Hash算法及java HashMap底层实现原理理解(含jdk 1.7以及jdk 1.8)
现在很多公司面试都喜欢问java的HashMap原理,特在此整理相关原理及实现,主要还是因为很多开发集合框架都不甚理解,更不要说各种其他数据结构了,所以造成面子造飞机,进去拧螺丝。
1.哈希表结构的优势?
哈希表作为一种优秀数据结构
本质上存储结构是一个数组,辅以链表和红黑树
数组结构在查询和插入删除复杂度方面分别为O(1)和O(n)
链表结构在查询和插入删除复杂度方面分别为O(n)和O(1)
二叉树做了平衡 两者都为O(lgn)
而哈希表两者都为O(1)
2.哈希表简介
哈希表本质是一种(key,value)结构
由此我们可以联想到,能不能把哈希表的key映射成数组的索引index呢?
如果这样做的话那么查询相当于直接查询索引,查询时间复杂度为O(1)
其实这也正是当key为int型时的做法 将key通过某种做法映射成index,从而转换成数组结构
3.数据结构实现步骤
1.使用hash算法计算key值对应的hash值h(默认用key对应的hashcode进行计算(hashcode默认为key在内存中的地址)),得到hash值
2.计算该(k,v)对应的索引值index
索引值的计算公式为 index = (h % length) length为数组长度
3.储存对应的(k,v)到数组中去,从而形成a[index] = node<k,v>,如果a[index]已经有了结点
即可能发生碰撞,那么需要通过开放寻址法或拉链法(Java默认实现)解决冲突
当然这只是一个简单的步骤,只实现了数组 实际实现会更复杂
hash表 数组类似下图
| 索引 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| --- | null | null | <10,node1> | <27,node2> | null | null | null | null |
| --- |
jdk 1.7以及之前的结构类似如下:
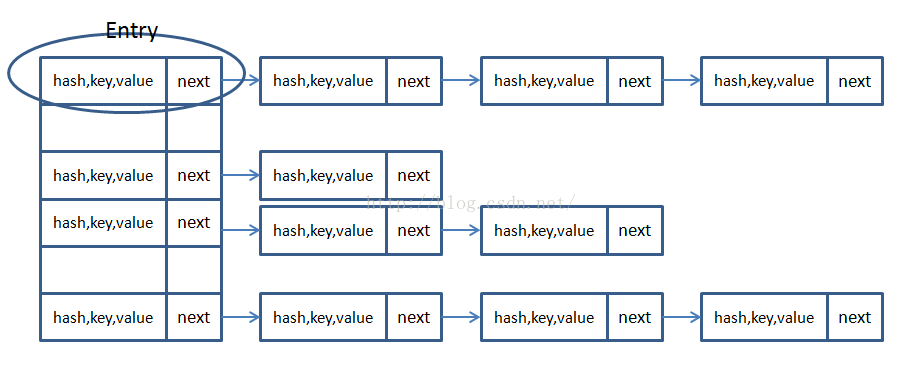
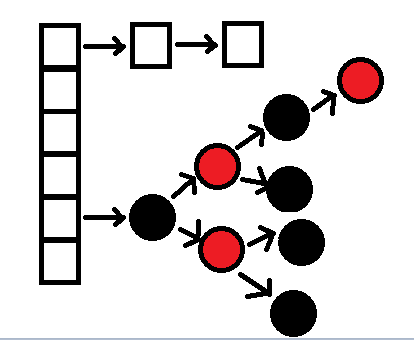
jdk 8中的结构如下:
两个重要概念
哈希算法
h 通过hash算法计算得到的的一个整型数值
h可以近似看做一个由key的hashcode生成的随机数,区别在于相同的hashcode生成的h必然相同
而不同的hashcode也可能生成相同h,这种情况叫做hash碰撞,好的hash算法应尽量避免hash碰撞
(ps:hash碰撞只能尽量避免,而无法杜绝,由于h是一个固定长度整型数据,原则上只要有足够多的输入,就一定会产生碰撞)
关于hash算法有很多种,这里不展开赘述,只需要记住h是一个由hashcode产生的伪随机数即可
同时需要满足key.hashcode -> h 分布尽量均匀(下文会解释为何需要分布均匀)
可以参考https://blog.csdn.net/tanggao1314/article/details/51457585
解决碰撞冲突
由上我们可以知道,不同的hashcode可能导致相应的h即发生碰撞
那么我们需要把相应的<k,v>放到hashmap的其他存储地址
解决方法1:Hash冲突的线性探测开放地址法
通过在数组以某种方式寻找数组中空余的结点放置
基本思想是:当关键字key的哈希地址p=H(key)出现冲突时
以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,
解决方法1:链地址法(JDK采用的哈希冲突解决方法及JDK7的源码,JDK8差异大)
通过引入链表 数组中每一个实体存储为链表结构,如果发生碰撞,则把旧结点指针指向新链表结点,此时查询碰撞结点只需要遍历该链表即可
在这种方法下,数据结构如下所示
int类型数据 hashcode 为自身值

在JAVA中几个细节点
1.为什么需要扩容?扩容因子大还是小好?
由于数组是定长的,当数组储存过多的结点时,发生碰撞的概率大大增加,此时hash表退化成链表
过大的扩容因子会导致碰撞概率大大提升,过小扩容因子会造成存储浪费,在Java中默认为0.75
2.当从哈希表中查询数据时,如果key对应一条链表,遍历时如何判断是否应该覆盖?
当遍历链表时,如果两个key.hashcode的h一致会调用equals()方法判断是否为同一对象,equal的默认实现是比较两者的内存地址
因此为什么Java强调当重写equals()时需要同时重写hashcode()方法,假设两个不同对象,在内存中的地址不同分别为a和b,那么重写equals()以后a.equals(b) =true 开发者希望把a,b这两个key视作完全相等
然而由于内存地址的不同导致hashcode不同,会导致在hashmap中储存2个本应相同的key值
这里提供一个范例
public class Student {
//学号
public int student_no;
//姓名
public String name;
@Override
public boolean equals(Object o) {
Student student = (Student) o;
return student_no == student.student_no;
}
}
通常情况下我们像上图一样期望通过判断两个Student的学号是否是否为同一学生
然而在使用map或set集合时产生出乎意料的结果

当我们重写hashcode()时
@Override
public int hashCode() {
return Objects.hash(student_no);
}
可以看到现在可以正常使用集合框架中的一些特性

3.为什么在HashMap中数组的长度length = 2^n(初始值为16),即2的n次 ?
当计算索引值index = h % length 由于计算机的取余操作速度很慢,而计算机的按位取余 & 的操作非常快,又因为h%length = h & (length-1)(需要满足length = 2^n) 因此规定了length = 2^n 加快index的计算速度,因此是利用了计算机本身的计算特性
4.HashMap的红黑树在哪里体现呢?
红黑树是JDK8中对hashmap作的一个变更,在JDK8之前,HashMap、HashSet采用数组+链表的形式来解决哈希冲突,我们知道优秀的hash算法应避免碰撞的发生,但假如开发者使用了不合适的hash算法,O(1)级别的数组查询会退化到O(n)级链表查询,因此在JDK8中引入红黑树的,当一个结点的链表长度大于8时,链表会转换成红黑树,提高查询效率,而链表长度小于6时又会退化成链表
5.扩容是如何触发的?
当hashmap中的size > loadFactory * capacity即会发生扩容,size 也是数组结点和链表结点的总和,要明确扩容是一个非常耗费性能的操作,因为数组的长度发生改变,需要对所有结点的索引值重新进行计算,而在JDK8中对这部分进行了优化,详细可以参考https://blog.csdn.net/aichuanwendang/article/details/53317351,在扩容完后减轻了碰撞产生的影响。但是值得注意的是如果两个线程都发现HashMap需要重新调整大小了,它们会同时试着调整大小。在调整大小的过程中,存储在链表中的元素的次序会反过来,因为移动到新的bucket位置的时候,HashMap并不会将元素放在链表的尾部,而是放在头部,这是为了避免尾部遍历(tail traversing)。如果条件竞争发生了,那么就死循环了。所以多线程环境要使用ConcurrentHashMap(值得特别注意的是,concurrenthashmap不允许value值为null,其原因是如果可以为null,那么并发判断的时候就不知道是没找到值还是值为null,故不允许。如果一定需要怎么办?见一个无属性的Null类代替)而不能使用HashMap。
在jdk 8中,对扩容进行了优化,增加了高16位异或低16位,此时当n变为2倍时,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。如果没有变,意味着很多不需要移动,具体可参见源代码中hash方法的实现,也可以参考https://my.oschina.net/u/2307589/blog/1800587的示意图,画的很清晰。
在正常的Hash算法下,红黑树结构基本不可能被构造出来,根据概率论,理想状态下哈希表的每个箱子中,元素的数量遵守泊松分布,通俗易懂的解释泊松分布

(即除非hash算法有问题,否则单位时间内发生冲撞的概率是可以估算出来的):
P(X=k) = (λ^k/k!)e^-λ,k=0,1,...
当负载因子为 0.75 时,上述公式中 λ 约等于 0.5,因此箱子中元素个数和概率的关系如下:(参考https://blog.csdn.net/Philm_iOS/article/details/81200601),下述分布说明来自源码文档:
> * Because TreeNodes are about twice the size of regular nodes, we
* use them only when bins contain enough nodes to warrant use
* (see TREEIFY_THRESHOLD). And when they become too small (due to
* removal or resizing) they are converted back to plain bins. In
* usages with well-distributed user hashCodes, tree bins are
* rarely used. Ideally, under random hashCodes, the frequency of
* nodes in bins follows a Poisson distribution
* (http://en.wikipedia.org/wiki/Poisson_distribution) with a
* parameter of about 0.5 on average for the default resizing
* threshold of 0.75, although with a large variance because of
* resizing granularity. Ignoring variance, the expected
* occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
* factorial(k)). The first values are:
*
* 0: 0.60653066
* 1: 0.30326533
* 2: 0.07581633
* 3: 0.01263606
* 4: 0.00157952
* 5: 0.00015795
* 6: 0.00001316
* 7: 0.00000094
* 8: 0.00000006
* more: less than 1 in ten million最后和JDK 7不同的是,JDK1.8中新增了一个实现了Entry接口的内部类Node<K,V>,即哈希节点。
参考:
- JDK 8中hashmap的实现解析:https://blog.csdn.net/lch_2016/article/details/81045480
- 相关HashMap相关的面试问题:https://blog.csdn.net/suifeng629/article/details/82179996
Hash算法及java HashMap底层实现原理理解(含jdk 1.7以及jdk 1.8)的更多相关文章
- Java面试必问之Hashmap底层实现原理(JDK1.7)
1. 前言 Hashmap可以说是Java面试必问的,一般的面试题会问: Hashmap有哪些特性? Hashmap底层实现原理(get\put\resize) Hashmap怎么解决hash冲突? ...
- HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别(转)
HashMap底层实现原理/HashMap与HashTable区别/HashMap与HashSet区别 文章来源:http://www.cnblogs.com/beatIteWeNerverGiveU ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 一致性hash算法及java实现
一致性hash算法是分布式中一个常用且好用的分片算法.或者数据库分库分表算法.现在的互联网服务架构中,为避免单点故障.提升处理效率.横向扩展等原因,分布式系统已经成为了居家旅行必备的部署模式,所以也产 ...
- 对一致性Hash算法及java实现(转)
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- 对一致性Hash算法,Java代码实现的深入研究(转)
转载:http://www.cnblogs.com/xrq730/p/5186728.html 一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读 ...
- 【转载】对一致性Hash算法,Java代码实现的深入研究
原文地址:http://www.cnblogs.com/xrq730/p/5186728.html 一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细 ...
- Java中HashMap底层实现原理(JDK1.8)源码分析
这几天学习了HashMap的底层实现,但是发现好几个版本的,代码不一,而且看了Android包的HashMap和JDK中的HashMap的也不是一样,原来他们没有指定JDK版本,很多文章都是旧版本JD ...
- Java面试必问之Hashmap底层实现原理(JDK1.8)
1. 前言 上一篇从源码方面了解了JDK1.7中Hashmap的实现原理,可以看到其源码相对还是比较简单的.本篇笔者和大家一起学习下JDK1.8下Hashmap的实现.JDK1.8中对Hashmap做 ...
随机推荐
- 简述mysql问题处理
最近,有一位同事,咨询我mysql的一点问题, 具体来说, 是如何很快的将一个mysql导出的文件快速的导入到另外一个mysql数据库.我学习了很多mysql的知识, 使用的时间却并不是很多, 对于m ...
- MySQL 自带的4个系统数据库的说明
自带的4个系统数据库:information_schema.mysql.performance_schema.sys: information_schema:这个数据库保存了mysql服务器所有数据库 ...
- GRUB配置与应用,启动故障分析解决
一.GRUB启动位置 GRUB是现今大多数Linux系统采用的自举程序,这里先来看一下Linux的程序顺序: 执行顺序 动作 固件Firmware(CMOS/BIOS) → POST(Pwer ...
- linux cgroups简介(上)
Linux CGroups简介 1.CGroups是什么 与Linux namespace对比来看,Linux namespace用来限制进程的运行范围或者运行环境的可见性,比如:uts限制进程读取到 ...
- Httpd服务进阶知识-LAMP架构概述
Httpd服务进阶知识-LAMP架构概述 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.LAMP架构概述 1>.什么是LAM(M)P架构 L: linux A: apa ...
- Go语言IDE远程连接Linux服务器
我因为在自己的云服务器上面进行Go语言开发,IDE必不可少,为了减少对于服务器的压力决定使用golang远程连接进行开发: 首先准备goland https://www.jetbrains.com/g ...
- Codeforces A. Password(KMP的nxt跳转表)
题目描述: Password time limit per test 2 seconds memory limit per test 256 megabytes input standard inpu ...
- Word 页码设置教程:如何删除封面和目录的目录?
我们常写的报告大都由封面.目录.正文和附录组成,但是页码通常是从正文开始的,所以下面介绍如何从指定页面开始设置页码. 在介绍之前需要了解一下分隔符的作用.分隔符大体分成分页符和分节符. 分页符细分的几 ...
- docker学习8-搭建nginx环境
前言 使用 docker 搭建 nginx 环境 下载镜像 使用docker pull 拉取最新的 nginx 镜像 [root@yoyo ~]# docker pull nginx Using de ...
- 201671030106 何启芝 实验十四 团队项目评审&课程学习总结
项目 内容 这个作业属于哪个课程 >>2016级计算机科学与工程学院软件工程(西北师范大学) 这个作业的要求在哪里 >>实验十四 团队项目评审&课程学习总结 课程学习目 ...