Hive 企业调优
9.企业级调优
9.1 Fetch 抓取
- Fetch 抓取:Hive 中对某些情况的查询可以不必使用 MapReduce 计算;
hive.fetch.task.conversion:more
9.2 本地模式
- 大多数的 Hadoop Job 是需要 Hadoop 提供完整的可扩展性来处理大数据集的。不过,有时 Hive 的输入数据量是非常小的。在这种情况下,为查询触发执行任务消耗的时间可能会比实际job的执行时间要多的多。对于大多数这种情况,Hive 可以通过本地模式在单台机器上处理所有的任务。对于小数据集,执行时间可以明显被缩短。
hive.exec.mode.local.auto:true
9.3 表的优化
9.3.1 小表Join大表
- 实际测试发现:新版的 hive 已经对小表JOIN大表和大表JOIN小表进行了优化,小表放在左边和右边已经没有明显区别;
9.3.2 大表Join大表
- 第一种方式:查询之前,过滤Null
select n.* from (select * from nullidtable where id is not null) n left join bigtable o on n.id = o.id;
- 第二种方式:给Null的赋值
- 需要避免数据倾斜,所以使用
rand(); select n.* from nullidtable n full join bigtable o on case when n.id is null then concat('hive', rand()) else n.id end = o.id;
- 需要避免数据倾斜,所以使用
9.3.3 MapJoin
- 如果不指定 MapJoin 或者不符合 MapJoin 的条件,那么 Hive 解析器会将 Join 操作转换成 Common Join,即:在Reduce阶段完成join,容易发生数据倾斜。可以用 MapJoin 把小表全部加载到内存,在 map 端进行 join,避免 reducer 处理。
- 开启
MapJoin参数设置:- 开启自动选择 MapJoin:
set hive.auto.convert.join=true;,默认为true; - 设置大表小表的阈值(默认25M 以下就是小表):
set hive.mapjoin.smalltable.filesize=25000000;
- 开启自动选择 MapJoin:
- MapJoin 工作机制:
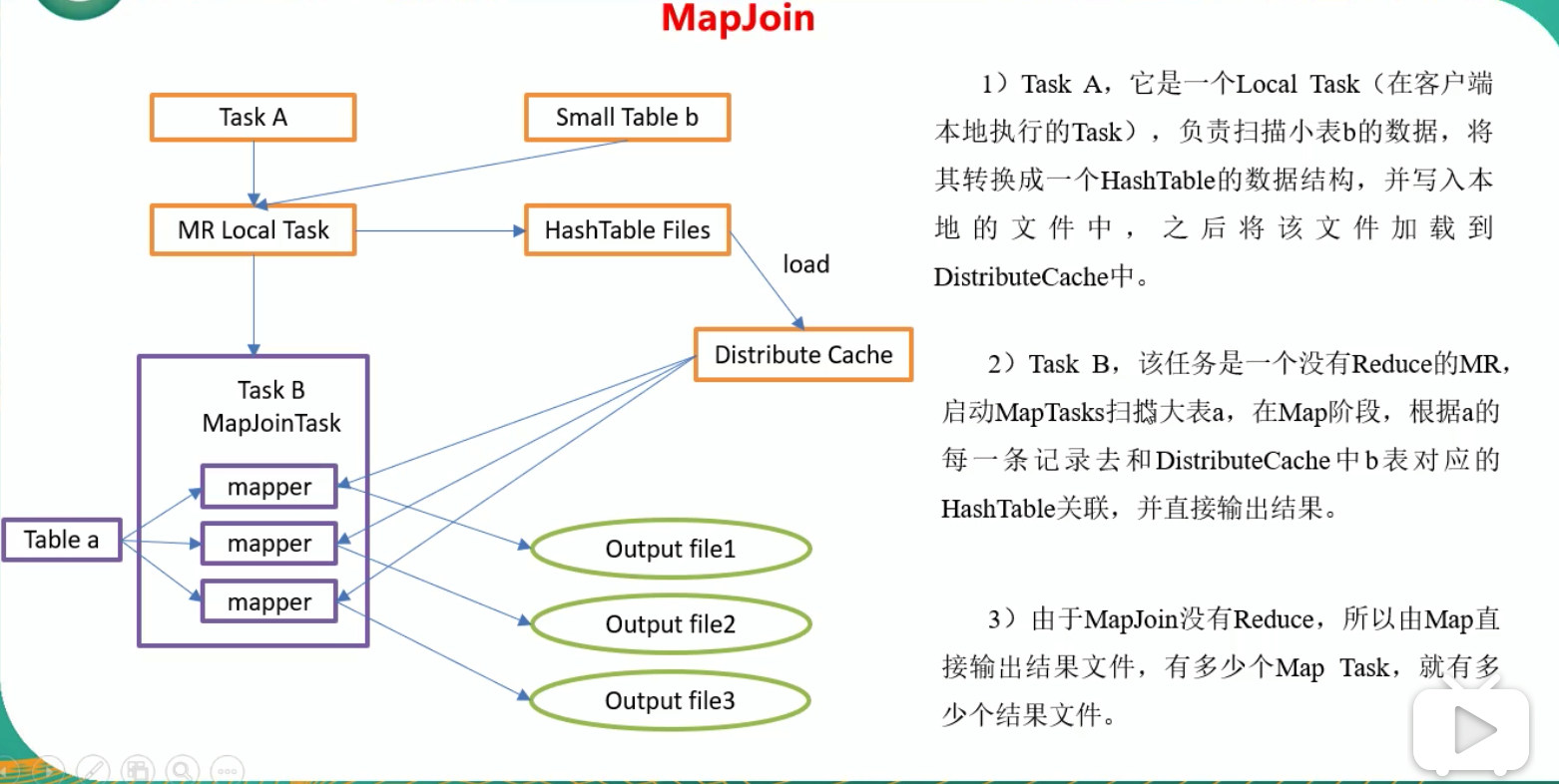
9.3.4 Group By
- 默认情况下,Map 阶段同一 Key 数据分发给一个 reduce,当一个 key 数据过大时,就可能发生数据倾斜;
- 并不是所有的聚合操作都需要在 Reduce 端完成,很多聚合操作都可以现在 Map 端进行部分聚合,最后在 Reduce 端得出最终结果。
- 开启 Map 端聚合参数设置:
- 是否在 Map 端进行聚合,默认为true:
hive.map.aggr=true; - 在 Map 端进行聚合操作的条目数目:
hive.groupby.mapaggr.checkinterval=100000; - 有数据倾斜的时候,进行负载均衡:
hive.groupby.skewindata=true;
- 是否在 Map 端进行聚合,默认为true:
9.3.5 Count(Distinct)去重统计
- 数据量大的情况下,由于 COUNT DISTINCT 操作需要用一个Reduce Task 来完成,这一个 Reduce 需要处理的数据量太大,就会导致整个 Job 很难完成,一般 COUNT DISTINCT 使用时,先 GROUP BY 再 COUNT 的方式替换;
9.3.6 动态分区调整
- 关系型数据库中,对分区表Insert数据的时候,数据库自动会根据分区字段的值,将数据插入到相应的分区中,Hive 中也提供了类似的机制,即动态分区(Dynamic Partition);
- 开启动态分区参数设置:
- 开启动态分区功能,默认为true:
hive.exec.dynamic.partition=true; - 设置为非严格模式(默认为strict,即必须指定至少一个分区为静态分区,nonstrict模式表示允许所有的分区字段都可以使用动态分区):
hive.exec.dynamic.partition.mode=nonstrict; - 在所有执行 MR 的节点上,最大一共可以创建多少个动态分区:
hive.exec.max.dynamic.partitions=1000; - 在每个执行 MR 的节点上,最大可以创建多少个动态分区:
hive.exec.max.dynamic.partitions.pernode=100; - 整个 MR Job中,最大可以创建多少个HDFS文件:
hive.exec.max.created.files=100000; - 当有空分区生成时,是否抛出异常:
hive.error.on.empty.partition=false;
- 开启动态分区功能,默认为true:
Hive 企业调优的更多相关文章
- 数据迁移过程中hive sql调优
本文记录的是,在数据处理过程中,遇到了一个sql执行很慢,对一些大型的hive表还会出现OOM,一步一步通过参数的设置和sql优化,将其调优的过程. 先上sql ) t where t.num =1) ...
- Hive(十)Hive性能调优总结
一.Fetch抓取 1.理论分析 Fetch抓取是指,Hive中对某些情况的查询可以不必使用MapReduce计算.例如:SELECT * FROM employees;在这种情况下,Hive可以简单 ...
- Hive参数调优
调优 Hive提供三种可以改变环境变量的方法,分别是: (1)修改${HIVE_HOME}/conf/hive-site.xml配置文件: 所有的默认配置都在${HIVE_HOME}/conf/hiv ...
- hive tez调优(3)
根据.方案最右侧一栏是一个8G VM的分配方案,方案预留1-2G的内存给操作系统,分配4G给Yarn/MapReduce,当然也包括了HIVE,剩余的2-3G是在需要使用HBase时预留给HBase的 ...
- hive的调优
调优 1 Fetch抓取(Hive可以避免进行MapReduce) Hive中对某些情况的查询可以不必使用MapReduce计算.例如:SELECT * FROM employees;在这种情况下,H ...
- 06hive企业调优
一.Fetch抓取 Fetch抓取是指,Hive 中对某些情况的查询可以不必使用MapReduce计算. 在 hive-default.xml.template 文件中 hive.fetch.task ...
- 关于Hive的调优(本身,sql,mapreduce)
1.关于hive的优化 ->大表拆分小表 ->过滤字段 ->按字段分类存放 ->外部表与分区表 ->外部表:删除时只删除元数据信息,不删除数据文件 多人使用多个外部表操作 ...
- 060 关于Hive的调优(本身,sql,mapreduce)
1.关于hive的优化 ->大表拆分小表 ->过滤字段 ->按字段分类存放 ->外部表与分区表 ->外部表:删除时只删除元数据信息,不删除数据文件 多人使用多个外部表操作 ...
- Hive 性能调优
避免执行MR select * or select field1,field2 limit 10 where语句中只有分区字段或该表的本地字段 使用本地set hive.exec.mode.local ...
随机推荐
- 《挑战30天C++入门极限》C++类对象的复制-拷贝构造函数
C++类对象的复制-拷贝构造函数 在学习这一章内容前我们已经学习过了类的构造函数和析构函数的相关知识,对于普通类型的对象来说,他们之间的复制是很简单的,例如: int a = 10; int ...
- Python逆向(一)—— 前言及Python运行原理
一.前言 最近在学习Python逆向相关,涉及到python字节码的阅读,编译及反汇编一些问题.经过长时间的学习有了一些眉目,为了方便大家交流,特地将学习过程整理,形成了这篇专题.专题对python逆 ...
- xftp实现本地与服务器的文件上传下载(windows)
背景: Jemter环境搭建,需上传下载服务器文件到aws服务器上,由于secureCRT的局限性它只支持pub格式的密钥,不支持pem格式密钥,xshell是支持pem格式的,所以尝试安装xshel ...
- 信竞四定律orz
正常代码不写#define @zdx 平时刷题不写freopen @liuziwen 循环内部不写return 0 @asdfo123 主程序内不写char array @asdfo123 输出时间: ...
- JVM命令行参数
root@ubuntu-blade2:/sdf/jdk# javaUsage: java [-options] class [args...] (to execute a class) or java ...
- 大数据学习之路之HBASE
Hadoop之HBASE 一.HBASE简介 HBase是一个开源的.分布式的,多版本的,面向列的,半结构化的NoSql数据库,提供高性能的随机读写结构化数据的能力.它可以直接使用本地文件系统,也可以 ...
- CSS(1)
使用CSS的注意点: 1.style标签必须写在head标签的开始标签和结束标签之间(也就是必须和title标签是兄弟关系). 2.style标签中的type属性其实可以不用写,默认就是type=&q ...
- Audit(二)--清理Audit数据
(一) 概述 Audit的数据主要存储在sys.aud$表中,该表默认位于system表空间中,我们根据需求,将该表移到了sysaux表空间中.由于审计数据量较大,需要经常关注sysaux表空间的使用 ...
- HearthBuddy中的class276中的地址对应
2019年09月的 intptr_0 = method_18("mono.dll"); intptr_31 = intptr_0 + 522030; intptr_28 = int ...
- currency
currency 美 ['kʌrənsi] 英 ['kʌrənsi] n.货币:通货:通用:流行 网络流通:货币型:币种