图的深度优先搜索(DFS)和广度优先搜索(BFS)算法
深度优先(DFS)
深度优先遍历,从初始访问结点出发,我们知道初始访问结点可能有多个邻接结点,深度优先遍历的策略就是首先访问第一个邻接结点,然后再以这个被访问的邻接结点作为初始结点,访问它的第一个邻接结点。总结起来可以这样说:每次都在访问完当前结点后首先访问当前结点的第一个邻接结点。
我们从这里可以看到,这样的访问策略是优先往纵向挖掘深入,而不是对一个结点的所有邻接结点进行横向访问。
算法大概过程:
1.把整个图的结构用矩阵来表示,如图:
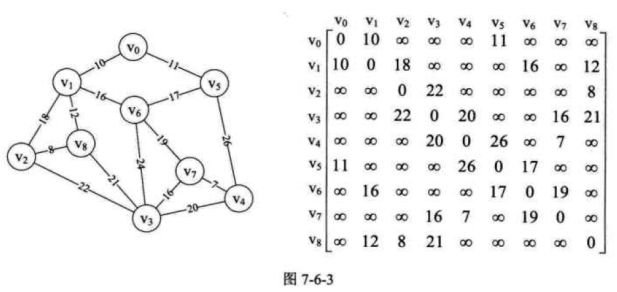
2.我们从第一个顶点(v0)开始遍历,拿到第一个邻接点(二维矩阵里是v1),这个时候我们再对v1进行遍历,v0已经被访问过了所以选择跳过,这时再拿到v2,对v2开始进行遍历。。。以此类推!
代码实现如下:
// 获取某顶点的第一个邻接点
private int getFirstNeighbor(int index) {
for (int i = 0; i < vertexSize; i++) {
if (matrix[index][i] > 0 && matrix[index][i] < MAX_WEIGHT) {
// 找到了第一邻接点
return i;
}
}
return -1;
} // 根据前一个邻接点下标,来取得下一个邻接点
/**
* @param v1
* 表示要找的顶点
* @param index
* 表示该顶点相对于哪个邻接点去获取下一个邻接点
* @return
*/
private int getNextNeighbor(int v1, int index) {
for (int i = index + 1; i < vertexSize; i++) {
if (matrix[v1][i] > 0 && matrix[v1][i] < MAX_WEIGHT) {
return i;
}
}
return -1;
} private void depthSearch(int i) {
isVisited[i] = true;// 证明当前顶点被访问过了
// 获取当前顶点的邻接点
int w = getFirstNeighbor(i);
// 只要w不是-1
while (w != -1) {
// 证明i确实有邻接点
// 判断w是否被访问过
if (!isVisited[w]) {
// 如果没有被访问过,就继续深度遍历w顶点
System.out.println("深度优先访问到的顶点:" + w);
depthSearch(w);
}
// 如果当前邻接点被访问过了,就继续搜索除了这个w外其他的点
w = getNextNeighbor(i, w);
}
} public void depthFirstSearch() {
// 这是对外提供
isVisited = new boolean[vertexSize];
for (int i = 0; i < vertexSize; i++) {
if (!isVisited[i]) {
System.out.println("深度优先访问到的顶点:" + i);
depthSearch(i);
}
}
// 遍历完后,记得把布尔数组归为
isVisited = new boolean[vertexSize];
}
广度优先(BFS)
广度优先搜索类似于我们的二叉树的层次遍历,我们还是以v0作为起始点,根据二维矩阵,我们找到v0的第一个邻接点,之后再找到v0的第二个邻接点,直到找不到v0的邻接点为止,由图可知,v0就俩邻接点v1,v5。遍历完后,继续遍历v1的邻接点,v1的遍历完后,开始遍历v5的。。。以此类推!
代码如下:
// 广度优先遍历算法
public void broadFirstSearch() {
isVisited = new boolean[vertexSize];
for (int i = 0; i < vertexSize; i++) {
if (!isVisited[i]) {
System.out.println("广度优先访问到的顶点:" + i);
broadSearch(i);
}
}
isVisited = new boolean[vertexSize];
} private void broadSearch(int i) {
// 类似于二叉树的层次遍历
int u, w;
LinkedList<Integer> queue = new LinkedList<>();
isVisited[i] = true;
queue.add(i);
while (!queue.isEmpty()) {
u = queue.removeFirst();// 顶点
w = getFirstNeighbor(u);
while (w != -1) {
if (!isVisited[w]) {
System.out.println("广度优先访问到的顶点:" + w);
isVisited[w] = true;
queue.add(w);
}
// 拿到后面的邻接点
w = getNextNeighbor(u, w);
}
}
}
图的深度优先搜索(DFS)和广度优先搜索(BFS)算法的更多相关文章
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)
body, table{font-family: 微软雅黑; font-size: 13.5pt} table{border-collapse: collapse; border: solid gra ...
- 图的深度优先遍历(DFS)和广度优先遍历(BFS)算法分析
1. 深度优先遍历 深度优先遍历(Depth First Search)的主要思想是: 1.首先以一个未被访问过的顶点作为起始顶点,沿当前顶点的边走到未访问过的顶点: 2.当没有未访问过的顶点时,则回 ...
- 【C++】基于邻接矩阵的图的深度优先遍历(DFS)和广度优先遍历(BFS)
写在前面:本博客为本人原创,严禁任何形式的转载!本博客只允许放在博客园(.cnblogs.com),如果您在其他网站看到这篇博文,请通过下面这个唯一的合法链接转到原文! 本博客全网唯一合法URL:ht ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析(新手向)
深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每个点仅被访问一次,这个过程就是图的遍历.图的遍历常用的有深度优先搜索和广度优先搜索,这两者对于有向图和无向图 ...
- 深度优先搜索DFS和广度优先搜索BFS简单解析
转自:https://www.cnblogs.com/FZfangzheng/p/8529132.html 深度优先搜索DFS和广度优先搜索BFS简单解析 与树的遍历类似,图的遍历要求从某一点出发,每 ...
- 深度优先搜索DFS和广度优先搜索BFS
DFS简介 深度优先搜索,一般会设置一个数组visited记录每个顶点的访问状态,初始状态图中所有顶点均未被访问,从某个未被访问过的顶点开始按照某个原则一直往深处访问,访问的过程中随时更新数组visi ...
- 图的 储存 深度优先(DFS)广度优先(BFS)遍历
图遍历的概念: 从图中某顶点出发访遍图中每个顶点,且每个顶点仅访问一次,此过程称为图的遍历(Traversing Graph).图的遍历算法是求解图的连通性问题.拓扑排序和求关键路径等算法的基础.图的 ...
- js图的数据结构处理----邻链表,广度优先搜索,最小路径,深度优先搜索,探索时间拓扑
//邻居连表 //先加入各顶点,然后加入边 //队列 var Queue = (function(){ var item = new WeakMap(); class Queue{ construct ...
- 图的深度优先搜索算法DFS
1.问题描写叙述与理解 深度优先搜索(Depth First Search.DFS)所遵循的策略.如同其名称所云.是在图中尽可能"更深"地进行搜索. 在深度优先搜索中,对最新发现的 ...
随机推荐
- Python 入门之 内置模块 --logging模块
Python 入门之 内置模块 --logging模块 1.logging -- 日志 (1)日志的作用: <1> 记录用户信息 <2> 记录个人流水 <3> 记录 ...
- sys模块&json模块&pickle模块
sys模块&json模块&pickle模块 sys模块 一.导入方式 import sys 二.作用 与Python解释器交互 三.模块功能 3.1 经常使用 sys.path #返回 ...
- Ajax提交数据后,清空form表单
按钮不同,页面相同,还需要显示的数据不同,这里会由于页面的缓存问题,导致,每次点开这个页面显示的数据相同. 这不是我们想要的.这就需要清楚表单数据了. 如下: $('#myform')[0].rese ...
- 在 Chrome DevTools 中调试 JavaScript 入门
第 1 步:重现错误 找到一系列可一致重现错误的操作始终是调试的第一步. 点击 Open Demo. 演示页面随即在新标签中打开. OPEN DEMO 在 Number 1 文本框中输入 5. 在 N ...
- 解决 SQLPlus无法登陆oracle,PLSql可以登陆,报错ORA-12560
使用Oracle 11g 64位服务器,安装64位.32位客户端,出现SQLPlus无法连接数据库,PLSql可以连接问题. 网上查了很多,都不能解决问题,在下面提供一种. 环境变量 右击计算机属性- ...
- Vue组件通信方式(8种)
1.一图认清组件关系名词 父子关系:A与B.A与C.B与D.C与E 兄弟关系:B与C 隔代关系:A与D.A与E 非直系亲属:D与E 总结为三大类: 父子组件之间通信 兄弟组件之间通信 跨级通信 2.8 ...
- calculate_gain
torch.nn.init.calculate_gain(nonlinearity,param=None) 对于给定的非线性函数,返回推荐的增益值.这些值如下所示: relu_gain=nn.init ...
- feign 发送请求时,传多个参数时的写法
第一:传参方式写法,当参数个数大于2个时,需要用@RequestParam @PostMapping(value = "/configReader/configValue.do", ...
- 设计模式来替代if-else
前言# 物流行业中,通常会涉及到EDI报文(XML格式文件)传输和回执接收,每发送一份EDI报文,后续都会收到与之关联的回执(标识该数据在第三方系统中的流转状态).这里枚举几种回执类型:MT1101. ...
- Linux 环境下 jar 加解密命令?
1.源码打jar包 jar -cvf demo-source.jar -C src/ . > log.txt 2.编译字节打jar包 jar -cvf demo-class.jar -C bin ...