MapReduce Shuffle过程
MapReduce Shuffle 过程详解
一、MapReduce Shuffle过程
1、 Map
Shuffle过程
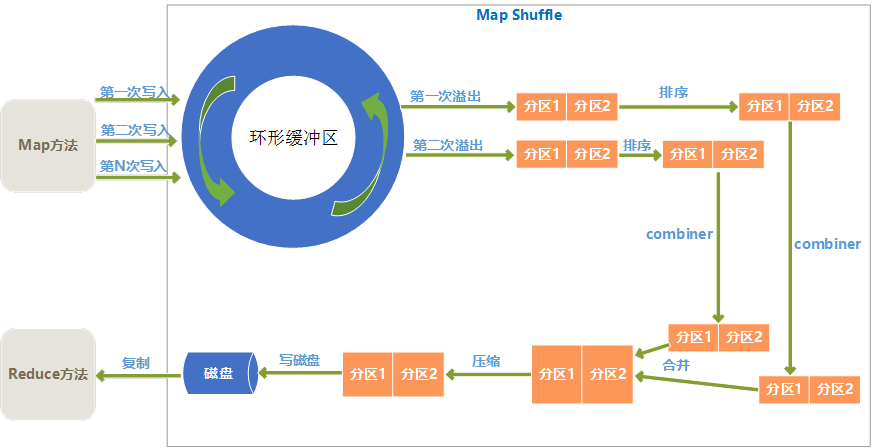
2、 Reduce
Shuffle过程

二、Map Shuffle过程
1、 环形缓冲区
Map输出结果是先放入内存中的一个环形缓冲区,这个环形缓冲区默认大小为100M(这个大小可以在io.sort.mb属性中设置),当环形缓冲区里的数据量达到阀值时(这个值可以在io.sort.spill.percent属性中设置)就会溢出写入到磁盘,环形缓冲区是遵循先进先出原则,Map输出一直不停地写入,一个后台进程不时地读取后写入磁盘,如果写入速度快于读取速度导致环形缓冲区里满了时,map输出会被阻塞直到写磁盘过程结束。
2、 分区
从环形缓冲区溢出到磁盘过程,是将数据写入mapred.local.dir属性指定目录下的特定子目录的过程。
但是在真正写入磁盘之前,要进行一系列的操作,首先就是对于每个键,根据规则计算出来将来要输出到哪个reduce,根据reduce不同分不同的区,分区是在内存里分的,分区的个数和将来的reduce个数是一致的。
3、 排序
在每个分区上,会根据键进行排序。
4、 combiner
combiner方法是对于map输出的结果按照业务逻辑预先进行处理,目的是对数据进行合并,减少map输出的数据量。
排序后,如果指定了conmbiner方法,就运行combiner方法使得map的结果更紧凑,从而减少写入磁盘和将来网络传输的数据量。
5、 合并溢出文件
环形缓冲区每次溢出,都会生成一个文件,所以在map任务全部完成之前,会进行合并成为一个溢出文件,每次溢出的各个文件都是按照分区进行排好序的,所以在合并文件过程中,也要进行分区和排序,最终形成一个已经分区和排好序的map输出文件。
在合并文件时,如果文件个数大于某个指定的数量(可以在min.num.spills.for.combine属性设置),就会进再次combiner操作,如果文件太少,效果和效率上,就不值得花时间再去执行combiner来减少数据量了。
6、 压缩
Map输出结果在进行了一系列的分区、排序、combiner合并、合并溢出文件后,得到一个map最终的结果后,就应该真正存储这个结果了,在存储之前,可以对最终结果数据进行压缩,一是可以节约磁盘空间,而是可以减少传递给reduce时的网络传输数据量。
默认是不进行压缩的,可以在mapred.compress.map.output属性设置为true就启用了压缩,而压缩的算法有很多,可以在mapred.map.output.compression.codec属性中指定采用的压缩算法,具体压缩详情,可以看本文的后面部分的介绍。
三、Reduce Shuffle过程
1、 复制数据
各个map完成时间肯定是不同的,只要有一个map执行完成,reduce就开始去从已完成的map节点上复制输出文件中属于它的分区中的数据,reduce端是多线程并行来复制各个map节点的输出文件的,线程数可以在mapred.reduce.parallel.copies属性中设置。
reduce将复制来的数据放入内存缓冲区(缓冲区大小可以在mapred.job.shuffle.input.buffer.percent属性中设置)。当内存缓冲区中数据达到阀值大小或者达到map输出阀值,就会溢写到磁盘。
写入磁盘之前,会对各个map节点来的数据进行合并排序,合并时如果指定了combiner,则会再次执行combiner以尽量减少写入磁盘的数据量。为了合并,如果map输出是压缩过的,要在内存中先解压缩后合并。
2、 合并排序
合并排序其实是和复制文件同时并行执行的,最终目的是将来自各个map节点的数据合并并排序后,形成一个文件。
3、 分组
分组是将相同key的键值对分为一组,一组是一个列表,列表中每一组在一次reduce方法中处理。
4、 执行Reduce方法
Reduce端的Shuffle完成后,就交由reduce方法来进行处理了。
四、MapReduce过程中的优化
1、 使用combiner减少数据量
2、 启用压缩
3、 合理配置reduce个数
五、MapRedue过程中的压缩设置
1、 压缩格式与算法
(1) 压缩格式
|
压缩格式 |
算法 |
文件扩展名 |
是否可以切分 |
|
DEFLATE |
DEFLATE |
.deflate |
否 |
|
Gzip |
DEFLATE |
.gz |
否 |
|
bzip2 |
bzip2 |
.gz |
是 |
|
LZO |
LZO |
.lzo |
否 |
|
LZ4 |
LZ4 |
.lz4 |
否 |
|
Snappy |
Snappy |
.snappy |
否 |
(2) Hadoop中压缩算法codec
|
压缩格式 |
Hadoop Codec |
|
DEFLATE |
org.apache.hadoop.io.compress.DefaultCodec |
|
gzip |
org.apache.hadoop.io.compress.GzipCodec |
|
bzip2 |
org.apache.hadoop.io.compress.BZip2Codec |
|
LZO |
org.apache.hadoop.io.lzo.LzopCodec |
|
LZ4 |
org.apache.hadoop.io.compress.Lz4Cdec |
|
Snappy |
org.apache.hadoop.io.compress.SnappyCodec |
2、 在*-site.xml文件中配置压缩
默认是不启用压缩的,如果对整个集群启用压缩,可以在mapred-site.xml中修改参数:
(1)
mapreduce.map.output.compress 是否对map任务输出进行压缩,默认是false。
(2)
mapreduce.map.output.compress.codec 设置map输出所用的压缩codec,默认是org.apache.hadoop.io.compress.DefaultCodec。
3、 在程序中配置压缩
Configuration configuration = new Configuration();
configuration.set("mapreduce.map.output.compress.","true");
configuration.setClass("mapreduce.map.output.compress.codec",
SnappyCodec.class, CompressionCodec.class);
附件列表
MapReduce Shuffle过程的更多相关文章
- 彻底理解MapReduce shuffle过程原理
彻底理解MapReduce shuffle过程原理 MapReduce的Shuffle过程介绍 Shuffle的本义是洗牌.混洗,把一组有一定规则的数据尽量转换成一组无规则的数据,越随机越好.MapR ...
- MapReduce:Shuffle过程的流程
Shuffle过程是MapReduce的核心,Shuffle描述着数据从map task输出到reduce task输入的这段过程. 1.map端
- MapReduce shuffle过程剖析及调优
MapReduce简介 在Hadoop MapReduce中,框架会确保reduce收到的输入数据是根据key排序过的.数据从Mapper输出到Reducer接收,是一个很复杂的过程,框架处理了所有问 ...
- 2.27 MapReduce Shuffle过程如何在Job中进行设置
一.shuffle过程 总的来说: *分区 partitioner *排序 sort *copy (用户无法干涉) 拷贝 *分组 group 可设置 *压缩 compress *combiner ma ...
- MapReduce:详解Shuffle过程(转)
/** * author : 冶秀刚 * mail : dennyy99@gmail.com */ Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapRedu ...
- MapReduce:详解Shuffle过程
Shuffle过程,也称Copy阶段.reduce task从各个map task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定的阀值,则写到磁盘上,否则直接放到内存中. 官方的Shuffl ...
- MapReduce:详解Shuffle过程
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapReduce, Shuffle是必须要了解的.我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑, ...
- [转]MapReduce:详解Shuffle过程
Shuffle过程是MapReduce的核心,也被称为奇迹发生的地方.要想理解MapReduce, Shuffle是必须要了解的.我看过很多相关的资料,但每次看完都云里雾里的绕着,很难理清大致的逻辑, ...
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
摘要: 通过腾讯shuffle部署对shuffle过程进行详解 摘要:腾讯分布式数据仓库基于开源软件Hadoop和Hive进行构建,TDW计算引擎包括两部分:MapReduce和Spark,两者内部都 ...
随机推荐
- 初识Python
Python 简介 Python 是一个高层次的结合了解释性.编译性.互动性和面向对象的脚本语言. Python 的设计具有很强的可读性,相比其他语言经常使用英文关键字,其他语言的一些标点符号,它具有 ...
- poj1200-Crazy Search(hash入门经典)
Hash:一般是一个整数.就是说通过某种算法,可以把一个字符串"压缩" 成一个整数.一,题意: 给出两个数n,nc,并给出一个由nc种字符组成的字符串.求这个字符串中长度为n的不同 ...
- [.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中)
[.net 面向对象程序设计进阶] (17) 多线程(Multithreading)(二) 利用多线程提高程序性能(中) 本节要点: 上节介绍了多线程的基本使用方法和基本应用示例,本节深入介绍.NET ...
- 配置apache和nginx的tomcat负载均衡
概述 本篇文章主要介绍apache和nginx的相关配置,tomcat的相关安装配置我在前面有写过一篇,详细介绍通过两种配置方法配置nginx. tomcat配置参考:http://www.cnblo ...
- SQL Server AlwaysOn
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/高性能解决方案 概述 环境: 域服务器:windows server 2008 R2 SP1,192.168.2.10 DNS:1 ...
- ASP.NET MVC 控制器激活(一)
ASP.NET MVC 控制器激活(一) 前言 在路由的篇章中讲解了路由的作用,讲着讲着就到了控制器部分了,从本篇开始来讲解MVC中的控制器,控制器是怎么来的?MVC框架对它做了什么?以及前面有的篇幅 ...
- Module-Zero之租户管理
返回<Module Zero学习目录> 开启多租户 租户实体 租户管理者 默认租户 开启多租户 ABP和Module-Zero可以运行多租户或单租户模式.多租户默认是禁用的.我们可以在mo ...
- [Hadoop大数据]——Hive连接JOIN用例详解
SQL里面通常都会用Join来连接两个表,做复杂的关联查询.比如用户表和订单表,能通过join得到某个用户购买的产品:或者某个产品被购买的人群.... Hive也支持这样的操作,而且由于Hive底层运 ...
- [CentOs7]搭建ftp服务器(3)——上传,下载,删除,重命名,新建文件夹
摘要 上篇文章介绍了如何为ftp添加虚拟用户,本篇将继续实践如何上传,下载文件. 上传 使用xftp客户端上传文件,如图所示 此时上传状态报错,查看详情 从错误看出是应为无法创建文件造成的.那么我们就 ...
- 【hbase0.96】基于hadoop搭建hbase的心得
hbase是基于hadoop的hdfs框架做的分布式表格存储系统,所谓表格系统就是在k/v系统的基础上,对value部分支持column family和column,并支持多版本读写. hbase的工 ...