kafka集群搭建(图文并用)
将安装包上传服务器并解压
scp kafka_2.11-1.0.0.tgz username@{ip}:~/.
mkdir /usr/local/kafka
mv kafka_2.11-1.0.0.tgz /usr/local/kafka/.
cd /usr/local/kafka
tar zxvf kafka_2.11-1.0.0.tgz
```
# 创建软连接
```
cd /usr/local/kafka
ln -s kafka_2.11-1.0.0 inuse
```
# 配置kafka的环境变量
A:
```
vi /etc/profile
```
B:添加内容:
```
export KAFKA_HOME=/usr/local/kafka/inuse
export PATH=$PATH:$KAFKA_HOME/bin
```
C:重新编译文件:
```
source /etc/profile
```
# 修改三台节点的配置文件
进入kafka的config目录
```
cd /usr/local/kafka/inuse/config
```
修改配置文件server.properties
```
vim server.properties
修改以下配置(如果没有该配置项则手动添加)
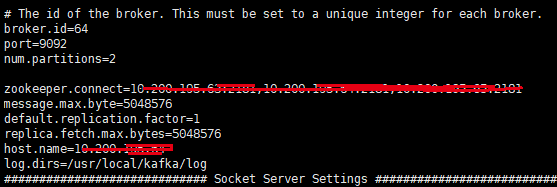
broker.id=25 (kafka节点的标识,多节点的id不允许相同,建议同ip的最末位序号保持一致)
port=9092
num.partitions=2 原先的配置为1
zookeeper.connect={ip1}:{port1},{ip2}:{port2},{ip3}:{port3}(如172.16.204.23:2181,172.16.204.24:2181,172.16.204.25:2181)
message.max.byte=5048576
default.replication.factor=1
replica.fetch.max.bytes=5048576
host.name={本机ip}
log.dirs=/usr/local/kafka/log
kafka3节点的ip,分别填入host.name
最终目录差不多是这样:

新建一个start.sh脚本,见上图。
创建日志目录
```
mkdir /usr/local/kafka/log
```
#启动kafka
```
cd /usr/local/kafka/inuse/bin
./kafka-server-start.sh -daemon ../config/server.properties
kafka集群测试
1. 创建一个吃瓜群众的topic

2.查看所有的topic
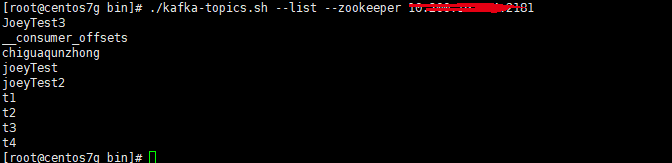
3.在某个topic下如吃瓜群众下 生产消息

此处的broker-list为kafka的服务ip及端口号
4.消费某个topic消息

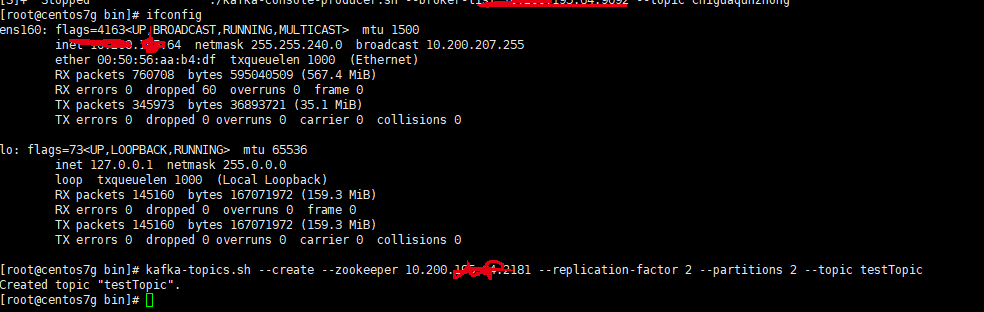
我在62,63,64三台机器上安装了kafka集群,在任一台创建的topic,其他两台都能看到,并且都能进行topic消息的消费。
在62机器上直接查看所有topic,zookeeper的地址随意填一个集群内的就行,不用都填,效果都一样
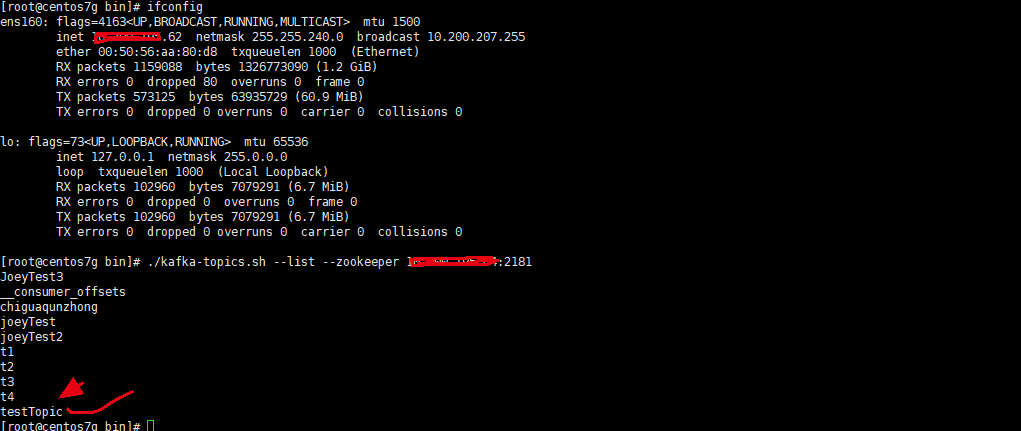
注意点:
不管是生产消息,还是消费消息,kafka的服务地址或zookeeper的地址随意填一个集群内的就行,不用都填,效果都一样。


最后给大家介绍一个工具,kafka-manager,主要可以对集群及topic进行相应的管理。

zookeeper的地址,需要填满,逗号分隔。
详细参考: https://blog.csdn.net/LA7388/article/details/101935535
有任何疑问或有错误,请留言告之,希望能帮助到大家!
kafka集群搭建(图文并用)的更多相关文章
- kafka集群搭建和使用Java写kafka生产者消费者
1 kafka集群搭建 1.zookeeper集群 搭建在110, 111,112 2.kafka使用3个节点110, 111,112 修改配置文件config/server.properties ...
- Kafka【第一篇】Kafka集群搭建
Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到这样的一些问题: 我们想分析下用户行为(pageviews),以便我们设计出更好的广告位 我想对用户 ...
- kafka学习(三)-kafka集群搭建
kafka集群搭建 下面简单的介绍一下kafka的集群搭建,单个kafka的安装更简单,下面以集群搭建为例子. 我们设置并部署有三个节点的 kafka 集合体,必须在每个节点上遵循下面的步骤来启动 k ...
- Zookeeper + Kafka 集群搭建
第一步:准备 1. 操作系统 CentOS-7-x86_64-Everything-1511 2. 安装包 kafka_2.12-0.10.2.0.tgz zookeeper-3.4.9.tar.gz ...
- 大数据 --> Kafka集群搭建
Kafka集群搭建 下面是以三台机器搭建为例,(扩展到4台以上一样,修改下配置文件即可) 1.下载kafka http://apache.fayea.com/kafka/0.9.0.1/ ,拷贝到三台 ...
- 消息队列kafka集群搭建
linux系统kafka集群搭建(3个节点192.168.204.128.192.168.204.129.192.168.204.130) 本篇文章kafka集群采用外部zookeeper,没采 ...
- [Golang] kafka集群搭建和golang版生产者和消费者
一.kafka集群搭建 至于kafka是什么我都不多做介绍了,网上写的已经非常详尽了. 1. 下载zookeeper https://zookeeper.apache.org/releases.ht ...
- zookeeper及kafka集群搭建
zookeeper及kafka集群搭建 1.有关zookeeper的介绍可参考:http://www.cnblogs.com/wuxl360/p/5817471.html 2.zookeeper安装 ...
- 【转】kafka集群搭建
转:http://www.cnblogs.com/luotianshuai/p/5206662.html Kafka初识 1.Kafka使用背景 在我们大量使用分布式数据库.分布式计算集群的时候,是否 ...
随机推荐
- Tomcat - 启动闪退
版本:Tomcat 9 问题:启动闪退.在控制台中输入"java -version"可以正常输出java的版本信息,但是使用start.bat启动时候闪退. 解决方法:配置系统环境 ...
- FreeRTOS中断测试
configMAX_SYSCALL_INTERRUPT_PRIORITY 高于此优先级的中断,不能被禁止 #ifdef __NVIC_PRIO_BITS #define configPRIO_BITS ...
- Swift面试题
class 和 struct 的区别 1.struct是值类型,class是引用类型. 值类型的变量直接包含它们的数据,对于值类型都有它们自己的数据副本,因此对一个变量操作不可能影响另一个变量. 引用 ...
- 微信支付接口--支付成功的回调--超详细Demo
如果本文对你有用,请爱心点个赞,提高排名,帮助更多的人.谢谢大家!❤ 如果解决不了,可以在文末进群交流. 如果对你有帮助的话麻烦点个[推荐]~最好还可以follow一下我的GitHub~感谢观看! 写 ...
- substr()用法
知识点链接:http://www.cplusplus.com/reference/string/string/substr/ 注意: std::string str2 = str.substr (po ...
- 基于Java+Selenium的WebUI自动化测试框架(十一)-----读取Excel文件(POI)(1)
上一篇说了利用JXL的jar包来读取Excel的代码.在Java中,还可以用另外一种jar包来读取Excel的内容,那就是Apache的POI. 这里和之前一样,需要导入POI的jar包,建议导入这三 ...
- 小a的排列(牛客)
题目 题意: 一个长度为n的排列.输入n个数 a[ i ],a[ i ] ∈ [1,n],要求找到长度最小的区间 [ l , r ],满足区间[ l , r ]内的数是连续的,且同时包含 数 x 和 ...
- K8S集群证书已过期且etcd和apiserver已不能正常使用下的恢复方案
在这种比较极端的情况下,要小心翼翼的规划和操作,才不会让集群彻底死翘翘.首先,几个ca根证书是10年期,应该还没有过期.我们可以基于这几个根证书,来重新生成一套可用的各组件认证证书. 前期,先制定以下 ...
- 《The One!团队》:BETA Scrum metting3
项目 内容 作业所属课程 所属课程 作业要求 作业要求 团队名称 < The One !> 作业学习目标 (1)掌握软件黑盒测试技术:(2)学会编制软件项目总结PPT.项目验收报告:(3) ...
- LG2664 树上游戏
树上游戏 题目描述 lrb有一棵树,树的每个节点有个颜色.给一个长度为n的颜色序列,定义s(i,j) 为i 到j 的颜色数量.以及 $$sum_i=\sum_{j=1}^ns(i,j)$$ 现在他想让 ...