Dependency Parsing
句子的依赖结构表现在哪些单词依赖哪些单词。单词之间的这种关系及可以表示为优先级之间的关系等。
Dependency Parsing
通常情况下,对于一个输入句子:\(S=w_{0} w_{1} \dots w_{n}\)。 我们用 \(w_{0}\) 来表示 ROOT,我们将这个句子转换成一个图 G。
依赖性解析通常分为训练与预测两步:
- 使用已经解析的注释库训练模型 M
- 得到模型 M之后,对于句子 S,通过模型解析出图 G。
基于转换的依赖性解析
该方法就是通过训练数据训练一个状态机,通过状态机转换对源语句进行解析。
基于贪心确定性过渡的解析
这个转换的系统本质也是一个状态机,但是不同的是,对于一个初始状态,会有多个终止状态。
对于每一个源语句 \(S=w_{0} w_{1} \dots w_{n}\) 每个状态可以表示成三部分 \(c=(\sigma, \beta, A)\) 。
- 第一部分 \(\sigma\) 用来存储来自 S 的 \(w_i\) ,使用栈存储
- \(\beta\) 表示一个来自 S 的缓冲
- A 表示 \(\left(w_{i}, r, w_{j}\right)\) 的集合,其中 \(w_{i}, w_{j}\) 来自 S,然后 r 表示 \(w_{i}, w_{j}\)之间的关系。
状态初始化:
- 初始状态是 \(C_0\) 可以表示为 \(\left[w_{0}\right]_{\sigma},\left[w_{1}, \ldots, w_{n}\right]_{\beta}, \varnothing\)。可以看到只有 \(w_0\) 在 \(\sigma\) 中,其它的 \(w_i\) 都在 \(\beta\) 中。还没有任何关系。
- 终止状态就是 \(\sigma,[ ]_{\beta}, A\) 形式。
状态转换的方法:
- 从缓存中移除一个单词兵放在 \(\sigma\) 栈顶,
- \(\mathrm{L} \mathrm{EFT}-\mathrm{A} \mathrm{RC}_{r}(l)\):将 \(\left(w_{j}, r, w_{i}\right)\) 添加至集合 A,\(w_{i}\) 是栈 \(\sigma\) 的第二个数据,\(w_{j}\) 是栈顶的单词,将 \(w_{i}\) 从栈中移除,这个 ARC 关系用 \(l\) 表示。
- \(\mathrm{RIGHT}-\mathrm{ARC}_{r}(l)\):将 \(\left(w_{i}, r, w_{j}\right)\) 添加到集合 A, \(w_{i}\)是栈的第二个单词,
神经依赖性解析
神经以来解析的效果要好于传统的方法。主要区别是神经依赖解析的特征表示。
我们描述的模型使用 arc 系统作为变换,我们的目的就是将原序列变成一个目的序列。就是完成解析树。这个过程可以看作是一个 encode 的过程。
Feature Selection:
第一步就是要进行特征的选择,对于神经网络的输入,我们需要定义一些特征,一般有以下这些:
\(S_{w o r d}\):S 中一些单词的向量表示
\(S_{\text {tag}}\):S 中一些单词的 Part-of-Speech (POS) 标签,POS 标签包含一个小的离散的集合:\(\mathcal{P}=\{N N, N N P, N N S, D T, J J, \dots\}\)
\(S_{l a b el}\):S 中一些单词的 arc-labels ,这个标签包含一个小的离散集合,描述依赖关系:\(\mathcal{L}=\{\) $amod, tmod $, \(n s u b j, c s u b j, d o b j\), \(\ldots\}\)
在神经网络中,我们还是首先会对这个输入处理,将这些编码从 one-hot 编码变成稠密的向量编码
对于单词的表示我们使用 \(e_{i}^{w} \in \mathbb{R}^{d}\)。使用的转换矩阵就是 \(E^{w} \in \mathbb{R}^{d \times N_{w}}\)。其中 \(N_w\) 表示字典的大小。\(e_{i}^{t}, e_{j}^{l} \in \mathbb{R}^{d}\) 分别表示第 \(i\) 个POS标签与第 \(j\) 个ARC 标签。对应的矩阵就是 \(E^{t} \in \mathbb{R}^{d \times N_{t}}\) and \(E^{l} \in \mathbb{R}^{d \times N_{l}}\)。其中 \(N_t\) 和 \(N_L\) 分别表示所有的 POS标签 与 ARC标签的个数。我们用 \(S^{w}, S^{t}, S^{l}\) 来表示 word, POS,ARC 的信息。
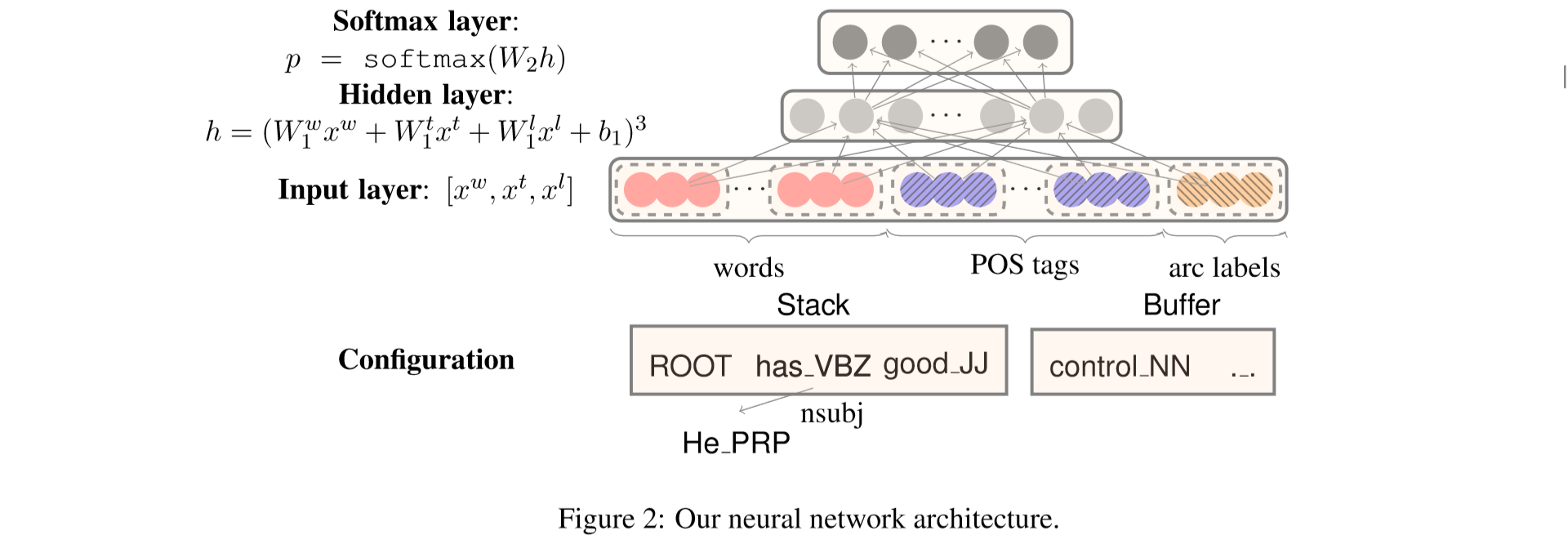
例如对于上面的这个图:
\(S_{tag}= \left\{l c_{1}\left(s_{2}\right) . t, s_{2} .t, r c_{1}\left(s_{2}\right) . t, s_{1} .t\right\}\)。然后我们将这些信息变成输入层的向量,比如对于单词来说,\(x^{w}=\left[e_{w_{1}}^{w} ; e_{w_{2}}^{w} ; \ldots e_{w_{n} w}^{w}\right]\)。其中 \(S_{word}=\left\{w_{1}, \ldots, w_{n_w}\right\}\),表示输入层的信息。同样的方式,我们可以获取到 \(x^t\) 与 \(x^l\)。然后我们经过一个隐含层,这个比较好理解:
\[
h=\left(W_{1}^{w} x^{w}+W_{1}^{t} x^{t}+W_{1}^{l} x^{l}+b_{1}\right)^{3}
\]
然后再经过一个 \(softmax\) 的输出层 \(p=\operatorname{softmax}\left(W_{2} h\right)\), 其中 \(W_2\) 是一个输出的矩阵,\(W_{2} \in \mathbb{R}|\mathcal{T}| \times d_{h}\)。
POS and label embeddings
就像单词的词典一样,我们对 POS 与 ARC 也有一个集合,其中 \(\mathcal{P}=\{\mathrm{NN}, \mathrm{NNP} ,\mathrm{NNS}, \mathrm{DT}, J J, \ldots \}\) 表示单词的一些性质, 例如 \(NN\) 表示单数名词。对于 \(\mathcal{L}=\{\)$ amod, tmod, nsubj, csubj, dobj$, \(\ldots\}\)表示单词间的关系。
Dependency Parsing的更多相关文章
- Dependency Parsing -13 chapter(Speech and Language Processing)
https://web.stanford.edu/~jurafsky/slp3/13.pdf constituent-based 基于成分的phrasal constituents and phras ...
- 依存分析 Dependency Parsing
依存分析 Dependency Parsing 句子成分依存分析主要分为两种:句法级别的和语义级别的 依存句法分析 syntactic dependency parsing 语义依存分词 semant ...
- 【神经网络】Dependency Parsing的两种解决方案
一.Transition-based的依存解析方法 解析过程:首先设计一系列action, 其就是有方向带类型的边,接着从左向右依次解析句子中的每一个词,解析词的同时通过选择某一个action开始增量 ...
- Transaction Replication6:Transaction cleanup
distribution中暂存的Transactions和Commands必须及时cleanup,否则,distribution size会一直增长,最终导致数据更新耗时增加,影响replicatio ...
- ZH奶酪:自然语言处理工具LTP语言云调用方法
前言 LTP语言云平台 不支持离线调用: 支持分词.词性标注.命名实体识别.依存句法分析.语义角色标注: 不支持自定义词表,但是你可以先用其他支持自定义分词的工具(例如中科院的NLPIR)把文本进行分 ...
- (转) The major advancements in Deep Learning in 2016
The major advancements in Deep Learning in 2016 Pablo Tue, Dec 6, 2016 in MACHINE LEARNING DEEP LEAR ...
- RNN and LSTM saliency Predection Scene Label
http://handong1587.github.io/deep_learning/2015/10/09/rnn-and-lstm.html //RNN and LSTM http://hando ...
- 我和NLP的故事(转载)
正值ACL录用结果发布,国内的老师和同学们又是一次大丰收,在这里再次恭喜所有论文被录用的老师和同学们!我人品爆发,也收获了自己硕士阶段的第二篇ACL论文.本来只是想单纯分享下自己中论文的喜悦,但没成想 ...
- awesome-nlp
awesome-nlp A curated list of resources dedicated to Natural Language Processing Maintainers - Keon ...
随机推荐
- vue 数据更新问题
在uni-app构建选项卡时,方法中改变的数组数据 无法更新v-if中的布尔值 在函数中打印出来是修改成功了,但在页面中并没有进行响应 布局如下: <swiper :current=" ...
- 常用模块 - configparse模块
一.简介 configparser模块在Python中是用来读取配置文件的,配置文件的格式跟windows下的ini配置文件相似,可以包含一个或多个节点(section),每个节可以有多个参数(键=值 ...
- 常用的User-Agent
window.navigator.userAgent 1) ChromeWin7:Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTM ...
- 我的oracle 健康检查报告
最近一直想用sql来生成oracle的健康检查报告,这样看起来一目了然,经过网上搜资料加自己整理终于算是成型了,部分结果如下图所示, 具体参考附件,恳请广大网友看看是否还有需要添加的地方. DB_he ...
- MySQL/MariaDB数据库的各种日志管理
MySQL/MariaDB数据库的各种日志管理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.事务日志 (transaction log) 1>.Innodb事务日志相 ...
- Linux用户组和权限管理
Linux用户组和权限管理 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Linux的安全模型 1>.安全3A 这并不是Linux特有的概念,在很多领域都有3A的概念 ...
- W3C--BOM(1)知识梳理
<一>BOM浏览器对象模型 1. window 1.1 window.innerHeight浏览器窗口的内部高度,window.innerWidth浏览器窗口的内部宽度 (对于Inter ...
- JMeter+Maven+CSV数据驱动
1.整个工程的目录结构: 2.工程说明: # ddcapitest XXX_API自动化测试 # 一.文件说明: 1. ddcapitest/src/是工程的入口 ddcapitest/pom.xml ...
- Nginx+keepalived 高可用双机热备(主从模式)
环境:centos7.6 最小化安装 主:10.11.1.32 从:10.11.1.33 VIP:10.11.1.130 修改主节点主机名: hostnamectl set-hostname web_ ...
- centos7部署etcd集群
实验环境:centos7.4纯净版 192.168.216.130 node1 master 192.168.216.132 node2 slave 192.168.216.134 node3 sla ...