深入理解Fsync
1 介绍
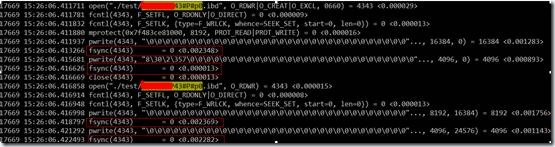
数据库系统从诞生那天开始,就面对一个很棘手的问题,fsync的性能问题。组提交(group commit)就是为了解决fsync的问题。最近,遇到一个业务反映MySQL创建分区表很慢,仔细分析了一下,发现InnoDB在创建表的时候有很多fsync——每个文件会有4个fsync的调用。当然,并不每个fsync的开销都很大。
这里引出几个问题:
(1)问题1:为什么fsync开销相对都比较大?它到底做了什么?
(2)问题2:细心的人可以发现,第一次open数据文件后,第二次fsync的时间远远小于第1次调用fsync的时间,为什么?
(3)问题3:能否优化fsync?
来着这些疑问,一起来了解一下fsync。
2 原因分析
我们先通过一个测试程序来学习一下fsync在块层的基本流程。
2.1 测试程序1
|
Write page 0 Sleep 5 Fsync |
用blktrace跟踪结果如下:
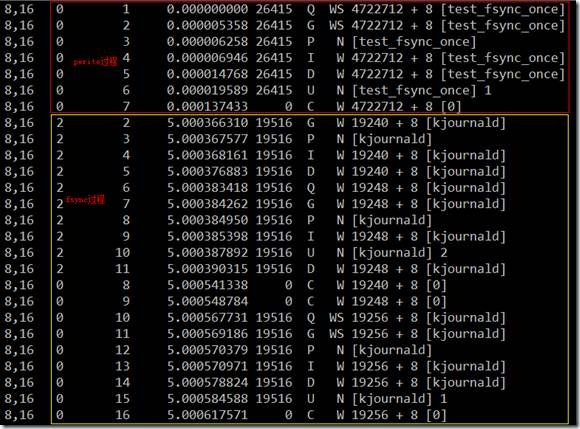
上半部红色框内为pwrite在块层的流程,下半部黄色框内为fsync在块层流程,中间刚好相差5秒。
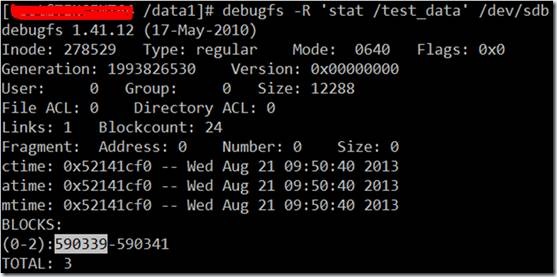
4722712为测试文件的第1个block对应的扇区号,590339(block号) * 8=4722712(扇区号)。
无论是pwrite,还是fsync,主要的开销都发生IO请求提交给驱动和IO完成之间,也就是说开自设备驱动。差不多占了整个系统调用的1/2的开销。
另外,可以看到调用fsync时,发生了3次块层IO,起始扇区分别是19240、19248和19256,物理上3个连续的块。实际上这3个块为内核线程kjournald写的日志,分别描述块(2405)、数据块(2406)和提交块(2407)。为了验证,不妨看一下这三个块的实际数据。
块2405:

|
#define JFS_MAGIC_NUMBER 0xc03b3998U #define JFS_DESCRIPTOR_BLOCK 1 #define JFS_COMMIT_BLOCK 2 |
开始的4个字节为JFS_MAGIC_NUMBER,然后是block type:JFS_DESCRIPTOR_BLOCK。
块2407:

的确是提交块。
2.2 fsync的实现
既然fsync的开销很大,就来看看代码吧。
函数ext3_sync_file:
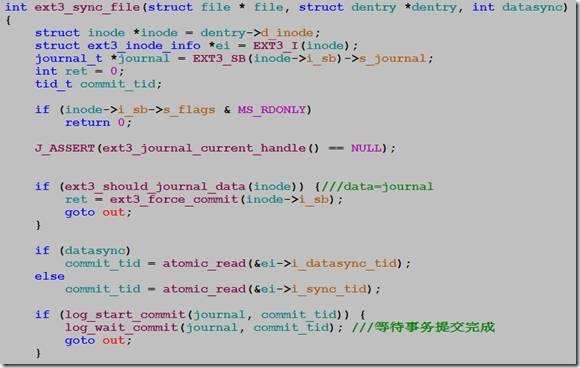
函数log_start_commit负责唤醒kjounald内核线程,log_wait_commit等待jbd事务提交完成。
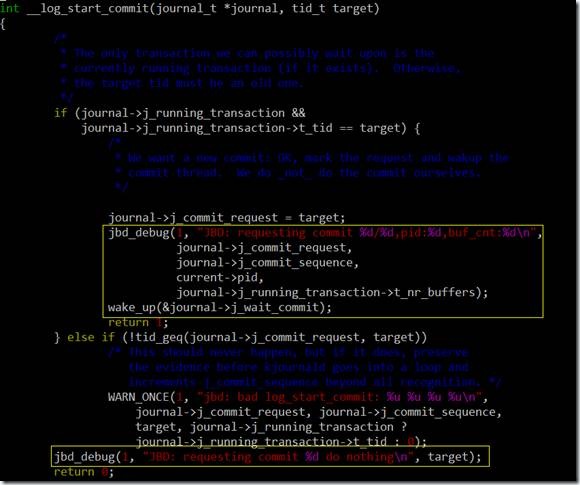
从代码来看,fsync的主要开销在于调用log_wait_commit后的等待。也就是说fsync要等待kjournald把事务提交完成,才会返回。
到这里,我们已经知道了fsync开销的主要来源:(1)硬件驱动层的开销;(2)ext3写日志。
另外,当log_start_commit返回0时,fsync就不会等待事务提交完成。到这里已经基本可以确认第2次fsync的开销为什么那么小了——没有wait事务提交。
下面验证这一想法。为了方便调试,打开了内核jbd debug日志。
2.3 测试程序2
|
Write page 0 Fsync Write page 0 Fsync Write page 1 Fsync Write page 2 Fsync |
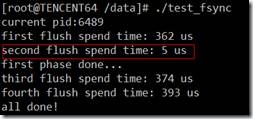
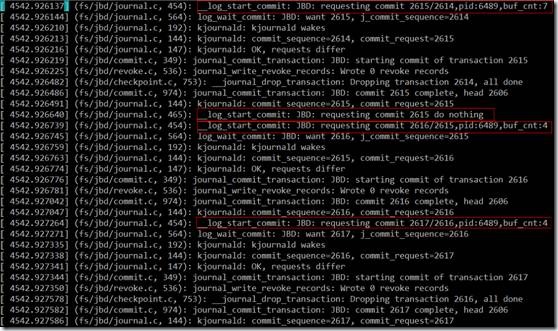
从第2个红框的日志来看,第2次fsync时,的确是没有wait的,所以开销这么小,而其它3次fsync都调用了log_wait_commit函数。
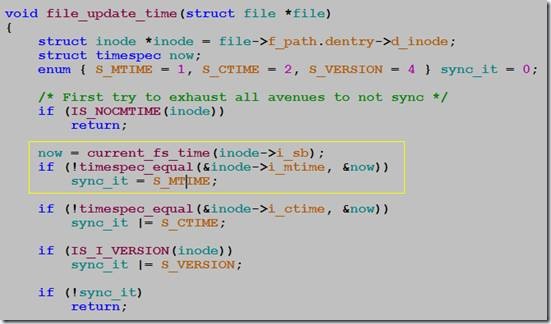
问题4:第2次fsync为什么不会调用log_wait_commit?
因为挂载文件系统的时候,data=writeback,即写数据本身不会写jbd日志。第2次pwrite没有引起文件扩展,只会修改ext3 inode的i_mtime,而i_mtime只精确到second,也就是说第2次pwrite不会引起inode信息改变,所以,不会生成jbd日志,也就不需要等待事务提交完成。
下面验证一下该想法。
2.4 测试程序3
|
Write page 0 Fsync Sleep 1 second Write page 0 Fsync Write page 1 Fsync Write page 2 Fsync |
在第2次pwrite之前,sleep 1秒钟,保证ext3 inode的i_mtime修改。
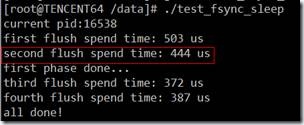
想法被证实了,第2次fsync的时间回到正常水平。
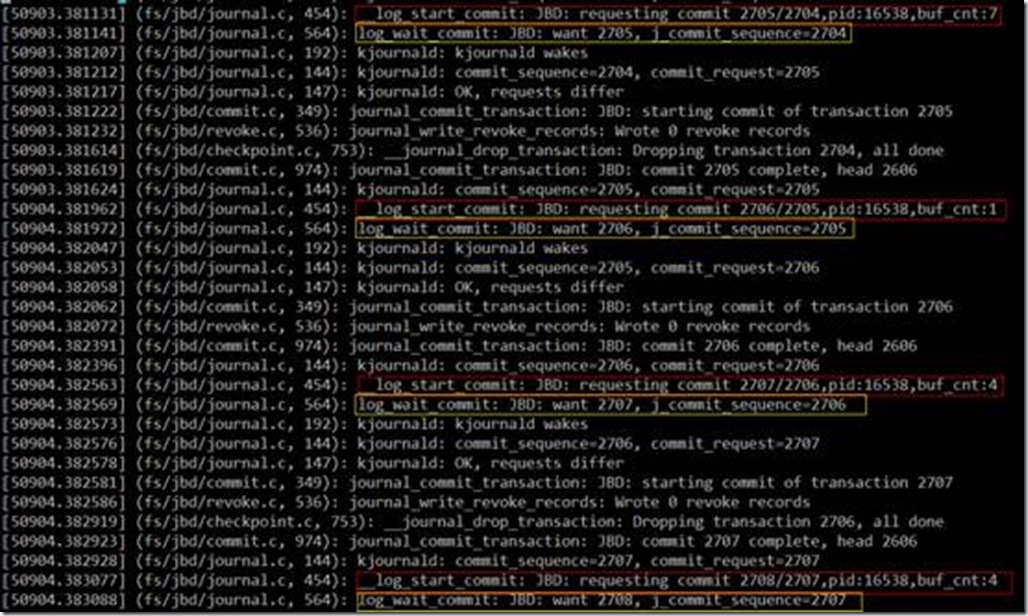
可以看到,第2次fsync调用提交了新的事务,并调用了log_wait_commit等待事务完成。
3 优化
如何优化fsync?是个难题。
(1)系统减少对fsync的调用。
(2)ext3日志放在更快的存储介质,参考http://insights.oetiker.ch/linux/external-journal-on-ssd/
作者:YY哥
出处:http://www.cnblogs.com/hustcat/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
深入理解Fsync的更多相关文章
- LINUX 文件系统JBD ----深入理解Fsync
http://www.cnblogs.com/hustcat/p/3283955.html http://www.cnblogs.com/zengkefu/p/5639200.html http:// ...
- 深入理解MySQL系列之redo log、undo log和binlog
事务的实现 redo log保证事务的持久性,undo log用来帮助事务回滚及MVCC的功能. InnoDB存储引擎体系结构 redo log Write Ahead Log策略 事务提交时,先写重 ...
- redis 的理解
1.Redis使用 C语言开发的.Redis 约定此版本号,为偶数的版本是稳定版(如:2.4版 2.6版),奇数版是非稳定版(如:2.5版 2.7版) 2.Redis 数据库中的所有的数据都存储在内存 ...
- linux 同步IO: sync msync、fsync、fdatasync与 fflush
最近阅读leveldb源码,作为一个保证可靠性的kv数据库其数据与磁盘的交互可谓是极其关键,其中涉及到了不少内存和磁盘同步的操作和策略.为了加深理解,从网上整理了linux池畔同步IO相关的函数,这里 ...
- Linux就这个范儿 第15章 七种武器 linux 同步IO: sync、fsync与fdatasync Linux中的内存大页面huge page/large page David Cutler Linux读写内存数据的三种方式
Linux就这个范儿 第15章 七种武器 linux 同步IO: sync.fsync与fdatasync Linux中的内存大页面huge page/large page David Cut ...
- Linux中文件描述符fd和文件指针flip的理解
转自:http://www.cnblogs.com/Jezze/archive/2011/12/23/2299861.html 简单归纳:fd只是一个整数,在open时产生.起到一个索引的作用,进程通 ...
- [Mysql] MySQL配置文件my.cnf的理解
一.缘由 最近要接手数据库的维护工作,公司首选MySQL.对于MySQL的理解,我认为很多性能优化工作.主从主主复制都是在调整参数,来适应不同时期不同数量级的数据. 故,理解透彻my.cnf里的参数是 ...
- 关于write()和fsync()
--关于write()和fsync() ----------------------------转载 write ssize_t write(int fd, const void *buf, si ...
- Elasticsearch-深入理解索引原理
最近开始大面积使用ES,很多地方都是知其然不知其所以然,特地翻看了很多资料和大牛的文档,简单汇总一篇.内容多为摘抄,说是深入其实也是一点浅尝辄止的理解.希望大家领会精神. 首先学习要从官方开始地址如下 ...
随机推荐
- java算法:统计数字-将数字转换成字符串,然后使用字符串String.valueOf()方法进行判断
题目: 计算数字 k 在 0 到 n 中的出现的次数,k 可能是 0~9 的一个值. 样例 样例 1: 输入: k = 1, n = 1 输出: 1 解释: 在 [0, 1] 中,我们发现 1 出现了 ...
- asp.net core web项目目录解读
Connected Services 和传统.net web项目相比,它的功能类似于添加webservice或者wcf service的引用.暂时用不到,有兴趣的小伙伴可以深入了解.右键这个目录可以看 ...
- BZOJ1901 Zju2112 Dynamic Rankings 主席树
欢迎访问~原文出处——博客园-zhouzhendong 去博客园看该题解 题目传送门 - BZOJ1901 题意概括 给你一段序列(n个数),让你支持一些操作(共m次), 有两种操作,一种是询问区间第 ...
- Immediate Decodability HDU1305
类似phonelist 一次ac 判断失败主要有两个要点 1. 是否包含了某段的结尾结点 说明某段被此段包含 2.此段的结尾结点是否为某段的痕迹 说明此段被包含 #include<bi ...
- 097实战 关于ETL的几种运行方式
一:代码部分 1.新建maven项目 2.添加需要的java代码 3.书写mapper类 4.书写runner类 二:运行方式 1.本地运行 2.集群运行 3.本地提交集群运行 三:本地运行方式 1. ...
- 微信小程序倒计时组件开发
今天给大家带来微信小程序倒计时组件具体开发步骤: 先来看下最终效果: git源:http://git.oschina.net/dotton/CountDown 分步骤-性子急的朋友,可以直接看最后那段 ...
- Mongodb - 二进制安装
0.概述 mongodb版本:4.0.2 linux版本:redhat 6.5 安装方式:二进制安装 1.关闭防火墙 /etc/init.d/iptables status/etc/init.d/ip ...
- Coredata 单表简单使用
** 使用Coredata 工程中的DataModel创建:系统创建.手动创建** ** 使用Coredata需要要导入<CoreData/CoreData.h> ** 1.系统创建(系统 ...
- 不一样的go语言创世
在这之前,我是一名Java程序员,但最近我却已经好几个月没写Java代码了,因为我已经敲了好几个月的go,这是我连续最长的一段时间在写go.陆陆续续地算下来,也有快一年多的时间在与go打交道.期间 ...
- Java 复习
基础: JAVA基础扎实,理解io.多线程.集合等基础框架,对JVM原理有一定的了解: 熟读Java SDK源码: 框架: 对Spring,ibatis,struts等开源框架熟悉: