python 实现图的深度优先和广度优先搜索
在介绍 python 实现图的深度优先和广度优先搜索前,我们先来了解下什么是“图”。
1 一些定义
顶点
顶点(也称为“节点”)是图的基本部分。它可以有一个名称,我们将称为“键”。
边
边(也称为“弧”)是图的另一个基本部分。边连接两个顶点,以表明它们之间存在关系。
权重
边可以被加权以示出从一个顶点到另一个顶点的成本。例如,在将一个城市连接到另一个城市的道路的图表中,边上的权重可以表示两个城市之间的距离。
利用这些定义,我们可以正式定义图。图可以由 G 表示,其中 G =(V,E)。对于图 G,V 是一组顶点,E 是一组边。每个边是一个元组 (v,w),其中 w,v ∈ V。我们可以添加第三个组件到边元组来表示权重。子图 s 是边 e 和顶点 v 的集合,使得 e⊂E 和 v⊂V 。
下图展示了简单加权有向图的另一示例。正式地,我们可以将该图表示为:
六个顶点的集合:
V={V0,V1,V2,V3,V4,V5};
9 条边的集合:
E={(v0,v1,5),(v1,v2,4),(v2,v3,9),(v3,v4,7),(v4,v0,1),(v0,v5,2),(v5,v4,8),(v3,v5,3),(v5,v2,1)}

2 常见的图结构
有两个众所周知的图形、实现,邻接矩阵和邻接表。
2.1 邻接矩阵
实现图的最简单的方法之一是使用二维矩阵。在该矩阵实现中,每个行和列表示图中的顶点。存储在行 v 和列 w 的交叉点处的单元中的值表示是否存在从顶点 v 到顶点 w 的边。 当两个顶点通过边连接时,我们说它们是相邻的。 下图展示了图的邻接矩阵。单元格中的值表示从顶点 v 到顶点 w 的边的权重。

邻接矩阵的优点是简单,对于小图,很容易看到哪些节点连接到其他节点。 然而,注意矩阵中的大多数单元格是空的。 因为大多数单元格是空的,我们说这个矩阵是“稀疏的”。矩阵不是一种非常有效的方式来存储稀疏数据。
2.2 邻接表
实现稀疏连接图的更空间高效的方法是使用邻接表。在邻接表实现中,我们保存 Graph 对象中的所有顶点的主列表,然后图中的每个顶点对象维护连接到的其他顶点的列表。 在我们的顶点类的实现中,我们将使用字典而不是列表,其中字典键是顶点,值是权重。
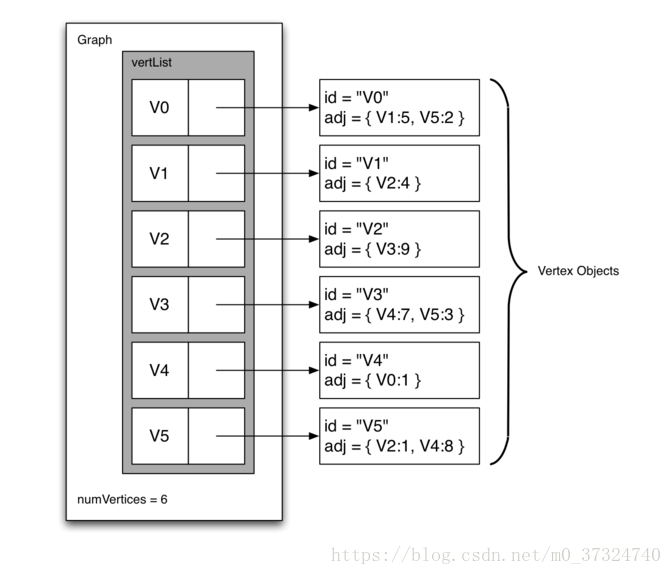
邻接表实现的优点是它允许我们紧凑地表示稀疏图。 邻接表还允许我们容易找到直接连接到特定顶点的所有链接。
3 python 实现图
在我们的 Graph 抽象数据类型的实现中,我们将创建两个类,Graph(保存顶点的主列表)和 Vertex(将表示图中的每个顶点)。每个顶点使用字典来跟踪它连接的顶点和每个边的权重。这个字典称 connectedTo 。
下面展示了 Vertex 类的代码。构造函数只是初始化 id ,通常是一个字符串和 connectedTo 字典。 addNeighbor 方法用于从这个顶点添加一个连接到另一个。getConnections 方法返回邻接表中的所有顶点,如 connectedTo 实例变量所示。 getWeight 方法返回从这个顶点到作为参数传递的顶点的边的权重。
class Vertex:
def __init__(self,key):
self.id = key
self.connectedTo = {}
def addNeighbor(self,nbr,weight=0):
self.connectedTo[nbr] = weight
def __str__(self):
return str(self.id) + ' connectedTo: ' + str([x.id for x in self.connectedTo])
def getConnections(self):
return self.connectedTo.keys()
def getId(self):
return self.id
def getWeight(self,nbr):
return self.connectedTo[nbr]下面展示了 Graph 类的代码,包含将顶点名称映射到顶点对象的字典。Graph 还提供了将顶点添加到图并将一个顶点连接到另一个顶点的方法。getVertices方法返回图中所有顶点的名称。此外,我们实现了__iter__ 方法,以便轻松地遍历特定图中的所有顶点对象。 这两种方法允许通过名称或对象本身在图形中的顶点上进行迭代。
class Graph:
def __init__(self):
self.vertList = {}
self.numVertices = 0
def addVertex(self,key):
self.numVertices = self.numVertices + 1
newVertex = Vertex(key)
self.vertList[key] = newVertex
return newVertex
def getVertex(self,n):
if n in self.vertList:
return self.vertList[n]
else:
return None
def __contains__(self,n):
return n in self.vertList
def addEdge(self,f,t,cost=0):
if f not in self.vertList:
nv = self.addVertex(f)
if t not in self.vertList:
nv = self.addVertex(t)
self.vertList[f].addNeighbor(self.vertList[t], cost)
def getVertices(self):
return self.vertList.keys()
def __iter__(self):
return iter(self.vertList.values())我们用上面定义的两个类,建立如下的图结构。首先我们创建 6 个编号为 0 到 5 的顶点。然后我们展示顶点字典。注意,对于每个键 0 到 5,我们创建了一个顶点的实例。接下来,我们添加将顶点连接在一起的边。 最后,嵌套循环验证图中的每个边缘是否正确存储。

g = Graph()
for i in range(6):
g.addVertex(i)
g.addEdge(0,1,5)
g.addEdge(0,5,2)
g.addEdge(1,2,4)
g.addEdge(2,3,9)
g.addEdge(3,4,7)
g.addEdge(3,5,3)
g.addEdge(4,0,1)
g.addEdge(5,4,8)
g.addEdge(5,2,1)g.vertList
for v in g:
for w in v.getConnections():
print("( %s , %s )" % (v.getId(), w.getId()))
4 图的搜索
回溯法(探索与回溯法)是一种选优搜索法,按选优条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择并不优或达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法,而满足回溯条件的某个状态的点称为“回溯点”。
4.1 广度优先搜索
实现步骤:
(1)顶点v入队列。
(2)当队列非空时则继续执行,否则算法结束。
(3)出队列取得队头顶点v;访问顶点v并标记顶点v已被访问。
(4)查找顶点v的第一个邻接顶点col。
(5)若v的邻接顶点col未被访问过的,则col入队列。
(6)继续查找顶点v的另一个新的邻接顶点col,转到步骤(5)。直到顶点v的所有未被访问过的邻接点处理完。转到步骤(2)。
实现代码:
from pythonds.graphs import Graph, Vertex
from pythonds.basic import Queue
def bfs(g,start):
start.setDistance(0)
start.setPred(None)
vertQueue = Queue()
vertQueue.enqueue(start)
while (vertQueue.size() > 0):
currentVert = vertQueue.dequeue()
for nbr in currentVert.getConnections():
if (nbr.getColor() == 'white'):
nbr.setColor('gray')
nbr.setDistance(currentVert.getDistance() + 1)
nbr.setPred(currentVert)
vertQueue.enqueue(nbr)
currentVert.setColor('black')搜索过程如下图所示,初始点是白色,探索点是灰色,终结点是黑色



4.2 深度优先搜索
实现步骤:
(1)访问初始顶点v并标记顶点v已访问。
(2)查找顶点v的第一个邻接顶点w。
(3)若顶点v的邻接顶点w存在,则继续执行;否则回溯到v,再找v的另外一个未访问过的邻接点。
(4)若顶点w尚未被访问,则访问顶点w并标记顶点w为已访问。
(5)继续查找顶点w的下一个邻接顶点wi,如果v取值wi转到步骤(3)。直到连通图中所有顶点全部访问过为止。
实现代码:
由于 dfs 和它的辅助函数dfsvisit 这两个函数使用一个变量来跟踪调用 dfsvisit 的时间,所以我们选择将代码实现为继承自 Graph 类。此实现通过添加时间实例变量和两个方法 dfs 和 dfsvisit来扩展 Graph 类。看看第 11 行,你会注意到,dfs 方法在调用 dfsvisit 的图中所有的顶点迭代,这些节点是白色的。我们迭代所有节点而不是简单地从所选择的起始节点进行搜索的原因是为了确保图中的所有节点都被考虑到,没有顶点从深度优先森林中被遗漏。for aVertex in self 语句可能看起来不寻常,但请记住,在这种情况下,self是 DFSGraph 类的一个实例,遍历实例中的所有顶点是一件自然的事情。代码如下:
from pythonds.graphs import Graph
class DFSGraph(Graph):
def __init__(self):
super().__init__()
self.time = 0
def dfs(self):
for aVertex in self:
aVertex.setColor('white')
aVertex.setPred(-1)
for aVertex in self:
if aVertex.getColor() == 'white':
self.dfsvisit(aVertex)
def dfsvisit(self,startVertex):
startVertex.setColor('gray')
self.time += 1
startVertex.setDiscovery(self.time)
for nextVertex in startVertex.getConnections():
if nextVertex.getColor() == 'white':
nextVertex.setPred(startVertex)
self.dfsvisit(nextVertex)
startVertex.setColor('black')
self.time += 1
startVertex.setFinish(self.time)搜索过程如下图所示,初始点是白色,探索点是灰色,终结点是黑色



下图展示了由深度优先搜索算法构造的树:

参考资料:《problem-solving-with-algorithms-and-data-structure-using-python》
http://www.pythonworks.org/pythonds
python 实现图的深度优先和广度优先搜索的更多相关文章
- 图的遍历BFS广度优先搜索
图的遍历BFS广度优先搜索 1. 简介 BFS(Breadth First Search,广度优先搜索,又名宽度优先搜索),与深度优先算法在一个结点"死磕到底"的思维不同,广度优先 ...
- 图的深度优先和广度优先遍历(图以邻接表表示,由C++面向对象实现)
学习了图的深度优先和广度优先遍历,发现不管是教材还是网上,大都为C语言函数式实现,为了加深理解,我以C++面向对象的方式把图的深度优先和广度优先遍历重写了一遍. 废话不多说,直接上代码: #inclu ...
- 【数据结构与算法Python版学习笔记】图——词梯问题 广度优先搜索 BFS
词梯Word Ladder问题 要求是相邻两个单词之间差异只能是1个字母,如FOOL变SAGE: FOOL >> POOL >> POLL >> POLE > ...
- 图的深度优先遍历&广度优先遍历
1.什么是图的搜索? 指从一个指定顶点可以到达哪些顶点 2.无向完全图和有向完全图 将具有n(n-1)/2条边的无向图称为无向完全图(完全图就是任意两个顶点都存在边). 将具有n(n-1)条边的有 ...
- 第六章 图(c)广度优先搜索
- [MIT6.006] 13. Breadth-First Search (BFS) 广度优先搜索
一.图 在正式进入广度优先搜索的学习前,先了解下图: 图分为有向图和无向图,由点vertices和边edges构成.图有很多应用,例如:网页爬取,社交网络,网络传播,垃圾回收,模型检查,数学推断检查和 ...
- python实现广度优先搜索和深度优先搜索
图的概念 图表示的是多点之间的连接关系,由节点和边组成.类型分为有向图,无向图,加权图等,任何问题只要能抽象为图,那么就可以应用相应的图算法. 用字典来表示图 这里我们以有向图举例,有向图的邻居节点是 ...
- 常用算法2 - 广度优先搜索 & 深度优先搜索 (python实现)
1. 图 定义:图(Graph)是由顶点的有穷非空集合和顶点之间边的集合组成,通常表示为:G(V,E),其中,G表示一个图,V是图G中顶点的集合,E是图G中边的集合. 简单点的说:图由节点和边组成.一 ...
- python数据结构之图深度优先和广度优先实例详解
本文实例讲述了python数据结构之图深度优先和广度优先用法.分享给大家供大家参考.具体如下: 首先有一个概念:回溯 回溯法(探索与回溯法)是一种选优搜索法,按选优条件向前搜索,以达到目标.但当探索到 ...
随机推荐
- 2017-6-5/MySQL分库分表
分库分表,顾名思义,就是把原本存储于一个库一张表的数据分块存储到多个库多张表上.对于大型互联网应用来说,当一张表的数据量达到百万.千万时,数据库每执行一次查询所花的时间会变多,并且数据库面临着极高的并 ...
- Echarts 简单报表系列一:柱状图
见代码: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF- ...
- element-ui 表格翻页多选,数据回显
reserve-selection与row-key结合 <el-table :data="pageData" ref="goodsTable" size= ...
- js之DOM元素遍历
对于元素间的空格,IE9之前的版本不会返回文本节点,而且他所有浏览器都会返回文本节点.这样就导致 使用childNodes和firstChild等属性时的行为不一致.从而有了Element Trave ...
- ID基本操作(新建文档,页面编码)5.8
“文件”“新建”“文档”选择页数,页面大小.页面方向,“边距和分栏”设置上下左右的边距,栏数,如三栏 还可以改变分栏距离·改变排版方向,如图,垂直 单击“页面”可以查看我们的页面情况 超过两页会可以看 ...
- go语言byte类型报错cannot use "c" (type string) as type byte in assignment
练习Go修改字符串的时候遇到这个问题:cannot use "c" (type string) as type byte in assignment,代码如下: package m ...
- Spring框架基本代码
1.准备阶段: 2.基本引入: 接口: package com.xk.spring.kp01_hello; public interface IHello { public void nice(); ...
- docker(三)容器的基本操作
下载镜像 docker pull name 基本启动容器 docker run IMAGE command args run 在新容器中运行 IMAGE 镜像名称 command 容器命令 args ...
- java项目性能测试过程记录
一 准备环境和指标 1.主机三台(linux,这里显示的都是伪主机地址):最好用干净的机子,做性能测试的时候别装其他东西在上面跑. 100.22.0.98 部署自己的项目服务 100.22.0.9 ...
- 《Python》网络编程之黏包
黏包 一.黏包现象 同时执行多条命令之后,得到的结果很可能只有一部分,在执行其他命令的时候又接收到之前执行的另外一部分结果,这种显现就是黏包. server端 import socket sk = s ...