InnoDB存储引擎介绍-(5) Innodb逻辑存储结构
如果创建表时没有显示的定义主键,mysql会按如下方式创建主键:
- 首先判断表中是否有非空的唯一索引,如果有,则该列为主键。
- 如果不符合上述条件,存储引擎会自动创建一个6字节大小的指针。
当表中有多个非空的唯一索引,会选择建表时第一个定义的非空唯一索引。注意根据的是定义索引的顺序,不是创建列的顺序。
- 表空间 tablespace(ibd文件)
- 段 segment(一个索引2个段)
- Extent(1MB)
- Page(16KB)
- Row
- Field
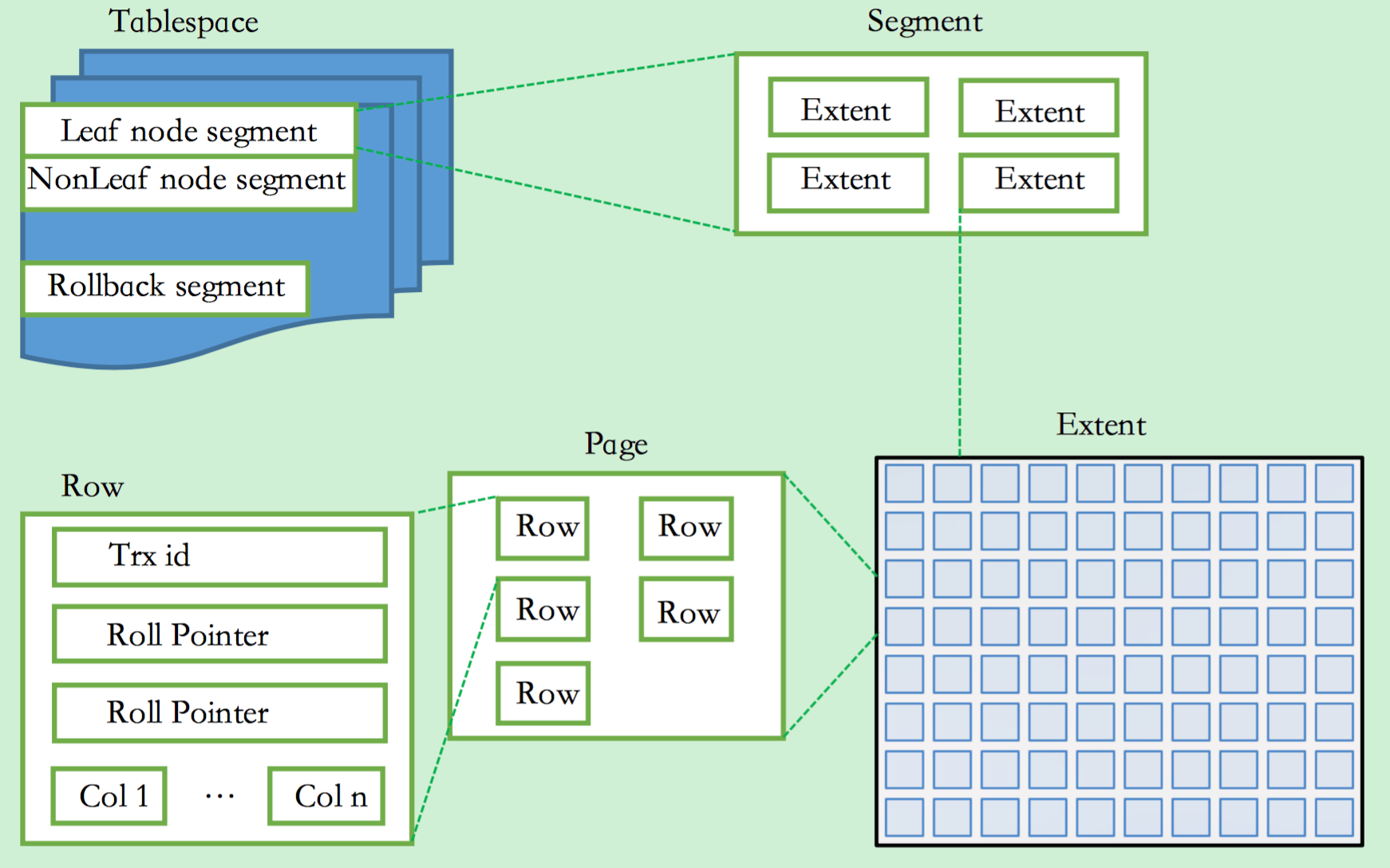
表空间
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。在默认情况下InnoDB存储引擎有一个共享表空间ibdata1,即所有数据都存放在这个表空间内。如果用户启用了参数innodb_file_per_table,则每个表内的数据可以单独放到一个表空间内。
如果启动了innodb_file_per_table参数,需要注意的是每张表的表空间内存放的只是数据、索引和插入缓冲Bitmap页,其他类的数据,如回滚(undo)信息,插入缓冲索引页、系统事务信息,二次写缓冲(Double write buffer)等还是存放在原来的共享表空间内。这同时也说明了另一个问题:即使在启用了参数innodb_file_per_table之后,共享表空间还是会不断地增加其大小。可以来做一个实验,在实验之前已经将innodb_file_per_table设为ON了。现在看看初始共享表空间文件的大小:
mysql> show variables like 'innodb_file_per_table'\G
*************************** 1. row ***************************
Variable_name: innodb_file_per_table
Value: ON
1 row in set (0.00 sec) mysql> system ls -tlhr /home/mysql/mysql/data/ibdata*
-rw-rw----. 1 mysql mysql 204M Mar 21 05:54 /home/mysql/mysql/data/ibdata1
可以看到,共享表空间ibdata1的大小为204MB,接着模拟产生undo的操作,使用表orders,并把其存储引擎更改为InnoDB,执行如下操作:
mysql> set autocommit=0;
mysql> update orders set device_number=0;
Query OK, 3278492 rows affected (0.03 sec)
Rows matched: 3278492 Changed: 3278492 Warnings: 0 mysql> system ls -tlhr /home/mysql/mysql/data/ibdata*
-rw-rw----. 1 mysql mysql 652M Mar 21 07:38 /home/mysql/mysql/data/ibdata1
这里首先将自动提交设为0,即用户需要显式提交事务(注意,在上面操作结束时,并没有对该事务执行commit或rollback)。接着执行会产生大量的undo操作的语句update orders set device_number=0,完成后再观察共享表空间,会发现ibdata1已经增长到了652MB。这个例子虽然简单,但是足以说明共享表空间中还包含有undo信息。
有用户会问,如果对k这个事务执行rollback,ibdata1这个表空间会不会缩减至原来的大小(204MB)?这可以通过继续运行下面的语句得到验证:
mysql> rollback;
Query OK, 0 rows affected (0.01 sec) mysql> system ls -tlhr /home/mysql/mysql/data/ibdata*
-rw-rw----. 1 mysql mysql 652M Mar 21 07:49 /home/mysql/mysql/data/ibdata1
很“可惜”,共享表空间的大小还是204MB,即InnoDB存储引擎不会在执行rollback时去收缩这个表空间。虽然InnoDB不会回收这些空间,但是会自动判断这些undo信息是否还需要,如果不需要,则会将这些空间标记为可用空间,供下次undo使用。
master thread每10秒会执行一次的full purge操作,很有可能的一种情况是:用户再次执行上述的update语句后,会发现ibdata1不会再变大了,那就是这个原因了。
使用py_innodb_page_info小工具查看表空间中各页的类型和信息,用户可以在github.com进行查找。https://github.com/qingdengyue/david-mysql-tools/tree/master/py_innodb_page_type.
使用方法如下:
$ python ~/py_innodb_page_info.py ibdata1
Total number of page: 41728:
Insert Buffer Free List: 1035
Insert Buffer Bitmap: 3
System Page: 131
Transaction system Page: 2
Freshly Allocated Page: 5074
Undo Log Page: 33238
File Segment inode: 5
B-tree Node: 2235
File Space Header: 2
可以看到共有41728个页,其中插入缓冲的空间有1035个页、5074个可用页、33238个undo页、2235个数据页等。用户可以通过添加-v参数来查看更详细的内容。
段
上图中显示了表空间是由各个段组成的,常见的段有数据段、索引段、回滚段等。InnoDB存储引擎表是索引组织的(index organized),因此数据即索引,索引即数据。那么数据段即为B+树的页节点(上图的leaf node segment),索引段即为B+树的非索引节点(上图的non-leaf node segment)。
与Oracle不同的是,InnoDB存储引擎对于段的管理是由引擎本身完成,这和Oracle的自动段空间管理(ASSM)类似,没有手动段空间管理(MSSM)的方式,这从一定程度上简化了DBA的管理。
需要注意的是,并不是每个对象都有段。因此更准确地说,表空间是由分散的页和段组成。
区
区是由64个连续的页组成的,每个页大小为16KB,即每个区的大小为1MB。对于大的数据段,InnoDB存储引擎最多每次可以申请4个区,以此来保证数据的顺序性能。
在我们启用了参数innodb_file_per_talbe后,创建的表默认大小是96KB。区是64个连续的页,那创建的表的大小至少是1MB才对啊?其实这是因为在每个段开始时,先有32个页大小的碎片页(fragment page)来存放数据,当这些页使用完之后才是64个连续页的申请。
通过一个实验来显示InnoDB存储引擎对于区的申请:
create table t1 (
col1 int not null auto_increment,
col2 varchar (7000),
primary key(col1)
)engine=InnoDB;
system ls -lh /usr/local/var/mysql/test/t1.ibd
创建了t1表,col2字段设为varchar(7000),这样能保证一个页中可以存放2条记录。可以看到,初始创建完t1后表空间默认大小为96KB.
页
同大多数数据库一样,InnoDB有页(page)的概念(也可以称为块),页是InnoDB磁盘管理的最小单位。与Oracle类似的是,Microsoft SQL Server数据库默认每页大小为8KB,不同于InnoDB页的大小(16KB),且不可以更改(也许通过更改源码可以)。
常见的页类型有:
- 数据页(B-tree Node)。
- Undo页(Undo Log Page)。
- 系统页(System Page)。
- 事务数据页(Transaction system Page)。
- 插入缓冲位图页(Insert Buffer Bitmap)。
- 插入缓冲空闲列表页(Insert Buffer Free List)。
- 未压缩的二进制大对象页(Uncompressed BLOB Page)。
- 压缩的二进制大对象页(Compressed BLOB Page)。
行
InnoDB存储引擎是面向行的(row-oriented),也就是说数据的存放按行进行存放。每个页存放的行记录也是有硬性定义的,最多允许存放16KB/2~200行的记录,即7992行记录。这里提到面向行(row-oriented)的数据库,那么也就是说,还存在有面向列(column-orientied)的数据库。MySQL infobright储存引擎就是按列来存放数据的,这对于数据仓库下的分析类SQL语句的执行以及数据压缩很有好处。类似的数据库还有Sybase IQ、Google Big Table。面向列的数据库是当前数据库发展的一个方向。
InnoDB存储引擎介绍-(5) Innodb逻辑存储结构的更多相关文章
- InnoDB存储引擎介绍-(3)InnoDB缓冲池配置详解
原文链接 http://www.ywnds.com/?p=9886 一.InnoDB缓冲池 InnoDB维护一个称为缓冲池的内存存储区域 ,用于缓存内存中的数据和索引.了解InnoDB缓冲池的工作原 ...
- InnoDB存储引擎介绍-(1)InnoDB存储引擎结构
首先以一张图简单展示 InnoDB 的存储引擎的体系架构. 从图中可见, InnoDB 存储引擎有多个内存块,这些内存块组成了一个大的内存池,主要负责如下工作: 维护所有进程/线程需要访问的多个内部数 ...
- InnoDB存储引擎介绍-(7) Innodb数据页结构
数据页结构 File Header 总共38 Bytes,记录页的头信息 名称 大小(Bytes) 描述 FIL_PAGE_SPACE 4 该页的checksum值 FIL_PAGE_OFFSET 4 ...
- 170309、MySQL存储引擎MyISAM与InnoDB区别总结整理
1.MySQL默认存储引擎的变迁 在MySQL 5.1之前的版本中,默认的搜索引擎是MyISAM,从MySQL 5.5之后的版本中,默认的搜索引擎变更为InnoDB. 2.MyISAM与InnoDB存 ...
- MySQL存储引擎MyISAM和InnoDB,索引结构优缺点
MySQL存储引擎MyISAM和InnoDB底层索引结构 深入理解MySQL索引底层数据结构与算法 (各种索引结构优缺点) Myisam和Innodb索引实现的不同(存储结构) 存储引擎作用于什么对象 ...
- MySQL 存储引擎(MyISAM、InnoDB、NDBCluster)
前言 MySQL 的存储引擎可能是所有关系型数据库产品中最具有特色的了,不仅可以同时使用多种存储引擎,而且每种存储引擎和MySQL之间使用插件方式这种非常松的耦合关系. 由于各存储引擎功能特性差异较大 ...
- 转!!MySQL中的存储引擎讲解(InnoDB,MyISAM,Memory等各存储引擎对比)
MySQL中的存储引擎: 1.存储引擎的概念 2.查看MySQL所支持的存储引擎 3.MySQL中几种常用存储引擎的特点 4.存储引擎之间的相互转化 一.存储引擎: 1.存储引擎其实就是如何实现存储数 ...
- MySQL两种存储引擎: MyISAM和InnoDB
MySQL两种存储引擎: MyISAM和InnoDB 简单总结 MyISAM是MySQL的默认数据库引擎(5.5版之前),由早期的ISAM(Indexed Sequential Access Me ...
- MySQL存储引擎 - Myisam和Innodb
Mysql有两种存储引擎:InnoDB与Myisam,下表是两种引擎的简单对比 MyISAM InnoDB 构成上的区别: 每个MyISAM在磁盘上存储成三个文件.第一个 文件的名字以表的名字开始 ...
随机推荐
- docker 命令2
docker build -t dvm.adsplatformproxy:v1.0.0 . #build images docker run -e WWNamespace=dev -e ZKServe ...
- HDU 4323 Magic Number(编辑距离DP)
http://acm.hdu.edu.cn/showproblem.php?pid=4323 题意: 给出n个串和m次询问,每个询问给出一个串和改变次数上限,在不超过这个上限的情况下,n个串中有多少个 ...
- 微信小游戏开发之JS面向对象
//游戏开发之面向对象 //在js的开发模式中有两种模式:函数式+面向对象 //1.es5 // 拓展一:函数的申明和表达式之间的区别 // 函数的申明: // function funA(){ // ...
- 一行css解决图片统一大小后的拉伸问题(被冷漠的object-fit)
一.先来个实战 1. 测试案例 需求: 要求表情库里所有表情包大小都固定 实际效果: 由于图片原始大小都不一样,强行设定大小值会导致拉伸,如果不设定大小则参差不齐.例如: //html <bod ...
- Educational Codeforces Round 23 D. Imbalanced Array 单调栈
D. Imbalanced Array time limit per test 2 seconds memory limit per test 256 megabytes input standard ...
- idea中git pull push需要反复输入密码
在使用idea开发的过程中,在终端terminal中git pull和git push时遇到一个问题,一个是 每次提交都需要输入用户名和密码,,从网上找了下解决方案,记录一下. 解决: 打开git终端 ...
- 数据库 Mysql 使用,优化,索引
数据库事务的隔离级别,由低到高 : READ UNCOMMITTED(读未提交数据):允许事务读取未被其他事务提交的变更数据,会出现脏读.不可重复读和幻读问题. READ COMMITTED(读已提交 ...
- tensorflow example1
用tensorflow实现J(w)=w**2-10*w+25的微分结果 import numpy as npimport tensorflow as tf w=tf.Variable(0,dtype= ...
- 关于fstream、ifstream、ofstream读写文本文件、二进制文件详解
fstream.ifstream.ofstream是c++中关于文件操作的三个类 fstream类对文件进行读操作和写操作 打开文件 fstream fs("要打开的文件名",打开 ...
- Codeforces 1076 E - Vasya and a Tree
E - Vasya and a Tree 思路: dfs动态维护关于深度树状数组 返回时将当前节点的所有操作删除就能保证每次访问这个节点时只进行过根节点到当前节点这条路径上的操作 代码: #pragm ...