Zookeeper 集群的安装及高可用性验证已完成!
安装包
kafka_2.12-0.10.2.0.tgz
zookeeper-3.3.5.tar.gz
Java 环境
Zookeeper 和 Kafka 的运行都需要 Java 环境,Kafka 默认使用 G1 垃圾回收器。如果不更改垃圾回收期,官方推荐使用 7u51 以上版本的 JRE 。如果使用老版本的 JRE,需要更改 Kafka 的启动脚本,指定 G1 以外的垃圾回收器。
本文使用系统自带的 Java 环境。

Zookeeper 集群搭建
简介
Kafka 依赖 Zookeeper 管理自身集群(Broker、Offset、Producer、Consumer等),所以先要安装 Zookeeper。
为了达到高可用的目的,Zookeeper 自身也不能是单点,接下来就介绍如何搭建一个最小的 Zookeeper 集群(3个 zk 节点)。
安装
# tar zxvf zookeeper-3.3.5.tar.gz
# mv zookeeper-3.3.5 zookeeper
配置
配置文件位置
路径:zookeeper/conf
生成配置文件
将 zoo_sample.cfg 复制一份,命名为 zoo.cfg,此即为Zookeeper的配置文件。
# cd zookeeper
# cd conf
# cp zoo_sample.cfg zoo.cfg
编辑配置文件
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/opt/zookeeper-3.3.5/data
dataLogDir=/opt/zookeeper-3.3.5/logs
# the port at which the clients will connect
clientPort=12181 #自定义端口
server.3=172.19.160.X:12888:13888
server.4=172.19.160.X:12888:13888
server.5=172.19.160.X:12888:13888
server.3 4 5 必须跟myid里面的数字一样 设置成3 4 5 。否则会报错
说明:
#server.1 这个1是服务器的标识也可以是其他的数字, 表示这个是第几号服务器,用来标识服务器,这个标识要写到快照目录下面myid文件里
#IP为集群里的IP地址,第一个端口是master和slave之间的通信端口,默认是2888,第二个端口是leader选举的端口,
集群刚启动的时候选举或者leader挂掉之后进行新的选举的端口默认是3888
#tickTime:
这个时间是作为 Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。
#initLimit:
这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper
服务器集群中连接到 Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 5个心跳的时间(也就是 tickTime)
长度后 Zookeeper 服务器还没有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是 5*2000=10 秒
#syncLimit:
这个配置项标识 Leader 与Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是5*2000=10秒
#dataDir:
快照日志的存储路径
#dataLogDir:
事物日志的存储路径,如果不配置这个那么事物日志会默认存储到dataDir制定的目录,这样会严重影响zk的性能,当zk吞吐量较大的时候,产生的事物日志、快照日志太多
#clientPort:
这个端口就是客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求。修改他的端口改大点
创建 myid 文件
分别在三台主机的 dataDir 路径下创建一个文件名为 myid 的文件,文件内容为该 zk 节点的编号。
例如,在第一台主机上建立的 myid 文件内容是 0,第二台是 1。
7. 启动
启动三台主机上的 zookeeper 服务
# cd bin
# ./zkServer.sh start
返回信息:

8. 查看集群状态
3个节点启动完成后,可依次执行如下命令查看集群状态:
./zkServer.sh status
192.168.6.128 返回:

192.168.6.129 返回:

192.168.6.130 返回:

如上所示,3个节点中,有1个 leader 和两个 follower。
9. 测试集群高可用性
1)停掉集群中的为 leader 的 zookeeper 服务,本文中的leader为 server2。
# ./zkServer.sh stop
返回信息:

2)查看集群中 server0 和 server1 的的状态
server0:

server1:

此时,server1 成为了集群中的 leader,server0依然为 follower。
3)启动 server2 的 zookeeper 服务,并查看状态
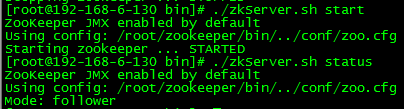
此时,server2 成为了集群中的 follower。
此时,Zookeeper 集群的安装及高可用性验证已完成!
jps查看进程
zookeeper内存调整方法
zookeeper3.4.5内存分配
对于zookeeper内存设置多大有些疑问,这里给大家解惑一下:
首先介绍一下该如何分配内存:
文件路径:zookeeper/bin/zkEnv.sh

该文件已经明确说明有独立JVM内存的设置文件,路径是zookeeper/conf/Java.env
安装的时候这个路径下没有有java.env文件,需要自己新建一个:
vi java.env
java.env文件内容如下:
#!/bin/sh
export JAVA_HOME=/usr/java/jdk
# heap size MUST be modified according to cluster environment
export JVMFLAGS="-Xms512m -Xmx1024m $JVMFLAGS"
对于内存的分配,还是根据项目和机器情况而定。如果内存够用,适当的大点可以提升zk性能。
Zookeeper 集群的安装及高可用性验证已完成!的更多相关文章
- ZooKeeper 集群的安装、配置---Dubbo 注册中心
ZooKeeper 集群的安装.配置.高可用测试 Dubbo 注册中心集群 Zookeeper-3.4.6 Dubbo 建议使用 Zookeeper 作为服务的注册中心. Zookeeper 集群中只 ...
- Dubbo入门到精通学习笔记(十三):ZooKeeper集群的安装、配置、高可用测试、升级、迁移
文章目录 ZooKeeper集群的安装.配置.高可用测试 ZooKeeper 与 Dubbo 服务集群架构图 1. 修改操作系统的/etc/hosts 文件,添加 IP 与主机名映射: 2. 下载或上 ...
- zookeeper集群的安装和配置
Zookeeper的目的是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的系统提供给用户.Zookeeper有两种运行模式,单机模式(Standalone)和集群模式(Distrib ...
- Zookeeper集群的安装和使用
Apache Zookeeper 由 Apache Hadoop 的 Zookeeper 子项目发展而来,现已经成为 Apache 的顶级项目,它是一个开放源码的分布式应用程序协调服务,是Google ...
- zookeeper集群环境安装配置
众所周知,Zookeeper有三种不同的运行环境,包括:单机环境.集群环境和集群伪分布式环境 在此介绍的是集群环境的安装配置 一.下载: http://apache.fayea.com/zookeep ...
- zookeeper集群的安装
顾名思义zookeeper就是动物园管理员,他是用来管hadoop(大象).Hive(蜜蜂).pig(小猪)的管理员, Apache Hbase和 Apache Solr 的分布式集群都用到了zook ...
- ZooKeeper集群的安装、配置、高可用测试
Dubbo注册中心集群Zookeeper-3.4.6 Dubbo建议使用Zookeeper作为服务的注册中心. Zookeeper集群中只要有过半的节点是正常的情况下,那么整个集群对外就是可用的.正是 ...
- ZooKeeper集群详细安装教程
1. 安装JDK 1.1 官网下载JDK 进入网址<a href="http://www.oracle.com/technetwork/java/javase/downloads/jd ...
- 大数据集群环境 zookeeper集群环境安装
大数据集群环境 zookeeper集群环境准备 zookeeper集群安装脚本,如果安装需要保持zookeeper保持相同目录,并且有可执行权限,需要准备如下 编写脚本: vi zkInstall.s ...
随机推荐
- 【JavaScript性能优化】------理解Script标签的加载和执行
1.script标签是如何加载的?当浏览器遇到一个 < script>标签时,浏览器会停下来,运行JavaScript代码,然后再继续解析.翻译页面.同样的事情发生在使用 src 属性加载 ...
- 在centos上安装nodejs
之前在百度云上买了个服务器,选择的centos 64位系统. 买完之后一顿折腾,今天就来讲讲怎么安装node和npm,刚开始在Google上找了好多方法,都是费时.费力,最后还是没有安装成功,下面将介 ...
- VIM编辑器使用及插件配置
1.VIM的三种模式: 普通模式.插入模式.命令行模式2.三种模式的转换: 2.1进入普通模式 ①打开VIM默认为普通模式 ②处于插入模式/命令行模式时,按ESC进入普通模式 2.2进入插入模式: A ...
- Nuget--基础连接已经关闭
1.Nuget---基础连接已经关闭: 未能为 SSL/TLS 安全通道建立信任关系 修改一下 Package Source 改为 http://packages.nuget.org 2.Nuget- ...
- koa2入门笔记
[TOC] 一 什么是koa koa是基于nodejs的web框架, 是一个中间件框架. 二 中间件 Koa 中间件是简单的函数,它是带有 (ctx, next)形参 的函数. 可以采用两种不同的方法 ...
- Centos防火墙设置与端口开放
前言 最近在部署项目的时候遇到了一些问题,阿里云主机要配置安全组策略和端口.对于这点看到了一片好的博文,特此总结记录下. iptables 方法一 打开某个端口 // 开启端口 iptables -A ...
- SVN版本管理 目录结构
一. SVN标准目录 Subversion有一个很标准的目录结构,是这样的.比如项目是 proj,svn地址为 svn://proj/,那么标准的 svn 布局是: 这是一个标准的布局,trunk为主 ...
- 2019CCPC网络赛 HDU6705 - path K短路
题意:给出n个点m条边的有向图,问图上第K短路的长度是多少(这里的路可以经过任何重复点重复边). 解法:解法参考https://blog.csdn.net/Ratina/article/details ...
- UML的9种图例解析(转)
原帖已经不知道是哪一个,特在此感谢原作者.如有侵权,请私信联系.看到后即可删除. UML图中类之间的关系:依赖,泛化,关联,聚合,组合,实现 类与类图 1) 类(Class)封装了数据和行为,是面向对 ...
- H3C F100-S-G2接口配置
网络环境简单一台F100-S-G2(192.168.1.197),一台S3600,三台服务器(同一网段192.168.1~3),实现互通. 其他都不用说了配置成同一网段地址就行,主要说一下F100配置 ...