ElasticSearch 429 Too Many Requests circuit_breaking_exception
- 错误提示
{
"statusCode": 429,
"error": "Too Many Requests",
"message": "[circuit_breaking_exception]
[parent] Data too large, data for [<http_request>] would be [2087772160/1.9gb],
which is larger than the limit of [1503238553/1.3gb],
real usage: [2087772160/1.9gb],
new bytes reserved: [0/0b],
usages [request=0/0b, fielddata=1219/1.1kb, in_flight_requests=0/0b, accounting=605971/591.7kb],
with { bytes_wanted=2087772160 & bytes_limit=1503238553 & durability=\"PERMANENT\" }"
}
重要解决办法
关闭circuit检查:
indices.breaker.type: none
集群config/jvm.options设置如下
-Xms2g
-Xmx2g
#-XX:+UseConcMarkSweepGC
-XX:+UseG1GC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
以下这些都不用看了
再尝试其他查询也是如此。经排查,原来是ES默认的缓存设置让缓存区只进不出引起的,具体分析一下。
- ES缓存区概述
ES在查询时,会将索引数据缓存在内存(JVM)中:
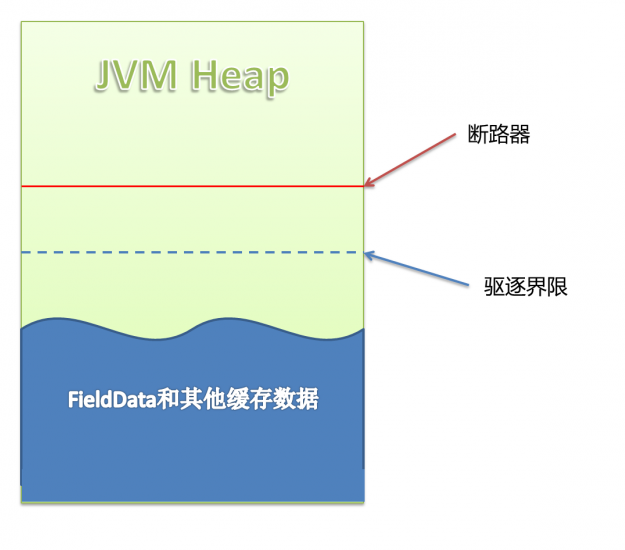
上图是ES的JVM Heap中的状况,可以看到有两条界限:驱逐线 和 断路器。当缓存数据到达驱逐线时,会自动驱逐掉部分数据,把缓存保持在安全的范围内。
当用户准备执行某个查询操作时,断路器就起作用了,缓存数据+当前查询需要缓存的数据量到达断路器限制时,会返回Data too large错误,阻止用户进行这个查询操作。
ES把缓存数据分成两类,FieldData和其他数据,我们接下来详细看FieldData,它是造成我们这次异常的“元凶”。
FieldData
ES配置中提到的FieldData指的是字段数据。当排序(sort),统计(aggs)时,ES把涉及到的字段数据全部读取到内存(JVM Heap)中进行操作。相当于进行了数据缓存,提升查询效率。监控FieldData
仔细监控fielddata使用了多少内存以及是否有数据被驱逐是非常重要的。
ielddata缓存使用可以通过下面的方式来监控
# 对于单个索引使用 {ref}indices-stats.html[indices-stats API]
GET /_stats/fielddata?fields=*
# 对于单个节点使用 {ref}cluster-nodes-stats.html[nodes-stats API]
GET /_nodes/stats/indices/fielddata?fields=*
#或者甚至单个节点单个索引
GET /_nodes/stats/indices/fielddata?level=indices&fields=*
# 通过设置 ?fields=* 内存使用按照每个字段分解了
fielddata中的memory_size_in_bytes表示已使用的内存总数,而evictions(驱逐)为0。且经过一段时间观察,字段所占内存大小都没有变化。由此推断,当下的缓存处于无法有效驱逐的状态。
- Cache配置
indices.fielddata.cache.size 配置fieldData的Cache大小,可以配百分比也可以配一个准确的数值。cache到达约定的内存大小时会自动清理,驱逐一部分FieldData数据以便容纳新数据。默认值为unbounded无限。
indices.fielddata.cache.expire用于约定多久没有访问到的数据会被驱逐,默认值为-1,即无限。expire配置不推荐使用,按时间驱逐数据会大量消耗性能。而且这个设置在不久之后的版本中将会废弃。
看来,Data too large异常就是由于fielddata.cache的默认值为unbounded导致的了。
- FieldData格式
除了缓存取大小之外,我们还可以控制字段数据缓存到内存中的格式。
在mapping中,我们可以这样设置:
{
"tag": {
"type": "string",
"fielddata": {
"format": "fst"
}
}
}
对于String类型,format有以下几种:
paged_bytes (默认):使用大量的内存来存储这个字段的terms和索引。
fst:用FST的形式来存储terms。这在terms有较多共同前缀的情况下可以节约使用的内存,但访问速度上比paged_bytes 要慢。
doc_values:fieldData始终存放在disk中,不加载进内存。访问速度最慢且只有在index:no/not_analyzed的情况适用。
对于数字和地理数据也有可选的format,但相对String更为简单,具体可在api中查看。
从上面我们可以得知一个信息:我们除了配置缓存区大小以外,还可以对不是特别重要却量很大的String类型字段选择使用fst缓存类型来压缩大小。
- 断路器
fieldData的缓存配置中,有一个点会引起我们的疑问:fielddata的大小是在数据被加载之后才校验的。假如下一个查询准备加载进来的fieldData让缓存区超过可用堆大小会发生什么?很遗憾的是,它将产生一个OOM异常。
断路器就是用来控制cache加载的,它预估当前查询申请使用内存的量,并加以限制。断路器的配置如下:
indices.breaker.fielddata.limit:这个 fielddata 断路器限制fielddata的大小,默认情况下为堆大小的60%。
indices.breaker.request.limit:这个 request 断路器估算完成查询的其他部分要求的结构的大小, 默认情况下限制它们到堆大小的40%。
indices.breaker.total.limit:这个 total 断路器封装了 request 和 fielddata 断路器去确保默认情况下这2个部分使用的总内存不超过堆大小的70%。
查询
/_cluster/settings
设置
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.fielddata.limit": "60%"
}
}
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.request.limit": "40%"
}
}
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.total.limit": "70%"
}
}
断路器限制可以通过文件 config/elasticsearch.yml 指定,也可以在集群上动态更新:
PUT /_cluster/settings
{
"persistent" : {
"indices.breaker.fielddata.limit" : 40%
}
}
当缓存区大小到达断路器所配置的大小时会发生什么事呢?答案是:会返回开头我们说的Data too large异常。这个设定是希望引起用户对ES服务的反思,我们的配置有问题吗?是不是查询语句的形式不对,一条查询语句需要使用这么多缓存吗?
在文件 config/elasticsearch.yml 文件中设置缓存使用回收
indices.fielddata.cache.size: 40%
- 总结
1.这次Data too large异常是ES默认配置的一个坑,我们没有配置indices.fielddata.cache.size,它就不回收缓存了。缓存到达限制大小,无法往里插入数据。个人感觉这个默认配置不友好,不知ES是否在未来版本有所改进。
2. 当前fieldData缓存区大小 < indices.fielddata.cache.size
当前fieldData缓存区大小+下一个查询加载进来的fieldData < indices.breaker.fielddata.limit
fielddata.limit的配置需要比fielddata.cache.size稍大。而fieldData缓存到达fielddata.cache.size的时候就会启动自动清理机制。expire配置不建议使用。
3.indices.breaker.request.limit限制查询的其他部分需要用的内存大小。indices.breaker.total.limit限制总(fieldData+其他部分)大小。
4.创建mapping时,可以设置fieldData format控制缓存数据格式。
ElasticSearch 429 Too Many Requests circuit_breaking_exception的更多相关文章
- 429 too many requests错误出现在wordpress后台更新及官网的5种解决方法
从今年10月份开始wordpress服务经常出现429 too many requests错误,包括后台更新和访问wp官网,如下图所示,这是为什么呢?怎么处理呢?有大佬向官方论坛提问了,论坛主持人Ja ...
- 修复 Elasticsearch 集群的常见错误和问题
文章转载自:https://mp.weixin.qq.com/s/8nWV5b8bJyTLqSv62JdcAw 第一篇:Elasticsearch 磁盘使用率超过警戒水位线 从磁盘常见错误说下去 当客 ...
- Http_4个新的http状态码:428、429、431、511
1.428 Precondition Required (要求先决条件) 先决条件是客户端发送 HTTP 请求时,必须要满足的一些预设条件.一个好的例子就是 If-None-Match 头,经常用在 ...
- Http协议4个新的http状态码:428、429、431、511;
1.428 Precondition Required (要求先决条件) 先决条件是客户端发送 HTTP 请求时,必须要满足的一些预设条件.一个好的例子就是 If-None-Match 头,经常用在 ...
- 解决laravel 429请求错误
429 Too Many Requests(过多请求) 用户在在指定的时间里发送了太多的请求.用于限制速率. 这是laravel的api访问频率 找出throttle 这个中间件,注释掉.429问题 ...
- (转)RESTful API 设计最佳实践
原文:http://www.oschina.net/translate/best-practices-for-a-pragmatic-restful-api 数据模型已经稳定,接下来你可能需要为web ...
- Spring Cloud Alibaba - SkyWalking
SkyWalking 简介 分布式链路跟踪是分布式系统的应用程序性能监视工具,专为微服务.云原生架构和基于容器(Docker.K8s)架构而设计: 也就是说Skywalking是用于微服务的" ...
- 【php爬虫】百万级别知乎用户数据爬取与分析
代码托管地址:https://github.com/hoohack/zhihuSpider 这次抓取了110万的用户数据,数据分析结果如下: 开发前的准备 安装Linux系统(Ubuntu14.04) ...
- http-code 未译
1xx Informational Request received, continuing process. This class of status code indicates a provis ...
随机推荐
- Docker原理及使用
虚拟化系统: 1. Type-I: 此种虚拟化是Hypervisor直接运行在硬件之上,来创建虚拟机. 2. Type-II: 这种虚拟化类似与VMware Workstations. IPC: 在相 ...
- 实践分布式配置中心Apollo
简介 Apollo(阿波罗)是携程框架部门研发的分布式配置中心,能够集中化管理应用不同环境.不同集群的配置,配置修改后能够实时推送到应用端,并且具备规范的权限.流程治理等特性,适用于微服务配置管理场景 ...
- 【转】聊聊并发(一)——深入分析Volatile的实现原理
即两个或多个进程读写某些共享数据,而最后的结果取决于进程运行的精确时序,称为竞争条件(race condition). 引言 在多线程并发编程中synchronized和Volatile都扮演着重要的 ...
- Postman 插件安装和使用
1.google商店 搜索“谷歌访问助手” 2.在商店搜索Postman 3.安装Postman 4.访问chrome://apps/ 5.点击postman
- Vue系列——如何运行一个Vue项目
声明 本文转自:如何运行一个Vue项目 正文 一开始很多刚入手vue.js的人,会扒GitHub上的开源项目,但是发现不知如何运行GitHub上的开源项目,很尴尬.通过查阅网上教程,成功搭建好项目环境 ...
- MIME类型和Java类型
MIME类型和Java类型 类型转换Spring Cloud Stream提供的开箱即用如下表所示:“源有效载荷”是指转换前的有效载荷,“目标有效载荷”是指转换后的“有效载荷”.类型转换可以在“生产者 ...
- Windows下将网络共享目录挂载到指定文件夹
简述 因为某些原因,设计好的目录结构是不能动的,因此需要将网络共享目录挂载到指定目录下,以便扩容. 在Linux下这完全没有问题,但是Windows下的操作就稍微复杂一点. 1.直接使用net use ...
- 大数据常见端口汇总-hadoop、hbase、hive、spark、kafka、zookeeper等(持续更新)
常见端口汇总:Hadoop: 50070:HDFS WEB UI端口 8020 : 高可用的HDFS RPC端口 9000 : 非高可用的HDFS RPC端口 8088 ...
- WD MyBook Live Duo 重装教程
9102年了,我还在用MBL DUO 前情提要:这个设备基础配置是3T*2,但是近期两块3T硬盘需要另做他用,因此只能用2块1T的硬盘来替换了,所以就免不了要重灌WD的固件.可能是由于设备太老吧,那个 ...
- SQL Server 2008 R2 安装 下载
[参考]https://www.aiweibk.com/6697.html winrm 服务未启动,需要先配置.以管理员身份启动 cmd,执行 winrm quickconfig 命令. 微信截图_2 ...