将博客转成pdf
前些天无意间看到了“birdben”的博客,写的比较详细,但是最新的文章更新时间是“2017-05-07”,时间很是久远,本打算有时间认真学习一下博主所写的文章,但是担心网站会因为某些原因停止服务,于是想到将博主写的所有文章爬下来保存成pdf,说干就干!
你们可以点击这里,查看博主的网站。
一、使用到的模块
pdfkit:可以将文本、html、url转成pdf,但是需要安装wkhtmltopdf.exe,并获取它的安装路径
pdfkit是基于wkhtmltopdf的python封装,支持url,本地文件,文本内容转成pdf,最终还是调用wkhtmltopdf的命令
PyPDF2:处理pdf的模块,可读可写可合并
二、思路分析
1、博客url分析
主页url:https://birdben.github.io/
第二页url:https://birdben.github.io/page/2/
最后一页url:https://birdben.github.io/page/14/
某篇文章的url:

查看主页的html
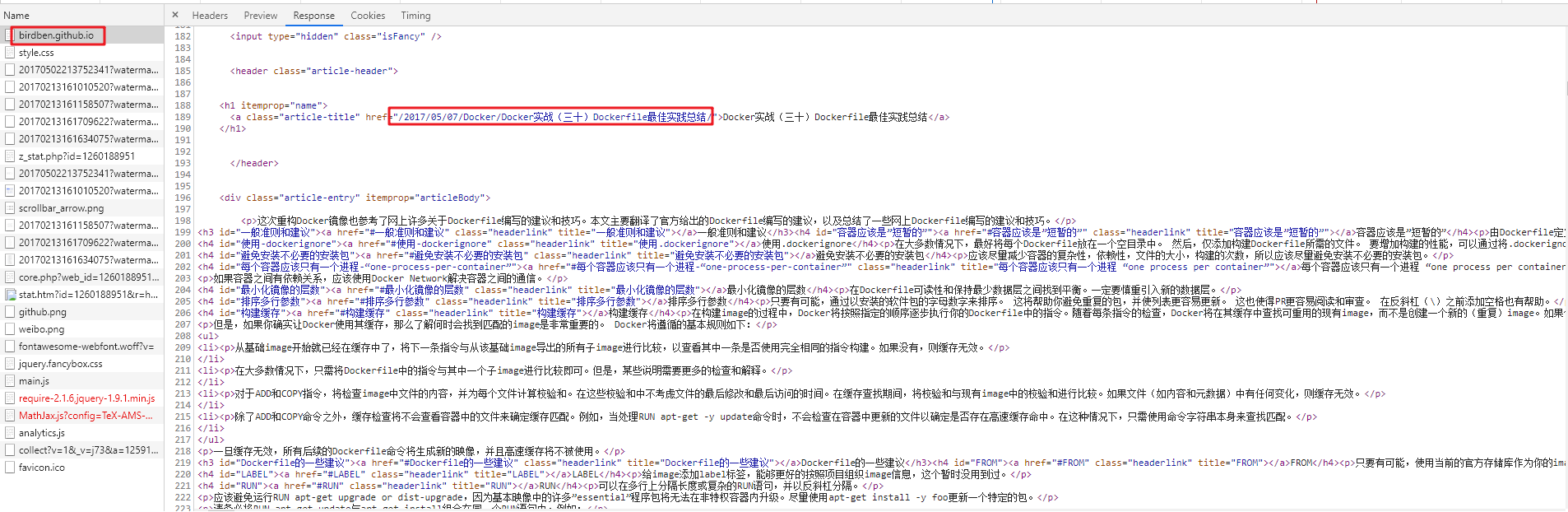
可以看出:该博客网站共有15个主页面,每篇文章的url可以使用 “主页url” + “href” (见上图)
2、整体思路
- 生成所有页面的url列表
- 遍历每个页面的url,在html中匹配出每个文章的href,拼接成每个文章的url
- 利用url生成pdf
- 合并pdf
三、代码过程
1、博客网站共有15个页面,生成这15个页面的url
def geturl():
url = "https://birdben.github.io/archives/"
list = [url]
for i in range(2,15):
str = "%spage/%d/" % (url,i)
list.append(str)
return list
返回的结果:

2、根据已经获得的页面url,读取url,查看html,匹配符合要求的href
def getname(url,):
r = requests.get ( url )
str = "".join(r.text)
pattern = re.compile(r'<a class="archive-article-title" href="(.*)">.*?</a>')
match = pattern.findall(str)
r.close()
return match
结果:

3、拼接url,生成每个文章的url,利用url转成pdf
4、合并pdf
四、最终代码
import requests
import re
import pdfkit
from PyPDF2 import PdfFileReader, PdfFileMerger
import os #获取一个页面所有的 文章全称 用于构建每篇文章的url路径
def getname(url,):
r = requests.get ( url )
str = "".join(r.text)
pattern = re.compile(r'<a class="archive-article-title" href="(.*)">.*?</a>')
match = pattern.findall(str)
r.close()
return match #获取他的所有页面,每个页面会有很多文章
def geturl():
url = "https://birdben.github.io/archives/"
list = [url]
for i in range(2,15):
str = "%spage/%d/" % (url,i)
list.append(str)
return list #将url转换成pdf
def savepdf(url,pdfname):
path_wkthmltopdf = r"C:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe"
config = pdfkit.configuration ( wkhtmltopdf=path_wkthmltopdf )
pdfkit.from_url ( url , pdfname , configuration=config ) #爬取所有文章转成pdf
def do():
urllist = geturl()
for url in urllist:
namelist = getname(url)
for blog in namelist:
blogurl = "https://birdben.github.io" + blog
pdfname = r"pdf\%s.pdf" % blog.strip("/").split("/")[-1] #将pdf保存到当前目录下的pdf目录下,需提前创建
print(blogurl,pdfname)
savepdf(blogurl,pdfname) #合并pdf
def mergepdf(tmpdir,mergename): #合并文件存放的路径,合并后的pdf文件名
merger = PdfFileMerger()
listfile = [os.path.join(tmpdir, file) for file in os.listdir(tmpdir)]
for file in listfile:
if file.endswith('.pdf'):
filemsg = PdfFileReader(open(file, 'rb'))
label = file.split('\\')[-1].replace(".pdf", "")
merger.append (filemsg, bookmark=label , import_bookmarks=False)
merger.write(mergename)
merger.close()
以上代码是使用到的所有函数
执行:
if __name__ == '__main__':
do()
#mergepdf("merge",r"merge\docker.pdf") 当do函数执行完后,将需要合并的pdf放到merge目录下(提前创建),再将do注释,再执行mergepdf函数即可
爬取所有文章生成pdf,将生成的pdf放在pdf目录下,需提前创建
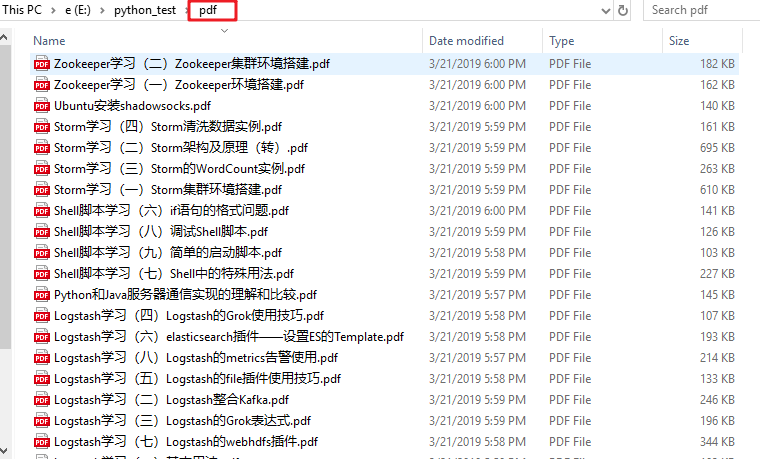
将每部分pdf拷贝到另外目录merge下
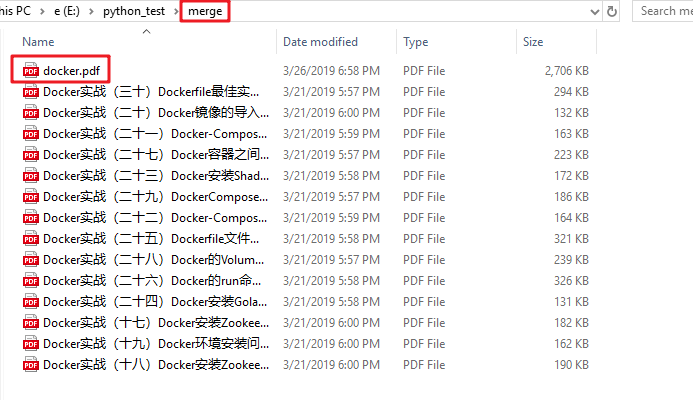
最终的pdf:

将博客转成pdf的更多相关文章
- 我是如何将博客转成PDF的
前言 只有光头才能变强 之前有读者问过我:"3y你的博客有没有电子版的呀?我想要份电子版的".我说:"没有啊,我没有弄过电子版的,我这边有个文章导航页面,你可以去文章导航 ...
- 将Medium中的博客导出成markdown
Medium(https://medium.com)(需要翻墙访问)是国外非常知名的一个博客平台.上面经常有很多知名的技术大牛在上面发布博客,现在一般国内的搬运的技术文章大多数都是来自于这个平台. M ...
- 爬取王垠的博客并生成pdf
尚未完善,有待改进 #!/usr/bin/env python3 # -*- coding: utf-8 -*- __author__ = 'jiangwenwen' import pdfkit im ...
- ahk打印成pdf记录
软工课程后记: 要求将博客打印成pdf存档.为了偷懒,不想自己点鼠标一个个保存,所以写了一个ahk小程序.博客教程推荐,建议一试,不难.还很方便.我也只学了点点皮毛,满足需求即止. 第一个成功的小例子 ...
- 推荐一款自己的软件作品[豆约翰博客备份专家],新浪博客,QQ空间,CSDN,cnblogs博客备份,导出CHM,PDF(转载)
推荐一款自己的软件作品[豆约翰博客备份专 豆约翰博客备份专家是完全免费,功能强大的博客备份工具,博客电子书(PDF,CHM和TXT)生成工具,博文离线浏览工具,软件界面美观大方,支持多个主流博客网站( ...
- MarkWord - 可发布博客的 Markdown编辑器 代码开源
因为前一段时间看到 NetAnalyzer 在Windows10系统下UI表现惨不忍睹,所以利用一段时间为了学习一下WPF相关的内容,于是停停写写,用了WPF相关的技术,两个星期做了一个Markdow ...
- 利用hexo+github+nodejs搭建自我博客的一天
放一张比较喜欢的背景图镇楼,伪文艺一波.因为刚刚抱着四个快递从公司大门走到宿舍,快递都比我高,坐电梯的时候电梯里面的灯一闪一闪,电梯还摇晃,上演了一波鬼吹灯,惊魂未定... 说正题:我喜欢的博客应该是 ...
- 基于 Hexo + GitHub Pages 搭建个人博客(二)
在 基于 Hexo + GitHub Pages 搭建个人博客(一) 这篇文章中,我们已经知道如何使用 Hexo + GitHub Pages 搭建一个个人博客,GitHub 为我们提供了免费的域名和 ...
- 历时25天,我的博客(www.ityouknow.com)终于又活了过来
时间回到2016年的7月10号,那时候我刚刚开始正式在博客园写博客,博客园的交流氛围很好,但鉴于博客园古老的界面,同时计划创建一个自己独立的博客,毕竟自己的博客怎么折腾都行. 那时候正在研究 Spri ...
随机推荐
- spring Boot + MyBatis + Maven 项目,日志开启打印 sql
在 spring Boot + MyBatis + Maven 项目中,日志开启打印 sql 的最简单方法,就是在文件 application.properties 中新增: logging.leve ...
- nuxt build 项目文件分析、nuxt build 发布后的资源如何部署cdn
建议在项目发布的时候,还是将.nuxt 进行发布到生产环境,是比较稳妥的做法 出处:https://nickfu.com/p/150 nuxt build 后的前端资源都会存放在.nuxt/dist/ ...
- [Algorithm] 242. Valid Anagram
Given two strings s and t , write a function to determine if t is an anagram of s. Example 1: Input: ...
- linux 下安装git的步骤方法
①.获取github最新的Git安装包下载链接,进入Linux服务器,执行下载,命令为: wget https://github.com/git/git/archive/v2.17.0.tar.gz ...
- 异常STATUS_FATAL_APP_EXIT(0x40000015)
简介 STATUS_FATAL_APP_EXIT,值为0x40000015.代表的意思是"致命错误,应用退出".它定义在 ntstatus.h头文件里,如下: //// Messa ...
- ent 基本使用十九 事务处理
ent 生成的代码中client 提供了比较全的事务处理 启动单个事务进行处理 // GenTx generates group of entities in a transaction. func ...
- 链表 | 判断链表B是否为链表A的连续子序列
王道P38T16 代码: bool common_subSequence(LinkList &A,LinkList &B){ LNode *pA,*pB=B->next,*p=A ...
- 编译错误: file not found with angled include use quotes instead #include <lualib.h> 和 #include "lualib.h"
http://stackoverflow.com/questions/17465902/use-of-external-c-headers-in-objective-c 问题: 7down votef ...
- AttributeError: 'Model' object has no attribute 'name'
Traceback (most recent call last): File "<ipython-input-15-7fa9988e38ef>", line 1, i ...
- 域名解析前面的前缀* @ www 分别代表什么
www 是指域名前带 www的,以百度为例,就是 www.baidu.com@ 是指前面不带任何主机名的,以百度为例,就是 baidu.com* 是指泛解析,是指除已添加的解析记录以外的所有主机都以此 ...