Deep Reinforcement Learning with Iterative Shift for Visual Tracking
Deep Reinforcement Learning with Iterative Shift for Visual Tracking
2019-07-30 14:55:31
Code: not find yet.
Paper List of Tracking with Deep Reinforcement Learning: https://github.com/wangxiao5791509/Tracking-with-Deep-Reinforcement-Learning
1. Background and Motivation:
本文的贡献在于:
1). 提出一种 Actor-Critic Network 来预测物体运动的参数,并根据跟踪状态选择动作,不同的动作,会根据对结果的影响不同,设置不同的奖励;
2). 将 tracking 看做是迭代的平移问题,而不是 CNN Classification 问题,所以定位更加高效和准确;
3). 在 OTB 和 TC128 数据集上取得了较好的效果;
2. Approach:
本文所提出的方法包含三个模块:1). the actor network; 2). the prediction network; 3). the critic network.
2.1 Iterative Shift for Visual Tracking
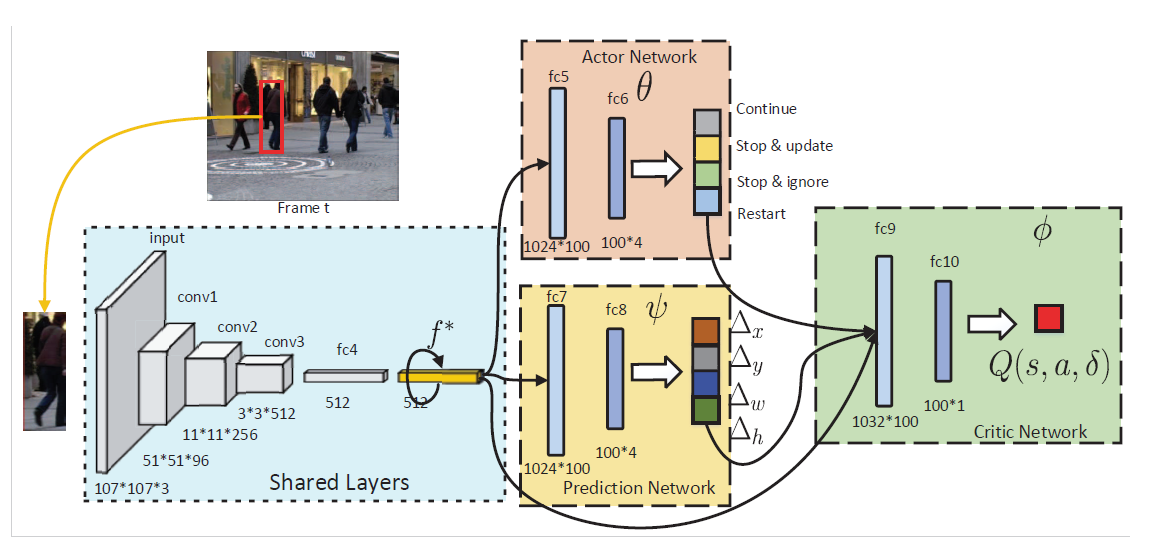
本文将 tracking 看做是迭代的平移问题。 给定当前帧和之前的跟踪结果,prediction network 会迭代的平移候选框,以定位住目标物体,与此同时,action network 会在跟踪状态上进行预测,判断是否进行模型的更新,预测网络,甚至是重启跟踪过程。
正式的来说,给定上一帧的跟踪结果 $l_{t-1} = {x_{t-1}, y_{t-1}, w_{t-1}, h_{t-1}}$ 以及 feature $f_{t-1}^*$,我们先根据该位置,得到当前帧的大致位置,抠出该 feature $f_t$,然后用预测网络进行预测:

其中,预测网络的输出为:

此外,跟踪状态也可能会影响最终的结果,即:需要适时的更新预测网络。为了联合的基于 target's motion status 以及 tracker's status 进行决策,我们利用 actor network 根据多项式分布来产生动作:

其中,$a_k \in A = \{ continuous, stop & update, stop & ignore, restart \}$。
对于动作 continuous 来说,即:不用更新模型,继续平移,而进行的 shift 是根据 prediction network 进行的。
对于动作 step & update 来说,即:停止平移,更新模型,即:

对于动作 stop & ignore 来说,停止平移,不更新模型,表示目标物体已经找到,然而,跟踪器无法确定是否需要进行更新。
对于动作 restart 来说,重新进行跟踪过程,即:restart the iteration by re-sampling a random set of candidate patches $L_t$ around $l_{t-1}^*$ in $I_t$ and select the patch which has the highest Q-values.
DRL-IS with Actor-Critic:
我们探索 AC算法,来进行联合的训练三个网络。首先作者根据跟踪的性能,进行了奖励的设定:
对于 continue 动作, 根据

对于 stop & update and stop & ignore 动作,奖励的设定是根据 final prediction 和 ground truth 之间的 IoU 进行评判的:

对于 restart 动作,当 final prediction 和 groundtruth 之间的 IoU 低于 0.4 时,给予 pos 的奖励:

然后,我们计算每一个动作的 Q-value。
对于 action continue 的 Q-value 来说:

对于其他的三个动作来说,是按照如下的式子进行计算:

最终,两个函数的优化是按照如下的式子进行的:

其中,s' 是下一个状态,a' 是选择的最优动作,Action-value 以及 Value function 是按照如下的方式进行计算的:


总体的算法过程如下所示:

==
Deep Reinforcement Learning with Iterative Shift for Visual Tracking的更多相关文章
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- (转) Deep Reinforcement Learning: Pong from Pixels
Andrej Karpathy blog About Hacker's guide to Neural Networks Deep Reinforcement Learning: Pong from ...
- (zhuan) Deep Reinforcement Learning Papers
Deep Reinforcement Learning Papers A list of recent papers regarding deep reinforcement learning. Th ...
- getting started with building a ROS simulation platform for Deep Reinforcement Learning
Apparently, this ongoing work is to make a preparation for futural research on Deep Reinforcement Le ...
- 论文笔记之:Asynchronous Methods for Deep Reinforcement Learning
Asynchronous Methods for Deep Reinforcement Learning ICML 2016 深度强化学习最近被人发现貌似不太稳定,有人提出很多改善的方法,这些方法有很 ...
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- Paper Reading 1 - Playing Atari with Deep Reinforcement Learning
来源:NIPS 2013 作者:DeepMind 理解基础: 增强学习基本知识 深度学习 特别是卷积神经网络的基本知识 创新点:第一个将深度学习模型与增强学习结合在一起从而成功地直接从高维的输入学习控 ...
- repost: Deep Reinforcement Learning
From: http://wanghaitao8118.blog.163.com/blog/static/13986977220153811210319/ accessed 2016-03-10 深度 ...
随机推荐
- Java 格式化日期、时间
有三种方法可以格式化日期.时间. 1.使用DateFormat类 获取DateFormat实例: DateFormat.getDateInstance() 只能格式化日期 2019年5 ...
- win10 提示该文件没有与之关联的应用来执行该操作
将下面代码复制进一个文本文档,然后将文本文档的txt后缀改成bat.双击运行,可以解决问题. 问题发生原因是之前通过注册表去除了桌面图标的快捷方式的小标志. /-------------------- ...
- linux中的【;】【&&】【&】【|】【||】说明与用法
原文 “;”分号用法 方式:command1 ; command2 用;号隔开每个命令, 每个命令按照从左到右的顺序,顺序执行, 彼此之间不关心是否失败, 所有命令都会执行. “| ”管道符用法 上一 ...
- 25.centos7基础学习与积累-011-课前考试二-命令练习
从头开始积累centos7系统运用 大牛博客:https://blog.51cto.com/yangrong/p5 取IP地址: 6的命令:ifconfig eth0 7的命令 [root@pytho ...
- MySQL/MariaDB数据库的复制监控和维护
MySQL/MariaDB数据库的复制监控和维护 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.清理日志 1>.删除指定日志文件名称之前的日志(也可用基于时间) M ...
- C#模拟鼠标、键盘操作
C语言 在程序中打开网页,模拟鼠标点击.键盘输入 一.简述 记--使用C语言 打开指定网页,并模拟鼠标点击.键盘输入.实现半自动填写账号密码,并登录网站(当然现在的大部分网站都有验证码 ...
- 【Selenium-WebDriver实战篇】ScreenRecorder的实际输出路径,自己的解决方案
==================================================================================================== ...
- web自动化测试-selenium的三种等待
一.等待的作用 1.在系统的功能运行过程中,所有的内容是需要一定的时间来实现展示, 2.时间耗费长短与网络速度.系统框架设定.接口的执行复杂度有关, 3.因此需要设置缓冲时间,若未设置缓冲时间,容易导 ...
- WinDbg的环境变量
有很多的环境变量,主要分为常规环境变量和内核模式环境变量.下面分别列出. 常规环境变量 下表列出了可在用户模式和内核模式调试的环境变量. 变量 含义 _NT_DEBUGGER_EXTENSION_PA ...
- 利用 PHP CURL zip压缩文件上传
$postData['file'] = "@".getcwd()."/../attachment/qianbao/{$customer_id}.zip"; $t ...