Pandas 50题练习
f行的age改为1.
df.loc['f', 'age'] = 1.5
这样比 df.loc['f']['age'] 好
计算df中每个种类animal的数量
df['animal'].value_counts()
我是 计算df中每个种类animal的数量
df.groupby('animal').count()
不好
将priority列中的yes, no替换为布尔值True, False
df['priority'] = df['priority'].map({'yes': True, 'no': False})
我的做法
df['priority'] = df['priority'].str.replace('no','false')
df['priority'] = df['priority'].str.replace('yes','true')
对每种animal的每种不同数量visits,计算平均age,即,返回一个表格,行是aniaml种类,列是visits数量,表格值是行动物种类列访客数量的平均年龄
df.pivot_table(index='animal', columns='visits', values='age', aggfunc='mean')
我的做法
res = df.groupby(by=['animal','visits'])['age'].mean() 这样是不行的
一个全数值DatraFrame,每个数字减去该行的平均数
df = pd.DataFrame(np.random.random(size=(, )))
print(df)
df1 = df.sub(df.mean(axis=), axis=)
print(df1)
我的做法
for i in range(len(df)):
for j in (df.columns):
df.loc[i,j] = df.loc[i,j] - df.loc[i].mean()
一个有5列的DataFrame,求哪一列的和最小
df = pd.DataFrame(np.random.random(size=(, )), columns=list('abcde'))
print(df)
df.sum().idxmin()
我的做法
df.sum().sort_values() 然后自己肉眼识别
给定DataFrame,求A列每个值的前3的B的值的和
df = pd.DataFrame({'A': list('aaabbcaabcccbbc'),
'B': [,,,,,,,,,,,,,,]})
print(df)
df1 = df.groupby('A')['B'].nlargest().sum(level=)
print(df1)
给定DataFrame,有列A, B,A的值在1-(含),对A列每10步长,求对应的B的和
df = pd.DataFrame({'A': [,,,,,,,,,],
'B': [,,,,,,,,,]})
print(df)
df1 = df.groupby(pd.cut(df['A'], np.arange(, , )))['B'].sum()
print(df1)
我的做法大体类似,但是稍微繁琐,对pd.groupby 理解不到位。groupby第一个参数也可以接收series或者dict,应用在dataframe的第一列值。
s = pd.cut(df['a'],bins=,labels=['one','two','three','four','five','six','seven','eight','nine','ten'])
df['label'] = s
df.groupby('label')['b'].sum()
一个全数值的DataFrame,返回最大3个值的坐标
df = pd.DataFrame(np.random.random(size=(, )))
print(df)
df.unstack().sort_values()[-:].index.tolist()
我的做法是取每个column的最大值,排序后再选最大的三个。很明显,繁琐。
注意,df必须先unstack后才能 sort_values,要不然会报错。
dti = pd.date_range(start='2015-01-01', end='2015-12-31', freq='B')
s = pd.Series(np.random.rand(len(dti)), index=dti)
s.head()
所有礼拜三的值求和
s[s.index.weekday == ].sum()
还有这种方法?!!
求每个自然月的平均数
s.resample('M').mean() 索引为时间序列的重要方法 resample 重采样
每连续4个月为一组,求最大值所在的日期
s.groupby(pd.Grouper(freq='4M')).idxmax() 我的做法
还有个pd.Grouper方法? FlightNumber列中有些值缺失了,他们本来应该是每一行增加10,填充缺失的数值,并且令数据类型为整数
df['FlightNumber'] = df['FlightNumber'].interpolate().astype(int) 我的做法
series,dataframe 都有 interpolate 这个方法,记一下 将From_To列从_分开,分成From, To两列,并删除原始列
temp = df.From_To.str.split('_', expand=True)
temp.columns = ['From', 'To']
df = df.join(temp)
df = df.drop('From_To', axis=) 我的做法
df['from'] = df['From_To'].str.split('_',expand=True)[]
df['to'] = df['From_To'].str.split('_',expand=True)[] 很明显,join更简洁,换个角度,如果列更多,我的方法就麻烦多了。
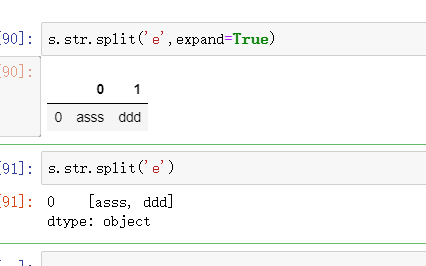
strip有个expand参数,很重要。python中的split 没有这个参数。
差别如下
Pandas 50题练习的更多相关文章
- POJ推荐50题
此文来自北京邮电大学ACM-ICPC集训队 此50题在本博客均有代码,可以在左侧的搜索框中搜索题号查看代码. 以下是原文: POJ推荐50题1.标记“难”和“稍难”的题目可以看看,思考一下,不做要求, ...
- JAVA经典算法50题(转)
转载请注明出处:http://blog.csdn.net/l1028386804/article/details/51097928 JAVA经典算法50题 [程序1] 题目:古典问题:有一对兔子, ...
- 剑指offer 面试50题
面试50题: 题目:第一个只出现一次的字符 题:在一个字符串(1<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置. 解题思路一:利用Python特 ...
- MySQL练习50题
介绍一个学习SQL的网站:https://sqlbolt.com/ 习题来源于网络,SQL语句是自己的练习答案,部分参考了网络上的答案. 花了一晚上的时间做完,个人认为其中的难点有:分组提取前几名的数 ...
- Java经典逻辑编程50题
Java经典逻辑编程50题 2016-11-03 09:29:28 0个评论 来源:Alias_fa的博客 收藏 我要投稿 [程序1] 題目:古典问题:有一对兔子,从出生后第 ...
- sql 经典查询50题 思路(一)
因为需要提高一下sql的查询能力,当然最快的方式就是做一些实际的题目了.选择了这个sql的50题,这次大概做了前10题左右,把思路放上来,也是一个总结. 具体题目见: https://zhuanlan ...
- 转:sql 经典50题--可能是你见过的最全解析
题记:从知乎上看到的一篇文章,刚好最近工作中发现遇到的题目与这个几乎一样,可能就是从这里来的吧.^_^ 里面的答案没有细看,SQL求解重在思路,很多时候同一种结果可能有多种写法,比如题中的各科成绩取前 ...
- 力扣50题 Pow(x,n)
本题是力扣网第50题. 实现 pow(x, n) ,即计算 x 的 n 次幂函数. 采用递归和非递归思路python实现. class Solution: #递归思路 def myPow_recurs ...
- sql语句练习50题(Mysql版-详加注释)
表名和字段 1.学生表 Student(s_id,s_name,s_birth,s_sex) --学生编号,学生姓名, 出生年月,学生性别 2.课程表 Course(c_id, ...
随机推荐
- django学习笔记(四)
1.请求周期 url> 路由 > 函数或类 > 返回字符串或者模板语言? Form表单提交: 提交 -> url > 函数或类中的方法 - .... HttpRespon ...
- git init error:Malformed value for push.default: simple
git init error:Malformed value for push.default: simple 1.git config --global push.default matching
- os.path.sep
python中os.path常用模块 os.path.sep:路径分隔符 linux下就用这个了’/’ os.path.altsep: 根目录 os.path.curdir:当前目录 os. ...
- Java并发-CycliBarrier
栅栏类似于闭锁,它能阻塞一组线程直到某个事件的发生.栅栏与闭锁的关键区别在于,所有的线程必须同时到达栅栏位置,才能继续执行.闭锁用于等待事件,而栅栏用于等待其他线程.package com.examp ...
- 排序二叉树、平衡二叉树、红黑树、B+树
一.排序二叉树(Binary Sort Tree,BST树) 二叉排序树,又叫二叉搜索树.有序二叉树(ordered binary tree)或排序二叉树(sorted binary tree). 1 ...
- layui 动态添加 表格数据
静态表格: <table class="layui-table" id="table" lay-filter="table"> ...
- layui token 过期 重新登陆
这个方法你要全局设置 //jquery全局配置 $.ajaxSetup({ cache: false, crossDomain: true, headers :{' ...
- 一个简单mock-server 解决方案
參考: 测试利器之Mock server 介紹 moco server - download Mockman - download 各种Mock工具比较 JMockit中文网 MockWebServe ...
- 3.docker镜像管理基础
一.docker镜像相关 1.About Docker Image Docker镜像含有启动容器所需要的文件系统及其内容,因此,其用于创建并启动docker容器. 采用分层构建机制,最底层为bootf ...
- python数据探索与数据与清洗概述
数据探索的核心: 1.数据质量分析(跟数据清洗密切联系,缺失值.异常值等) 2.数据特征分析(分布.对比.周期性.相关性.常见统计量等) 数据清洗的步骤: 1.缺失值处理(通过describe与len ...