SolrCloud集群
1 SolrCloud简介
1.1什么是SolrCloud
SolrCloud(solr 云)是 Solr 提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用 SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用 SolrCloud 来满足这些需求。
SolrCloud 是基于 Solr 和Zookeeper的分布式搜索方案,它的主要思想是使用 Zookeeper作为集群的配置信息中心。
它有几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
1.2 SolrCloud系统架构
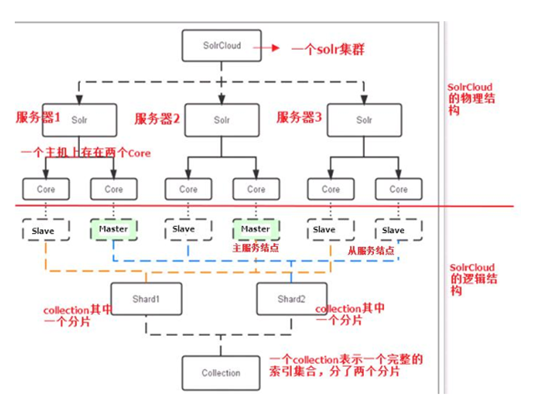
【1】物理结构
三个 Solr 实例( 每个实例包括两个 Core),组成一个 SolrCloud。
【2】逻辑结构
索引集合包括两个 Shard(shard1 和 shard2),shard1 和 shard2 分别由三个 Core 组成,其中一个 Leader 两个 Replication,Leader 是由 zookeeper 选举产生,zookeeper 控制每个shard上三个 Core 的索引数据一致,解决高可用问题。
用户发起索引请求分别从 shard1 和 shard2 上获取,解决高并发问题。
(1)Collection
Collection 在 SolrCloud 集群中是一个逻辑意义上的完整的索引结构。它常常被划分为一个或多个 Shard(分片),它们使用相同的配置信息。
比如:针对商品信息搜索可以创建一个 collection。
collection=shard1+shard2+....+shardX
(2) Core
每个 Core 是 Solr 中一个独立运行单位,提供 索引和搜索服务。一个 shard 需要由一个Core 或多个 Core 组成。由于 collection 由多个 shard 组成所以 collection 一般由多个 core 组成。
(3)Master 或 Slave
Master 是 master-slave 结构中的主结点(通常说主服务器),Slave 是 master-slave 结构中的从结点(通常说从服务器或备服务器)。同一个 Shard 下 master 和 slave 存储的数据是一致的,这是为了达到高可用目的。
(4)Shard
Collection 的逻辑分片。每个 Shard 被化成一个或者多个 replication,通过选举确定哪个是 Leader。
2 搭建SolrCloud
2.1搭建要求
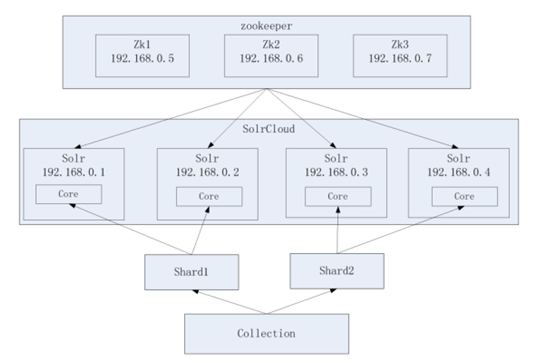
Zookeeper 作为集群的管理工具
1、集群管理:容错、负载均衡。
2、配置文件的集中管理
3、集群的入口
需要实现 zookeeper 高可用,需要搭建zookeeper集群。建议是奇数节点。需要三个 zookeeper 服务器。
搭建 solr 集群需要 7 台服务器(搭建伪分布式,建议虚拟机的内存 1G 以上):
需要三个 zookeeper 节点
需要四个 tomcat 节点。
2.2准备工作
环境准备
CentOS-6.5-i386-bin-DVD1.iso
jdk-7u72-linux-i586.tar.gz
apache-tomcat-7.0.47.tar.gz
zookeeper-3.4.6.tar.gz
solr-4.10.3.tgz
步骤:
(1)搭建Zookeeper集群(我们在上一小节已经完成)
(2)将已经部署完solr 的tomcat的上传到linux
(3)在linux中创建文件夹 /usr/local/solr-cloud 创建4个tomcat实例
[root@localhost ~]# mkdir /usr/local/solr-cloud
[root@localhost ~]# cp -r tomcat-solr /usr/local/solr-cloud/tomcat-1
[root@localhost ~]# cp -r tomcat-solr /usr/local/solr-cloud/tomcat-2
[root@localhost ~]# cp -r tomcat-solr /usr/local/solr-cloud/tomcat-3
[root@localhost ~]# cp -r tomcat-solr /usr/local/solr-cloud/tomcat-4
(4)将本地的solrhome上传到linux
(5)在linux中创建文件夹 /usr/local/solrhomes ,将solrhome复制4份
[root@localhost ~]# mkdir /usr/local/solrhomes
[root@localhost ~]# cp -r solrhome /usr/local/solrhomes/solrhome-1
[root@localhost ~]# cp -r solrhome /usr/local/solrhomes/solrhome-2
[root@localhost ~]# cp -r solrhome /usr/local/solrhomes/solrhome-3
[root@localhost ~]# cp -r solrhome /usr/local/solrhomes/solrhome-4
(6)修改每个solr的 web.xml 文件, 关联solrhome(/usr/local/solr-cluster/tomcat-1/webapps/solr/WEB-INF/web.xml)
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/usr/local/solrhomes/solrhome-1</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
(7)修改每个tomcat的原运行端口8005 8080 8009 ,分别为
8105 8180 8109
8205 8280 8209
8305 8380 8309
8405 8480 8409
8005端口是用来关闭TOMCAT服务的端口。
8080端口,负责建立HTTP连接。在通过浏览器访问Tomcat服务器的Web应用时,使用的就是这个连接器。
8009端口,负责和其他的HTTP服务器建立连接。在把Tomcat与其他HTTP服务器集成时,就需要用到这个连接器。
2.3配置集群
(1)修改每个 tomcat实例 bin 目录下的 catalina.sh 文件
把此配置添加到catalina.sh中
JAVA_OPTS="-DzkHost=192.168.25.101:2181,192.168.25.101:2182,192.168.25.101:2183"
JAVA_OPTS ,顾名思义,是用来设置JVM相关运行参数的变量 . 此配置用于在tomcat启动时找到 zookeeper集群。
(2)配置 solrCloud 相关的配置。每个 solrhome 下都有一个 solr.xml,把其中的 ip 及端口号配置好(是对应的tomcat的IP和端口)。
solrhomes/solrhome-1/solr.xml
<solrcloud>
<str name="host">192.168.25.101</str>
<int name="hostPort">8180</int>
<str name="hostContext">${hostContext:solr}</str>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
</solrcloud>
solrhomes/solrhome-2/solr.xml
<solrcloud>
<str name="host">192.168.25.101</str>
<int name="hostPort">8280</int>
<str name="hostContext">${hostContext:solr}</str>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
</solrcloud>
solrhomes/solrhome-3/solr.xml
<solrcloud>
<str name="host">192.168.25.101</str>
<int name="hostPort">8380</int>
<str name="hostContext">${hostContext:solr}</str>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
</solrcloud>
solrhomes/solrhome-4/solr.xml
<solrcloud>
<str name="host">192.168.25.101</str>
<int name="hostPort">8480</int>
<str name="hostContext">${hostContext:solr}</str>
<int name="zkClientTimeout">${zkClientTimeout:30000}</int>
<bool name="genericCoreNodeNames">${genericCoreNodeNames:true}</bool>
</solrcloud>
(3)让 zookeeper 统一管理配置文件。
需要上传solr源码包中的zkcli.sh
1.上传solr-4.10.3.tgz.tgz
2.解压: tar -zxvf solr-4.10.3.tgz.tgz
3.找到/usr/local/solr-4.10.3/example/scripts/cloud-scripts目录下
4.输入命令:
./zkcli.sh -zkhost 192.168.25.101:2181,192.168.25.101:2182,192.168.25.101:2183 -cmd upconfig -confdir /usr/local/solrhomes/solrhome-1/collection1/conf -confname myconf
参数解释
-zkhost :指定zookeeper地址列表
-cmd :指定命令。upconfig 为上传配置的命令
-confdir : 配置文件所在目录
-confname : 配置名称
2.4启动集群
(1)启动每个 tomcat 实例。要保证 zookeeper 集群是启动状态。
进入 /usr/local/solr-cluster/tomcat-1/bin 目录
执行:(发现权限不够:回到/usr/local下给solr-cluster/授权:执行:chmod -R 777 solr-cluster) ./startup.sh
依次将四个tomcat全部启动
(注意在拷贝文件的时候,建议等几秒,不然可能考不完,发生项目缺少jar,或者文件导致启动失败)
地址栏输入:http://192.168.25.101:8180/solr/#/ 左侧有一个cloud表名集群ok了
3 代码连接集群
1.将之前的单机版注解掉,使用新的:
在SolrJ中提供一个叫做CloudSolrServer的类,它是SolrServer的子类,用于连接solrCloud
它的构造参数就是zookeeper的地址列表,另外它要求要指定defaultCollection属性(默认的 collection名称)
我们现在修改springDataSolrDemo工程的配置文件 ,把原来的solr-server注销,替换为CloudSolrServer .指定构造参数为地址列表,设置默认 collection名称
<bean id="solrServer" class="org.apache.solr.client.solrj.impl.CloudSolrServer">
<constructor-arg value="192.168.25.140:2181,192.168.25.140:2182,192.168.25.140:2183" />
<property name="defaultCollection" value="collection1"></property>
</bean>
2.使用mavenProfile方式修改打包类型
solr.xml修改配置如下:
<!-- solr服务器地址 -->
<solr:solr-server id="solrServer_dev" url="http://127.0.0.1:8080/solr" />
<bean id="solrServer_pro" class="org.apache.solr.client.solrj.impl.CloudSolrServer">
<constructor-arg value="192.168.25.101:2181,192.168.25.101:2182,192.168.25.101:2183" />
<property name="defaultCollection" value="collection1"></property>
</bean>
<!-- solr模板,使用solr模板可对索引库进行CRUD的操作 -->
<bean id="solrTemplate" class="org.springframework.data.solr.core.SolrTemplate">
<constructor-arg ref="solrServer_${env}" />
</bean>
pom新增如下:
<properties>
<env>dev</env>
</properties>
<profiles>
<profile>
<id>dev</id>
<properties>
<env>dev</env>
</properties>
</profile>
<profile>
<id>pro</id>
<properties>
<env>pro</env>
</properties>
</profile>
</profiles>
在pom文件中build新增:
<resources>
<resource>
<directory>src/main/resources</directory>
<filtering>true</filtering>
</resource>
</resources>
4 分片配置
1 创建新的 Collection 进行分片处理。
在浏览器输入以下地址,可以按照我们的要求 创建新的Collection
http://192.168.25.101:8180/solr/admin/collections?action=CREATE&name=collection2&numShards=2&replicationFactor=2
参数:
name:将被创建的集合的名字
numShards:集合创建时需要创建逻辑碎片的个数
replicationFactor:分片的副本数。
看到这个提示表示成功

2删除不用的 Collection。执行以下命令
http://192.168.25.101:8480/solr/admin/collections?action=DELETE&name=collection1
SolrCloud集群的更多相关文章
- Solr 10 - SolrCloud集群模式简介 + 组成结构的说明
目录 1 什么是SolrCloud 2 SolrCloud的结构 2.1 物理结构 2.2 逻辑结构 2.2.1 Collection(集合) 2.2.2 Core(内核) 2.2.3 Shard(分 ...
- SolrCloud集群搭建(基于zookeeper)
1. 环境准备 1.1 三台Linux机器,x64系统 1.2 jdk1.8 1.3 Solr5.5 2. 安装zookeeper集群 2.1 分别在三台机器上创建目录 mkdir /usr/hdp/ ...
- 11.SolrCloud集群环境搭建
转载请出自出处:http://www.cnblogs.com/hd3013779515/ 我们基于Solr4.10.3版本进行安装配置SolrCloud集群,通过实践来实现索引数据的分布存储和检索. ...
- JAVAEE——宜立方商城08:Zookeeper+SolrCloud集群搭建、搜索功能切换到集群版、Activemq消息队列搭建与使用
1. 学习计划 1.solr集群搭建 2.使用solrj管理solr集群 3.把搜索功能切换到集群版 4.添加商品同步索引库. a) Activemq b) 发送消息 c) 接收消息 2. 什么是So ...
- zookeeper集群-solrcloud集群
本文只写具体的搭建过程,具体原理请看官网文档.国内博客都是基本上都是通过tomcat搭建的solr,本文是通过内部集成的jetty容器搭建. 一.zookeeper集群搭建 1.安装JAVA环境,版本 ...
- ubuntu14.04环境下利用docker搭建solrCloud集群
在Ubuntu14.04操作系统的宿主机中,安装docker17.06.3,将宿主机的操作系统制作成docker基础镜像,之后使用自制的基础镜像在docker中启动3个容器,分配固定IP,再在3个容器 ...
- Linux环境下SolrCloud集群环境搭建关键步骤
Linux环境下SolrCloud集群环境搭建关键步骤. 前提条件:已经完成ZooKeeper集群环境搭建. 一.下载介质 官网下载地址:http://www.apache.org/dyn/close ...
- solrcloud集群搭建
solrcloud 集群搭建 初始条件: 1. 三台服务器 IP 地址分别为 192.168.1.133 192.168.1.134 192.168.1.135 2. 使用 solr-5.3.1,zo ...
- CentOs7.3 搭建 SolrCloud 集群服务
一.概述 Lucene是一个Java语言编写的利用倒排原理实现的文本检索类库: Solr是以Lucene为基础实现的文本检索应用服务.Solr部署方式有单机方式.多机Master-Slaver方式.C ...
随机推荐
- Django REST framework的解析器与渲染器
解析器 解析器的作用 解析器的作用就是服务端接收客户端传过来的数据,把数据解析成自己可以处理的数据.本质就是对请求体中的数据进行解析. 在了解解析器之前,我们要先知道Accept以及ContentTy ...
- MUI注
1.调试模式: 边改边看:左侧显示代码,右侧实时观看修改效果.可以调出“浏览器控制台”观测数据变化效果. 真机运行:电脑和手机都安装“360手机助手”,手机安装“F:\Program Files\HB ...
- 条形码(barcode)code128生成代码
条形码(barcode)code128生成代码 很简单 多些这位兄弟https://bbs.csdn.net/topics/350125614 下面是我的DEMO 直接放到VS2005下面编译即可 # ...
- C++获取寄存器eip的值
程序中需要打印当前代码段位置 如下 #include <stdio.h> #include <stdlib.h> #include <math.h> #ifdef ...
- 使用collection:分段查询结果集
1.在人员接口书写方法 public List<Employee> getEmpsByDeptId(Integer deptId); 2在人员映射文件中进行配置 <!-- publi ...
- 【python】集合 list差集|并集|交集
两个list差集 list(set(b).difference(set(a))) # b中有而a中没有的 示例: a=[1,2,3] b=[2,3] list(set(a).difference(se ...
- kafka多线程消费
建立kafka消费类ConsumerRunnable ,实现Runnable接口: import com.alibaba.fastjson.JSON; import com.alibaba.fastj ...
- C# 打印倒三角
void test6(int num) { try { #region 方法1 int maxstar = (num - 1) * 2 + 1; string line = ""; ...
- C++——堆、栈与内存管理
简介 Stack,是存在于某作用域(scope) 的一块内存空间(memory space).例如当你调用函数,函数本身即会形成一个stack 用來放置它所接收的参数,以及返回地址.在函数本体(fun ...
- MSSQL注入--反弹注入
明明是sql注入的点,却无法进行注入,注射工具拆解的速度异常的缓慢,错误提示信息关闭,无法返回注入的结果,这个时候你便可以尝试使用反弹注入, 反弹注入需要依赖于函数opendatasource的支持, ...