【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
原文地址:
https://www.cnblogs.com/steven-yang/p/5686473.html
-----------------------------------------------------------------------------------------------------------------
前言
最近在看Peter Harrington写的“机器学习实战”,这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能。
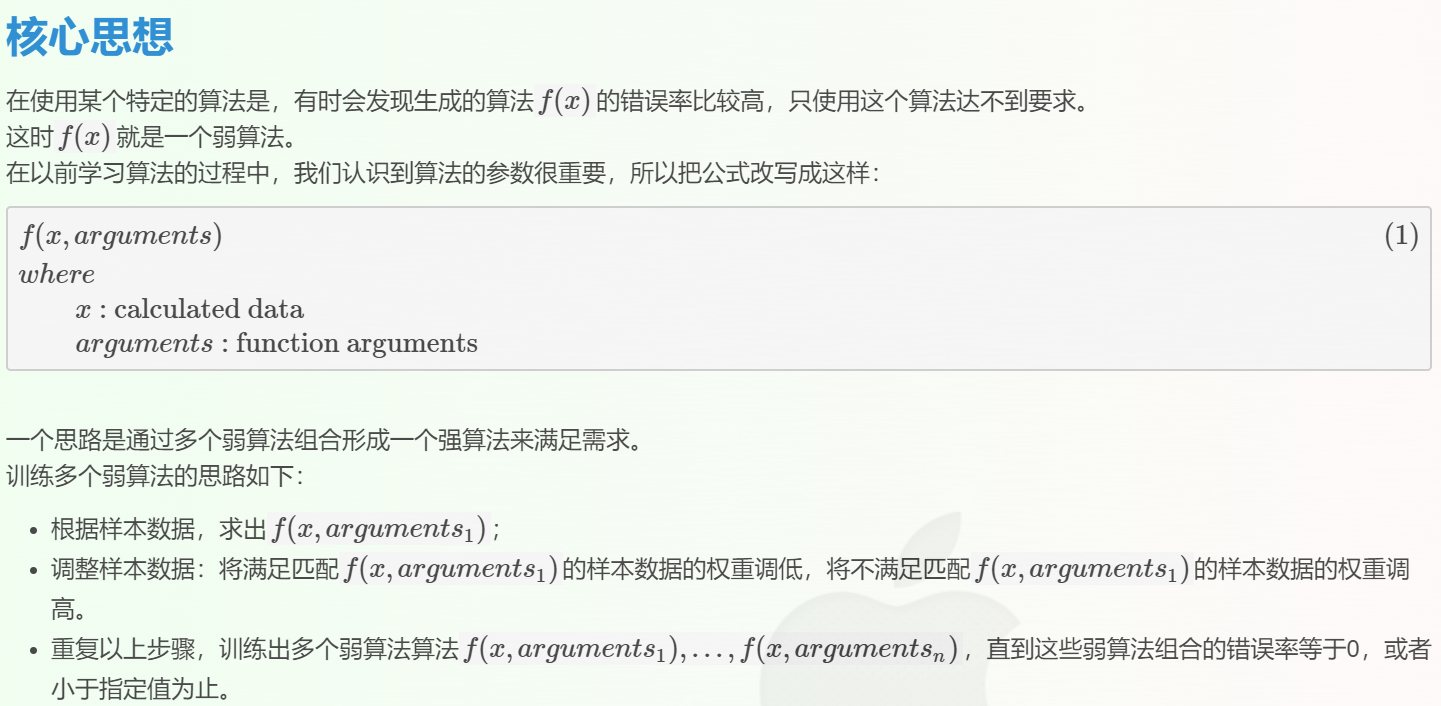
这个思路称之为Adaboost算法,是对其它算法组合的一种方式。
我们可以看出弱算法是同类的算法,也就是说,它们是基于相同的算法,只不过参数不同。这样元算法在训练算法的步骤中就好容易控制。
注:也有其它的的元算法,可以针对不同算法的。
基本概念
- 元算法(meta-algorithm),是对其它算法组合的一种方式。也称为集成方法(ensemble method)。
- 弱算法:准确度较低的算法。元算法通过组合多个弱算法来提高准确率。
- 强算法:可以认为是组合后的算法。
- boosting : 是一种元算法,将多个弱算法变成强算法的算法族。除了AdsBoost,还有LPBoost, TotalBoost, BrownBoost, xgboost, MadaBoost, LogitBoost, and others.
- Adaboost : Adaptive Boosting的简称。一个具体的boosting算法。本章就是介绍这个算法。
详解Adaboost
说明:书中弱算法是一个单层决策树算法,返回的是一个二类分类结果(-1, 1)。所以书中Adaboost也是一个二类分类算法。
Adaboost训练算法
- 输入
- 样本数据
- 弱算法的数量
- 输出
- 一个弱算法数组(弱算法参数,弱算法权重
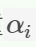 )
)
- 一个弱算法数组(弱算法参数,弱算法权重
- 逻辑
在一个迭代中(弱算法数量)
计算当前算法的参数
计算当前算法的错误率
计算当前算法的权重
计算下次样本数据的权重
计算当前的样本数据错误数,如果是0,退出。


解释:
假如有1000个sample,有100个sample被分错类,则:

可以看出错误的sample占的比例越小,下次的权重是二次方级数增大。
Adaboost分类算法
- 输入
- 分类数据
- 弱算法数组
- 输出
- 分类结果
- 逻辑
在一个迭代中(弱算法数量)
用当前弱算法计算分类结果$classified_i$
计算强分类结果(使用下面的公式)
返回分类结果
AdaBoost分类器中计算公式

参考
- Machine Learning in Action by Peter Harrington
- Boosting (machine learning)
-------------------------------------------------------------------------------------
【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能的更多相关文章
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 《机器学习实战第7章:利用AdaBoost元算法提高分类性能》
import numpy as np import matplotlib.pyplot as plt def loadSimpData(): dataMat = np.matrix([[1., 2.1 ...
- 利用AdaBoost元算法提高分类性能
当做重要决定时,大家可能都会吸取多个专家而不只是一个人的意见.机器学习处理问题时又何尝不是如此?这就是元算法背后的思路.元算法是对其他算法进行组合的一种方式. 自举汇聚法(bootstrap aggr ...
- 第七章:利用AdaBoost元算法提高分类性能
本章内容□ 组合相似的分类器来提髙分类性能□应用AdaBoost算法□ 处理非均衡分类问题
- 监督学习——AdaBoost元算法提高分类性能
基于数据的多重抽样的分类器 可以将不通的分类器组合起来,这种组合结果被称为集成方法(ensemble method)或者元算法(meta-algorithom) bagging : 基于数据随机抽样的 ...
- 机器学习实战 - 读书笔记(13) - 利用PCA来简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第13章 - 利用PCA来简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. ...
- 使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 第九篇:使用 AdaBoost 元算法提高分类器性能
前言 有人认为 AdaBoost 是最好的监督学习的方式. 某种程度上因为它是元算法,也就是说它会是几种分类器的组合.这就好比对于一个问题能够咨询多个 "专家" 的意见了. 组合的 ...
- 机器学习实战 - 读书笔记(14) - 利用SVD简化数据
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习心得,这次是第14章 - 利用SVD简化数据. 这里介绍,机器学习中的降维技术,可简化样品数据. 基 ...
随机推荐
- SpringCloud学习心得之Eureka注册中心的基本使用
SpringCloud学习心得——Eureka注册中心 示范代码链接 定义 SpringCloud Eureka是 SpringCloud Netflix微服务套件的一部分,基于 REST 的服务 ...
- JavaScript 进阶问题列表
https://github.com/lydiahallie/javascript-questions/blob/master/zh-CN/README-zh_CN.md 很考基本功
- HDU - 6125: Free from square (状压DP+分组背包)
problem:给定N,K.表示你有数1到N,让你最多选择K个数,问有多少种方案,使得选择的数的乘积无平方因子数.N,K<500: solution:显然可以状压DP做,但是500以内的素数还是 ...
- linux第一天命令
命令 : 命令 [选项] [参数] /;根目录 用户主目录:/home/用户名 <==> ~ 1.ls 显示路径中的内容 ls [参数] [路径] ls ls -l ...
- python 对象引用计数增加和减少的情况
对象引用计数增加的情况: 1.对象被创建:x=4 2.另外的别人被创建:y=x 3.被作为参数传递给函数:foo(x) ->会增加2 4.作为容器对象的一个元素:a=[1,x,'33'] 对象 ...
- regedit系统注册表,msconfig系统配置
msconfig msconfig即系统配置实用程序,是Microsoft System Configuration的缩写.是在开始菜单里运行中输入然后确认就可以找到程序开启或者禁用, 可以帮助电脑禁 ...
- 鼠标经过图片会移动(css3过渡,overflow:hidden)
效果图如下: 代码: <body> <div><img src="jd.jpg"></div> </body> img{ ...
- P3723 【[AH2017/HNOI2017]礼物】
被某大佬指出这是多项式板子!? 我们假设我们原始数列是\(a_i, c_i\), 旋转后的数列是\(a_i, b_i\),我们的增加量为x \[\sum_{i = 1}^n(a_i - b_i + x ...
- 爬虫基础以及一个简单的实例(requests,re)
最近在看爬虫方面的知识,看到崔庆才所著的<Python3网络爬虫开发实战>一书讲的比较系统,果断入手学习.下面根据书中的内容,简单总结一下爬虫的基础知识,并且实际练习一下.详细内容请见:h ...
- linux (core dump)调试
转自 http://www.cnblogs.com/hazir/p/linxu_core_dump.html Linux Core Dump 当程序运行的过程中异常终止或崩溃,操作系统会将程序当时的内 ...