批处理引擎MapReduce应用案例
批处理引擎MapReduce应用案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
MapReduce能够解决的问题有一个共同特点:任务可以被分解为多个子问题,且这些子问题相对独立,彼此之间不会有牵制,待并行处理完成这些子问题后,总的问题便被解决。
在实际应用中,这类问题非常庞大,谷歌在论文中提到一些MapReduce的典型应用,包括分布式grep,URL访问频率统计,Web链接图反转,倒排索引构建,分布式排序等,这些均为比较简单的应用。下面介绍一些比较复杂应用。
一.Top K问题
在搜索引擎领域中,常常需要统计最近最热门的K个查询词,这就是典型的“Top K”问题,也就是从海量查询中统计出现频率最高的前K个。
该问题可分解成两个MapReduce作业,分别完成统计词频和找出词频最高的前K个查询词的的功能,另两个作业存在以来关系,第二个作业需要依赖前一个作业输出的结果。第一个作业是典型的WorldCount问题。对于第二个作业,首先map函数输出前K个频率最高的词,然后在reduce函数中汇总每个Map任务得到的前K个查询词,并输出频率最高的前K个查询只。
二.K-means聚类
K-means是一种基于距离的聚类算法,它采用距离作为相似性的评价指标,认为两个对象的距离越近,其相似度就越大,该算法解决的问题可抽象成:给定正整数k和n个对象,如何将这些数据点划分为k个聚类?
该问题采用MapReduce计算思路如下,首先随机选择k个对象作为初始中心点,然后不断迭代计算,直到满足终止条件(达到迭代次数上限或者数据点到中心点距离平方和最小),在第i轮迭代中,map函数计算每个对象到中心点的距离,选择距每个对象(object)最近的中心点(center_point),并输出<center_point,object>对。reduce函数计算每个聚类中对象的距离均值,并将这k个均值作为下一轮初始中心点。
三.贝叶斯分类
贝叶斯分类是一种利用概率统计知识进行分裂的统计学分方法。该方法包括两个步骤:训练样本和分类。 其实现由多个MapReduce作业完成,具体如下图所示。
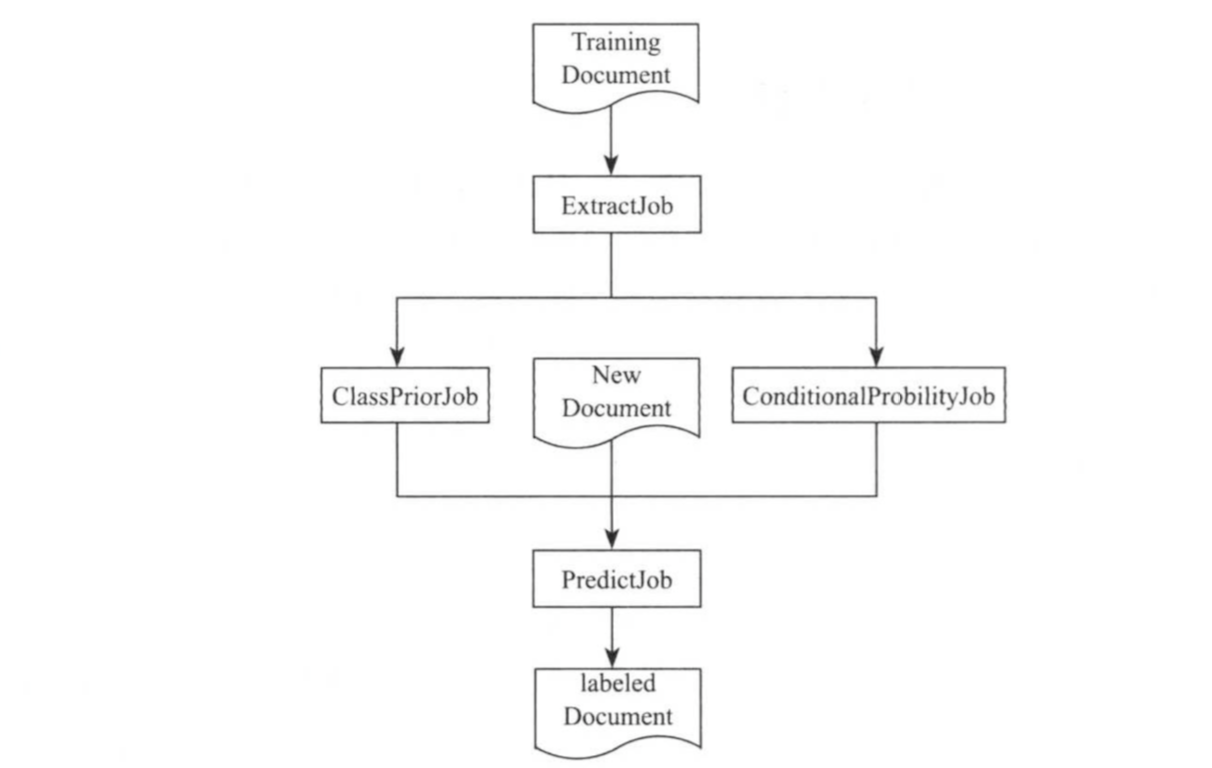
其中,训练样本可由三个MapReduce作业完成:
()第一个作业(ExtractJob)抽取文档特征,该作业只需要Map即可完成;
()第二个作业(ClassPriorJob)计算类别的先验概率,即统计每个类别中文档的数目,并计算类别概率;
()第三个作业(CondititionProbilityJob)计算单词的条件概率,即统计<label,word>在所有文档中出现的次数并计算单词的条件概率;
后两个作业的具体实现类似于WordCount。分类过程有一个作业(PredictJob)完成,该作业的map函数计算每个待分类文档属于每个类别的概率,reduce函数找到每个文档概率最高的类别,并输出<docid,label>(编号为docid的文档属于类别label)。
四.MapReduce不能解决或者难以解决的问题
1>.Fibonacci数值计算
Fibonacci数值计算时,下一个结果需要依赖前面的计算结果,也就是说,无法将该问题划分成若干个互不相干的子问题,因而不能够用MapReduce解决。
2>. 层次聚类法
层次聚类法是应用最广泛的聚类算法之一,按采用“自顶向下”和“自底向上”两种方式,可将其分解为分解型层次聚类法两种。层次聚类方法采用迭代控制策略,使聚类逐步优化。它按照一定的相似性(一般是距离)判断标准,合并最相似的部分或者分隔最不相似的部分。以分解型层次聚类算法为例,其主要思想是,初始时,将每个对象归为一类,然后不断迭代,直到所有对象合并成一个大类(或者达到某个终止条件),在每轮迭代时,需要计算两两对象间的距离,并合并距离最近的两个对象为一类。
该算法需要计算两两对象间的距离,也就说每个对象和其他对象均有关联,因而该问题不能被分解成若干个子问题,进而不能用MapReduce解决。
批处理引擎MapReduce应用案例的更多相关文章
- 批处理引擎MapReduce编程模型
批处理引擎MapReduce编程模型 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. MapReduce是一个经典的分布式批处理计算引擎,被广泛应用于搜索引擎索引构建,大规模数据处理 ...
- 批处理引擎MapReduce程序设计
批处理引擎MapReduce程序设计 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce API Hadoop同时提供了新旧两套MapReduce API,新AP ...
- 大数据系列之分布式计算批处理引擎MapReduce实践-排序
清明刚过,该来学习点新的知识点了. 上次说到关于MapReduce对于文本中词频的统计使用WordCount.如果还有同学不熟悉的可以参考博文大数据系列之分布式计算批处理引擎MapReduce实践. ...
- 批处理引擎MapReduce内部原理
批处理引擎MapReduce内部原理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.MapReduce作业生命周期 MapReduce作业作为一种分布式应用程序,可直接运行在H ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- MapReduce 使用案例
MapReduce 使用案例 MapReduce在面试过程中出现的频率还是挺高的,尤其是数据挖掘等岗位.通常面试官会出一个大数据题目,需要被试者根据题目设计基于MapReduce的算法来解答.我在一个 ...
- 大数据笔记(十)——Shuffle与MapReduce编程案例(A)
一.什么是Shuffle yarn-site.xml文件配置的时候有这个参数:yarn.nodemanage.aux-services:mapreduce_shuffle 因为mapreduce程序运 ...
- MapReduce应用案例
1 环境说明 注意:本实验是对前述实验的延续,如果直接点开始实验进入则需要按先前学习的方法启动hadoop 部署节点操作系统为CentOS,防火墙和SElinux禁用,创建了一个shiyanlou用户 ...
- MapReduce应用案例--单表关联
1. 实例描述 单表关联这个实例要求从给出的数据中寻找出所关心的数据,它是对原始数据所包含信息的挖掘. 实例中给出child-parent 表, 求出grandchild-grandparent表. ...
随机推荐
- matlab学习笔记7-定时器
一起来学matlab-matlab学习笔记7-定时器 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考书籍 <matlab 程序设计与综合应用>张德丰等著 感谢张老师的书籍,让 ...
- 查找k8s版jenkins-slave官方镜像
官方镜像非常多,如果查找某个单词没有找到的话,可以换一个词查找,总之各种非常的多,带maven.djk.kubectl工具的镜像,都去试试吧, 从下面查找结果中可以看到,还有centos版的jenki ...
- web基础---->session的使用
前几天在博问中,看到有人提到了有关session的问题,决定自己整理写一下有关session的原理!说起session,cookie必须是要谈的! 目录 Cookie的介绍 Cookie的使用 Ses ...
- 最新 途牛java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.途牛等10家互联网公司的校招Offer,因为某些自身原因最终选择了途牛.6.7月主要是做系统复习.项目复盘.LeetCode ...
- Idea破解到2100年的简单方法
第一步下载IntelliJ IDEA 2018.1.6版本,比这个更新的版本得你自己找注册码,因为旧的注册码对最新版本的软件不管用,所以建议还是下载这个版本,或者这个版本之前的也可以: 地址:http ...
- 对JAVA工程师绝对有用的Java学习资源清单
学习Java和其他技术的资源其实非常多,但也不是都是好的有用的,我们要取其精华去其糟粕,选择那些最好的,最适合我们的,同时也要由浅入深,先易后难.基于这样的一个标准,我在这里为大家提供一份Java的学 ...
- Dubbo快速入门 一
1.分布式基础理论 1.1).什么是分布式系统? “分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统” 分布式系统(distributed system)是建立在网络之上的软件 ...
- 【C#】上机实验六
. 定义Car类,练习Lambda表达式拍序 ()Car类中包含两个字段:name和price: ()Car类中包含相应的属性.构造函数及ToString方法: ()在Main方法中定义Car数组,并 ...
- 面试4 --- constructor必须与class同名,但方法不能与class同名?
选 C “constructor必须与class同名,但方法不能与class同名”这句话是错误的,方法是可以和class同名的:方法可以和类名同名的,和构造方法唯一的区别就是,构造方法没有返回值.
- 玩转Spring全家桶笔记 04 Spring的事务抽象、事务传播特性、编程式事务、申明式事务
1.Spring 的事务抽象 Spring提供了一致的事务模型 JDBC/Hibernate/Mybatis 操作数据 DataSource/JTA 事务 2.事务抽象的核心接口 PlatformTr ...