一个从库,只要是启动MySQL,CPU使用率就非常高,其中sys占比也比较高,具体可见下图. 注意:他的生产环境是物理机,单个CPU,4个Core. 于是,他抓取了CP ...
随机推荐
- day 67 django 之ORM 增删改查基础
一 操作基础前提准备 1. 新建django 项目 mysite 子项目app01 ,选择好做路径. 2 .2-1在app01 下面models 中引用 模块 from django.db im ...
- ChinaCock界面控件介绍-TCCImageViewerForm
有多个图片,左右滑动可以切换,通过手势还可以放大.缩小查看,象常见的相册,就是这样子实现效果. 现在,我们有了TCCImageViewerForm组件,也可以轻松实现这样的场景应用. 现在看看TCCI ...
- 2019-03-06-day012-生成器与推导式
01 昨日回顾 迭代器: 迭代器有iter方法 next方法就是迭代器 递归: 自己调用自己 明确的结束条件 递归的最大深度 官方 1000 实际测试:998/997 import sys sys.s ...
- vue--http请求的封装--session
export function Fecth (url, data, file, _method) { if (file) { // 需要上传文件 return new Promise((resolve ...
- DocumentFragment --更快捷操作DOM的途径
使用DocumentFragment将一批子元素添加到任何类似node的父节点上,对这批子元素的操作不需要一个真正的根节点.可以不依赖可见的DOM来构造一个DOM结构,而效率高是它真正的优势,试验表明 ...
- elk的安装部署
Elk日志安装文档 需要用到有三个软件包 和redis 分布式部署:已上图就是分布式部署的架构图 Logstash : 是部署在前台的应用上,收集数据的 和部署在redis和elasticsea ...
- 后门技术(HOOK篇)之DT_RPATH
0x01 GNU ld.so动态库搜索路径 参考材料:https://en.wikipedia.org/wiki/Rpath 下面介绍GNU ld.so加载动态库的先后顺序: LD_PRELOAD环境 ...
- simhash
1,SimHash https://yanyiwu.com/work/2014/01/30/simhash-shi-xian-xiang-jie.html 64位Hash为什么海明距离选3? http ...
- [LeetCode&Python] Problem 530. Minimum Absolute Difference in BST
Given a binary search tree with non-negative values, find the minimum absolute difference between va ...
- 修改JAVA代码,需要重启Tomcat的原因
准确的说只有修改方法中的内容才不需要重启,因为tomcat中对于方法的调用是动态的,调用方法的时候,方法的内容才会被加载 新增成员变量,方法,或修改静态方法和静态变量.创建新的类 这些都是需要重启的, ...