论文笔记:GREEDY FUNCTION APPROXIMATION: A GRADIENT BOOSTING MACHINE
Boost是集成学习方法中的代表思想之一,核心的思想是不断的迭代。boost通常采用改变训练数据的概率分布,针对不同的训练数据分布调用弱学习算法学习一组弱分类器。在多次迭代的过程中,当前次迭代所用的训练数据的概率分布会依据上一次迭代的结果而调整。也就是说训练数据的各样本是有权重的,这个权重本身也会随着迭代而调整。Adaboost(后面补一篇介绍这个的文章吧)在迭代的过程中通过不断调整数据分布的权重来达到提高性能的目的,GBM(Gradient Boosting Machine)则是在迭代的过程中,新的模型建立在之间建立模型损失函数的梯度下降方向上,为什么这么做是有效的,数学语言是最严谨的,让我们从数学的角度出发理解一下。
从数值优化的角度入手。对于加性模型$F(X|\Theta) $,我们通过优化$\Theta$得到模型的最优解
$$ \theta^* = \mathop{\arg\min}_{\theta} \ \mathrm{L} (\theta).$$
其中,$\mathrm{L}(\theta) = E_(y,x)\mathrm{L}(y,F(X|\Theta))$ ,那么对于$F(X|\Theta) $其最优解为$F^*(x) =F(x|\Theta^*) $ 。由于$F(X|\Theta) $是个加性模型,通常有$P^* = \sum_{i = 0}^m p_i$。在优化P的过程中,对于迭代的第m步骤,我们以前获得了m-1个模型,在计算第m个模型的时候,我们要对前m-1个模型的集成求梯度,$g_m$为求得的梯度如下所示$$g_m=\{g_{jm}\} = \{{\big[\frac{\partial{\phi(P)}}{\partial{P_j}}\big]_{p = p_{(m-1)}}}\}$$其中$$P_{m-1} = \sum_{i=0}^{m-1} P_i$$求出梯度之后,我们更新$$p_m = -\rho_mg_m$$其中,$$\rho_m = \mathop{\arg\min}_\rho\ L(P_{m-1}-\rho{g_m})$$
简单整理一下,对于加性模型$F(X|\Theta) $,我们通过对损失函数$L(\theta)$求得$\theta$沿着最优解下降的方向$g_m$,为了确定下降的步长,也就是$\rho$,我们构造一个关于$P_{m-1}+p_m$的损失函数,其中$p_m = -\rho{g_m}$。确定了梯度$g_m$以及在该梯度下的步长$\rho$,$p_m$也就求解出来了。
上述的推导过程中,建立在训练的数据集是连续无穷的情况下,对于有限的数据集合在计算$g_m$的过程中,求出的最优解$F^*(X)$对应的点不一定是我们训练集中的点。简单来说就是对于前m-1个模型计算出来的梯度对于有限的训练数据集,并不能直接作为新的基学习器的梯度方向。为了解决这个问题,论文预先假设一个先验分布$h(x_i;a)$,通过最小化损失函数的方式让$h(x_i;a)$逼近预先计算好的梯度$g_m$,论文中用的损失函数是MSE,过程如下所示$$a_m=\mathop{\arg\min}_{a,\beta} \sum_{i=1}^N[{-g_m(x_i)-\beta{h(x_i;a)}}]^2 $$
整体的GBM算法流程如下所示

第三步对应的便是求前m-1个模型的梯度, 第四步根据球出来的梯度通过最小化损失函数的方法让基模型(h(x;a))逼近梯度下降的方向,第五步也是通过最小化集成的函数预测结果与label的损失也确定第k个基模型的权重。
紧扣最小化似然函数这个过程就不难理解这么做的缘由了。
2019.9.7 在实际理解GBM的调参过程中发现对CART如何学习以及
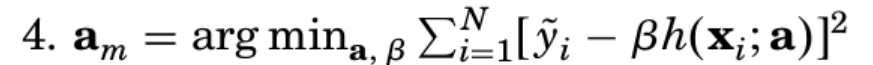
如何影响CART的参数的学习并没有理解清楚.
首先要弄清楚CART学习的参数究竟是什么,这里指的是最优分裂属性以及分裂属性值的选择,外界的干预通过label影响最优划分属性的选择,具体的介绍见:https://blog.csdn.net/niuniuyuh/article/details/76922210
论文笔记:GREEDY FUNCTION APPROXIMATION: A GRADIENT BOOSTING MACHINE的更多相关文章
- Greedy Function Approximation:A Gradient Boosting Machine
https://statweb.stanford.edu/~jhf/ftp/trebst.pdf page10 90% to 95% of the observations were often de ...
- 论文笔记:LightGBM: A Highly Efficient Gradient Boosting Decision Tree
引言 GBDT已经有了比较成熟的应用,例如XGBoost和pGBRT,但是在特征维度很高数据量很大的时候依然不够快.一个主要的原因是,对于每个特征,他们都需要遍历每一条数据,对每一个可能的分割点去计算 ...
- Tree - Gradient Boosting Machine with sklearn source code
This is the second post in Boosting algorithm. In the previous post, we go through the earliest Boos ...
- Python中Gradient Boosting Machine(GBM)调参方法详解
原文地址:Complete Guide to Parameter Tuning in Gradient Boosting (GBM) in Python by Aarshay Jain 原文翻译与校对 ...
- 机器学习--Gradient Boosting Machine(GBM)调参方法详解
一.GBM参数 总的来说GBM的参数可以被归为三类: 树参数:调节模型中每个决策树的性质 Boosting参数:调节模型中boosting的操作 其他模型参数:调节模型总体的各项运作 1.树参数 现在 ...
- 机器学习中的数学(3)-模型组合(Model Combining)之Boosting与Gradient Boosting
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- 模型组合(Model Combining)之Boosting与Gradient Boosting
版权声明: 本文由LeftNotEasy发布于http://leftnoteasy.cnblogs.com, 本文可以被全部的转载或者部分使用,但请注明出处,如果有问题,请联系wheeleast@gm ...
- A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning
A Gentle Introduction to the Gradient Boosting Algorithm for Machine Learning by Jason Brownlee on S ...
- How to Configure the Gradient Boosting Algorithm
How to Configure the Gradient Boosting Algorithm by Jason Brownlee on September 12, 2016 in XGBoost ...
随机推荐
- JavaScript操作BOM
window对象的属性: history: 方法: back() 加载 history 对象列表中的前一个URL forward() 加载 history 对象列表中的下一个URL go() 加载 h ...
- 【python驱动】python进行selenium测试时GeckoDriver放在什么地方?
背景:用python进行selenium 关于b/s架构的测试,需要配置驱动否则程序无法执行 情况1:windows下放置GeckoDriver 步骤1:下载驱动 GeckoDriver下载地址fir ...
- 你对SQA的职责和工作活动(如软件度量)的理解?
SQA就是独立于软件开发的项目组,通过对软件开发过程的监控,来保证软件的开发流程按照指定的CMM规程(如果有相应的CMM规程),对于不符合项及时提出建议和改进方案,必要时可以向高层经理汇报以求问题的解 ...
- Tkinter 之使用PAGE工具开发GUI界面
一.安装 1.官网下载 PAGE http://page.sourceforge.net/ Tcl(8.6+) https://www.activestate.com/activetcl/downlo ...
- join 分割数组
返回一个字符串.该字符串是通过把 arrayObject 的每个元素转换为字符串,然后把这些字符串连接起来,在两个元素之间插入 separator 字符串而生成的. separator可以传可以传,不 ...
- OpenFOAM——具有压差且平行平板间具有相对运动流动
本算例翻译整理自:http://the-foam-house5.webnode.es/products/chapter-1-plane-parallel-plates-case/ 这个算例中两平板间具 ...
- Hadoop(三)—— YARN
YARN产生的背景 Hadoop相关概念 Hadoop 1.0 由HDFS.MapReduce组成. Hadoop 2.0 克服1.0中HDFS和MapReduce存在的各种问题而提出的. YARN是 ...
- Jmeter工具功能介绍
可以去官方学习:http://jmeter.apache.org/ 1.可以修改语言 2.部分图标功能 新建 打开一个jmeter脚本 保存一个jmeter脚本 剪切 复制 粘贴 展开目录树 收起目录 ...
- Spark2.x(五十七):User capacity has reached its maximum limit(用户容量已达到最大限制)
背景: 目前服务器资源是43个节点,每个节点配置信息如下:24VCores 64G yarn配置情况: yarn.scheduler.minimum-allocation-mb 单个容器可申请的最小 ...
- mysql索引原理及优化(一)
什么是索引 索引用来快速地寻找那些具有特定值的记录,所有MySQL索引都以B-tree的形式保存.如果没有索引,执行查询时MySQL必须从第一个记录开始扫描整个表的所有记录,直至找到符合要求的记录.表 ...