R语言——实验5-聚类分析
- 针对课件中的例子自己实现k-means算法
- 调用R语言自带kmeans()对给定数据集表示的文档进行聚类。
- 给定数据集:
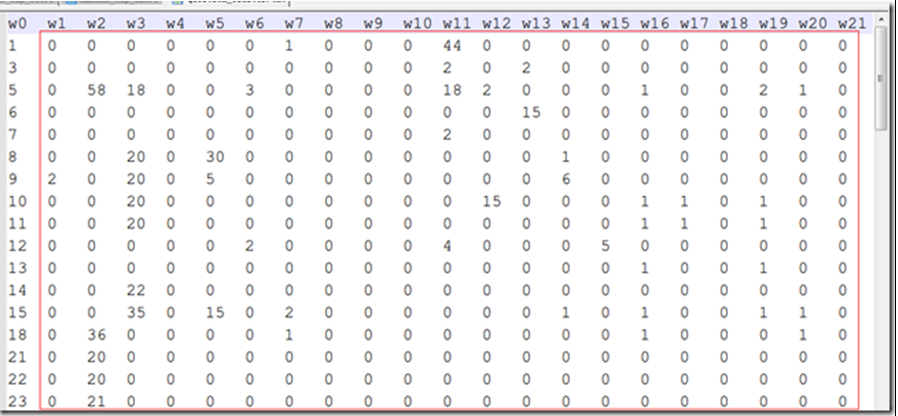
a) 数据代表的是文本信息。
b) 第一行代表词语,由于保密原因,词语已经被转意。第一列代表了文本的编号。
c) 红框中的数字为对应词的词频。
共113个样本,用K-Means算法将样本分为8类。
1、针对课件中的例子自己实现k-means算法
rm(list=ls())
#导入数据 id<-c(1:8)
x<-c(1,2,1,2,4,5,4,5)
y<-c(1,1,2,2,3,3,4,4)
inputdata<-data.frame(id,x,y) #计算距离函数
cal_distance<-function(x1,y1,x2,y2){
dis=(x1-x2)*(x1-x2)+(y1-y2)*(y1-y2)
dis=sqrt(dis)
return(dis)
} #假定随机选择的两个对象,如序号1和序号3当作初始点
center1=matrix(c(inputdata[1,2],inputdata[1,3]))
center2=matrix(c(inputdata[3,2],inputdata[3,3])) #一开始两个簇都是空的
cu1<-c()
cu2<-c() for(time in 1:5)
{
#遍历每一个点
for(i in 1:length(inputdata$id))
{
distance1=cal_distance(inputdata$x[i],inputdata$y[i],center1[1],center1[2])
distance2=cal_distance(inputdata$x[i],inputdata$y[i],center2[1],center2[2])
if(distance1<=distance2)
{
cu1<-c(cu1,i)
}
else
{
cu2<-c(cu2,i)
}
} #更新簇1的质心
sx=0
sy=0
for(i in 1:length(cu1))
{
sx=sx+inputdata$x[cu1[i]]
sy=sy+inputdata$y[cu1[i]]
}
center1[1]=sx*1.0/length(cu1)
center1[2]=sy*1.0/length(cu1) #更新簇2的质心
sx=0
sy=0
for(i in 1:length(cu2))
{
sx=sx+inputdata$x[cu2[i]]
sy=sy+inputdata$y[cu2[i]]
}
if(center2[1]==sx*1.0/length(cu2)&¢er2[2]==sy*1.0/length(cu2))
{
break
}
center2[1]=sx*1.0/length(cu2)
center2[2]=sy*1.0/length(cu2)
cu1<-c()
cu2<-c()
} cat("簇1质心: ",center1[1]," ",center1[2])
print("簇1包含的元素有: ")
for(i in 1:length(cu1))
{
print(cu1[i])
}
print("")
cat("簇2质心: ",center2[1]," ",center2[2])
print("")
print("簇1包含的元素有: ")
for(i in 1:length(cu2))
{
print(cu2[i])
}

2、 调用R语言自带kmeans()对给定数据集表示的文档进行聚类。
rm(list=ls())
setwd("C:/Users/Administrator/Desktop/R语言与数据挖掘作业/实验5-聚类分析")
data = read.table("data_cluster.txt")
kc <- kmeans(data, 8) #分类模型训练
print(kc)
#fitted(kc) #查看具体分类情况
#table(data$Species, data$cluster)#查看分类概括
R语言——实验5-聚类分析的更多相关文章
- R语言——实验4-人工神经网络
带包实现: rm(list=ls()) setwd("C:/Users/Administrator/Desktop/R语言与数据挖掘作业/实验4-人工神经网络") Data=rea ...
- R语言- 实验报告 - 利用R语言脚本与Java相互调用
一. 实训内容 利用R语言对Java项目程序进行调用,本实验包括利用R语言对java的.java文件进行编译和执行输出. 在Java中调用R语言程序.本实验通过eclipse编写Java程序的方式,调 ...
- R语言简单实现聚类分析计算与分析(基于系统聚类法)
聚类分析计算与分析(基于系统聚类法) 下面以一个具体的例子来实现实证分析.2008年我国其中31个省.市和自治区的农村居民家庭平均每人全年消费性支出. 根据原始数据对我国省份进行归类统计. 原始数据如 ...
- R语言 实验三 数据探索和预处理
计算缺失值个数 计算缺失率 简单统计量:计算最值 箱形图分析 分布分析:画出频率直方图 统计量分析:对于连续属性值,求出均值以及标准差 缺失值处理:删除法 去除 ...
- 社交网络分析的 R 基础:(一)初探 R 语言
写在前面 3 年的硕士生涯一转眼就过去了,和社交网络也打了很长时间交道.最近突然想给自己挖个坑,想给这 3 年写个总结,画上一个句号.回想当时学习 R 语言时也是非常戏剧性的,开始科研生活时到处发邮件 ...
- 用R语言对NIPS会议文档进行聚类分析
一.用R语言建立文档矩阵 (这里我选用的是R x64 3.2.2) (这里我取的是04年NIPS共计207篇文档做分析,其中文档内容已将开头的作者名和最后的参考文献进行过滤处理) ##1.Data I ...
- 实验的方差分析(R语言)
实验设计与数据处理(大数据分析B中也用到F分布,故总结一下,加深印象)第3课小结--实验的方差分析(one-way analysis of variance) 概述 实验结果\(S\)受多个因素\(A ...
- 独立成分分析(ICA)的模拟实验(R语言)
本笔记是ESL14.7节图14.42的模拟过程.第一部分将以ProDenICA法为例试图介绍ICA的整个计算过程:第二部分将比较ProDenICA.FastICA以及KernelICA这种方法,试图重 ...
- 数据分析与R语言
数据结构 创建向量和矩阵 函数c(), length(), mode(), rbind(), cbind() 求平均值,和,连乘,最值,方差,标准差 函数mean(), sum(), min(), m ...
随机推荐
- Fedora初体验
========1. 下载https://getfedora.org/zh_CN/workstation/download/下载如下2个文件:Fedora-Workstation-Live-x86_6 ...
- 20165313 《Java程序设计》第四周学习总结
教材学习总结 public:1.用在类前.2.用在方法前 .3. 用在成员变量前 private:用在成员变量前 final1.用在类前2.用在方法前3.用在成员变量前 static:1.所有对象公有 ...
- Java中break和continue跳出指定循环
https://www.cnblogs.com/miys/p/b7f6a463bc58785d74a8a7fccd1f1243.html 在Java中,break和continue可以跳出指定循环,在 ...
- Docker网络解决方案-Flannel(转)
转自https://www.cnblogs.com/kevingrace/p/6859114.html Docker跨主机容器间网络通信实现的工具有Pipework.Flannel.Weave.Ope ...
- [转]java虚拟机工作原理详解
一.类加载器 首先来看一下java程序的执行过程. 从这个框图很容易大体上了解java程序工作原理.首先,你写好java代码,保存到硬盘当中.然后你在命令行中输入 javac YourClassNam ...
- webpack 中的 chunk 种类
webpack 将 chunk 划分为三类: 入口 chunk.入口 chunk 包含 webpack runtime 和将要加载的模块. 普通 chunk.普通 chunk 不包含 webpack ...
- netBeans 修改新建php文件头部注释模板
用Netbeans(版本8.2)写php配置模板,模板配置好,可以省很多事,方便开发,而且,显得很专业. 新建php文件时: <?php /** * Encoding : UTF-8 * Cre ...
- python引入自定义模块
Python的包搜索路径 Python会在以下路径中搜索它想要寻找的模块:1. 程序所在的文件夹2. 标准库的安装路径3. 操作系统环境变量PYTHONPATH所包含的路径 将自定义库的路径添加到Py ...
- 关于svm
svm的研究一下,越研究越发现深入.下面谈一些我个人一些拙见. svm计算基础是逻辑回归(logistic regression),其实一切二元分类的鼻祖我觉得都是logistic regress. ...
- Redis set数据结构
set里的数据不能重复 1. 增加set1,值为 a b c d 1 2 3 2. 返回集合元素的数量 3. 重命名set1为set100 4. 查看集合中的成员 5.sdiff set100 set ...