Jvm垃圾收集器和垃圾回收算法
概述:
目前内存的动态分配和内存的回收技术已经相当成熟,一切看起来都已经进入了“自动化”时代,为什么还要去了解GC和内存分配呢?原因很简单:当需要排查各种内存泄漏、内存溢出问题时,当垃圾收集器成为系统达到更高并发量的瓶颈时,我们就需要对这些“自动化”的技术实施必要的监控和调节。
之前的博客讲到了Java虚拟机运行时内存的各个部分,其中程序计数器、虚拟机栈、本地方法栈3个区域随线程而生,随线程而灭,栈中的栈帧随方法的进入和退出执行着入栈和出栈操作,因此方法结束或者线程结束时,内存就自然跟随着回收了。而Java堆和方法区组不同,我们在运行时才知道会创建哪些对象,这部分的内存和回收都是动态的,垃圾回收器所关注的也是这一部分内存。后文所讲的内存分配和回收也是仅指这一部分内存。
一、判断对象“死活”
1.引用计数法
很多教科书或者开发人员,对于回答“如何判断对象死活?”这个问题的答案大多是引用计数法。实现起来是这样的:给对象添加一个引用计数器,每当一个地方引用它时就+1,当引用失效时就-1,任何时刻计数器为0的对象就是不肯能再被引用的。
客观的说,引用计数法实现简单,判定效率也很高,但是至少主流的Java虚拟机都没有采用引用计数法来管理内存,最主要的原因是它很难解决对象之间互相循环引用的问题。
2.可达性分析算法
可达性算法(Reachability Anlysis)是目前Java、C#的主流实现中来判定对象是否存活的。主要思路是:通过一些类成为“GC Roots”的对象做为起点,从这些结点开始往下搜索,搜索所走过的路称为引用链,当一个对象到GC Roots没有任何引用链时,则证明这个对象是不可用的。
下图所示:
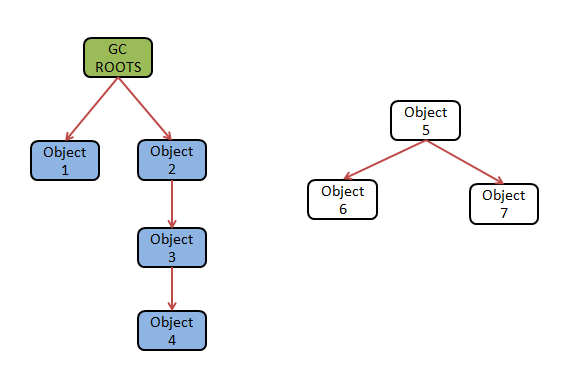
Object1-Object4均有引用链和GC Roots相连接,而Object5-Oject7没有引用链相连,所以他们被判定为可以回收的对象
在Java中,可以做为GC Roots结点的有一下四种
- 虚拟机栈(栈帧中的本地变量表)中的引用对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(即Native方法)
3.再谈引用
在JDK1.2之前,Java中的引用定义为:如果reference类型的数据存储的是数值代表的是另一块内存的起始地址,就称为这块内存代表着一个引用。在JDK1.2之后,Java对引用概念进行了扩充,分为下面四种:
- 强引用(Strong Reference):代码中普遍存在的,类似Object obj=new Object(),这类的引用,只要强引用还存在,GC就永远不会回收掉被引用的对象。
- 软引用(Soft Reference):用来描述一些还有用但并非必需的对象。对于软引用关联的对象,在系统将要发生内存溢出异常之前,将会把这些对象列进回收范围之中进行第二次回收,如果这次回收之后还没有足够的内存,才会抛出内存溢出异常。在JDK1.2之后,提供了SoftReference类来实现软引用。
- 弱引用(Weak Reference):也是用来描述非必需的对象,但强度比软引用要弱,被弱引用关联的对象只能生存到下一次垃圾回收器之前,当垃圾回收器工作时,一定会回收只被弱引用关联的对象。在JDK1.2之后,提供了WeakReference类来实现弱引用。
- 虚引用(Phantom Reference):也称为幽灵引用或者幻影引用,是最弱的一种引用关系。一个对象是否有虚引用的存在,完全不会对其生存时间构成影响,也无法通过虚引用来获得一个对象实例。为一个对象设置虚引用关联的唯一目的:在这个对象被垃圾回收器回收时收到一个系统通知。
4.生存还是死亡
即使在可达性分析算法中不可达的对象也不是“非死不可”的,这时候他们处于“缓刑”的阶段,真正要宣告一个对象死亡,至少要经过两次标记的过程。
- 如果对象在进行可达性分析后发现没有与GC Roots相连接的引用链,那么它将被第一次标记并且执行一次筛选。筛选的条件是:这个对象是否有必要执行finalize()方法(若对象没有覆盖finalize()方法,或者finalize()方法已经被虚拟机调用过(虚拟机只能调用一次),则视为“没有必要执行”)。
- 若被判定为有必要执行finalize()方法,那么该对象会被放置在一个叫做F-Queue的队列中,并在稍后有一个虚拟机自动建立的、低优先级的Finalizer线程去执行它(即虚拟机触发finalize()方法,但不承诺会保证等待它运行结束,因为如果一个对象的finalize()方法执行缓慢,或者发生了死循环,将很可能会导致F-Queue队列中的其他对象永远处于等待状态,甚至整个内存回收系统崩溃)。finalize()方法是对象逃脱死亡命运的最后一次机会,稍后GC将对F-Queue中的对象进行第二次标记。如果对象要在这里拯救自己,就要重新与引用链上的任意一个对象建立关联即可。譬如,把自己复制给某个类变量或者对象的成员变量上,那么在第二次标记它时将被移除F-Queue队列。如果对象还没有逃脱,则被真正的回收了。
下面代码显示一次对象的自我拯救:
//代码演示了两点
//1.对象可以实现自救
//2.这种自救只能一次,因为finalize方法只会被执行一次 public class jvmtest1 {
public static jvmtest1 obj = null; public void isAlive() {
System.out.println("I am alive");
} @Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize method executed!");
obj = this;
} public static void main(String[] args) throws Exception {
obj = new jvmtest1(); obj = null;
System.gc();
// 因为finalize方法优先级很低,所以暂停0.5s执行
Thread.sleep(500);
if (obj != null) {
obj.isAlive();
} else {
System.out.println("I am dead");
} // 与上面的代码完全相同,但是自救失败了
obj = null;
System.gc();
// 因为finalize方法优先级很低,所以暂停0.5s执行
Thread.sleep(500);
if (obj != null) {
obj.isAlive();
} else {
System.out.println("I am dead");
}
}
}
程序输出为:

可以看出obj的finalize()方法,确实被GC触发过,而且成功自救了一次。要注意的是下半部分的代码和上半部分的代码相同,但是自救失败,这是因为一个对象的finalize()方法只能被系统自动调用一次,如果对象面临第二次回收,其finalize()方法不会被调用,因此第二次自救失败。
5.回收方法区
方法区的垃圾收集“性价比”很低,在堆中,尤其是新生代中,常规应用进行一次垃圾收集一般可以回收70%-95%的空间,而方法区(HatSport虚拟机中的永久代)的回收效率远低于 此。
永久代中的垃圾收集主要为两种:废弃常量和无用的类
- 回收废弃常量与回收Java堆中的对象非常类似。以常量池中字面量的回收为例:假如“abc”已经进入了常量池,但是没有任何String对象引用这个“abc”常量,也没有其他地方引用这个字面量,如果这时发生内存回收,而且有必要的话,这个“abc”常量就会被清出常量池。常量池中的其他类(接口)、方法、字段的符号引用也与此类似
- 判断一个类是否是无用类条件要复杂很多。类需要同时满足下面三个条件才是无用类:
(1)该类的所有实例都已经被回收,也就是堆中不存在该类的任何实例
(2)加载该类的ClassLoader已经被回收
(3)该类对应的java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
对于满足上面三个条件的类,也是可以回收,不是必然回收。在大量使用反射、动态代理、CGLib等ByteCode框架、动态生成JSP以及OSGi这类频繁定义ClassLoader的场景都需要虚拟机具备类卸载的功能,以保证永久代不会溢出。
二、垃圾回收算法
1.标记-清除算法
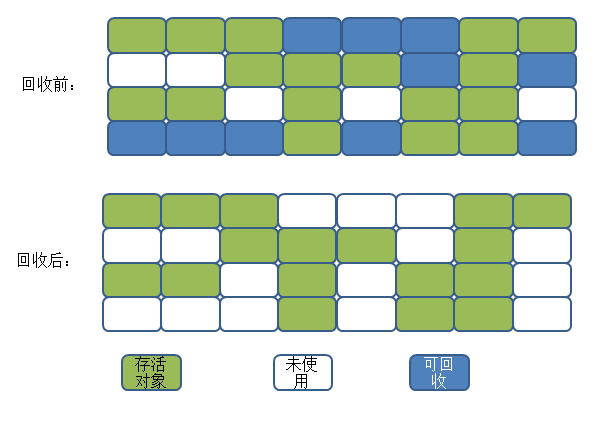
标记-清除算法(Mark-Sweep)是最基础的收集算法。首先标记出所需要回收的对象,在标记完成后统一回收所有被标记的对象。
不足之处主要有两点:
- 效率问题,标记和清除两个过程的效率都不高。
- 空间问题,清除之后会产生大量的不连续的内存碎片,内存碎片太多可能会导致要分配较大对象时,无法找到足够的连续内存而不得不提前触发下一次垃圾收集动作。
过程如下:
2.复制算法
为了解决效率问题,复制算法(Copying)出现了,他将内存分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就把存活的对象复制到另一块上,然后把这一块空间全部清理掉。这样是的每次是对整个半区就行内存回收,内存分配时也不用考虑内存碎片的复杂情况,只需要移动指针,按顺序分配内存即可。
只是这种方法的代价是将内存分为之前的一半,未免太高了。
过程如下:
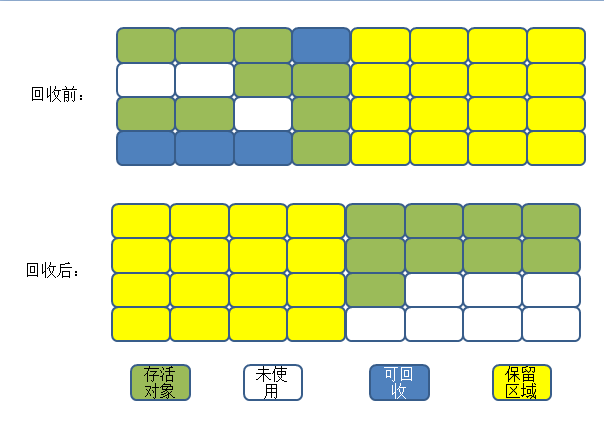
现在的商业虚拟机都是采用这种方法来回收新生代,IBM公司的专门研究表明,新生代中98%的对象是“朝生夕死”的,所以并不需要1:1来划分内存空间。另一种方法是:将内存块分为Eden空间(80%)和两块Survivor空间(10%),每次使用Eden空间和一块Survivor空间,回收时将存活的对象复制到另一块Survivor空间上,这样每次只有10%的空间被“浪费”。当Survivor空间不够用时,需要依赖其他内存(老年代)来进行分配担保(同过分配担保机制进入老年代)。
3.标记-整理算法
当复制收集算法在对象存活率较高时就要进行较多的复制动作,效率会变慢。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以老年代一般不能选用这种方法。标记-整理算法(Mark-Compact)就被提出了。
标记过程和“标记-清除”算法一样,但是后续步骤不是直接对可回收部分进行清理,而是把存活对象都向一端移动,然后直接清理掉端以外的内存。
过程如下:

4.分代收集算法
当前商业虚拟机都采用分代收集算法(Generational Collection),一般是把堆分为新生代和老年代,根据各个年代的不同特点采用最适合的算法。新生代一般采用复制算法,只需要付出少量存活对象的复制成本即可;老年代因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或者“标记-整理”算法来进行回收。
Jvm垃圾收集器和垃圾回收算法的更多相关文章
- jvm之垃圾收集一之垃圾回收算法
最近又重新在读深入理解java虚拟机一书,吸取第一次读完到现在已经忘记的差不都的教训,这次的学习之旅想通过博客的形式记录下自己的所学所感,以备后续继续学习备忘所用!这次先记录下垃圾收集相关知识点: 垃 ...
- JVM学习总结二——垃圾回收算法
昨天总结了JVM内存分区相关的知识,这次我们将来了解下JVM的另一个核心知识点——垃圾回收算法.这一部分其实并不太难,如果对操作系统的内存处理算法有所了解,那么这部分算法其实只看名字就能明白,两者在原 ...
- JVM内存模型,垃圾回收算法
JVM内存模型总体架构图 程序计数器多线程时,当线程数超过CPU数量或CPU内核数量,线程之间就要根据时间片轮询抢夺CPU时间资源.因此每个线程有要有一个独立的程序计数器,记录下一条要运行的指令.线程 ...
- 轻松学JVM(四)——垃圾回收算法
我们都知道java语言与C语言最大的区别就是内存自动回收,那么JVM是怎么控制内存回收的,这篇文章将介绍JVM垃圾回收的几种算法,从而了解内存回收的基本原理. stop the world 在介绍垃圾 ...
- 深入理解JVM(四)——垃圾回收算法
我们都知道java语言与C语言最大的区别就是内存自动回收,那么JVM是怎么控制内存回收的,这篇文章将介绍JVM垃圾回收的几种算法,从而了解内存回收的基本原理. stop the world 在介绍垃圾 ...
- JVM内存模型及垃圾回收算法
国内私募机构九鼎控股打造APP,来就送 20元现金领取地址:http://jdb.jiudingcapital.com/phone.html内部邀请码:C8E245J (不写邀请码,没有现金送)国内私 ...
- JVM学习(三):垃圾回收算法
局部性原理和分代回收思想 大学学习操作系统或者计算机组成原理的时候都提到一个重要概念,叫局部性原理. 局部性原理是指CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小 ...
- 直通BAT必考题系列:JVM的4种垃圾回收算法、垃圾回收机制与总结
垃圾回收算法 1.标记清除 标记-清除算法将垃圾回收分为两个阶段:标记阶段和清除阶段. 在标记阶段首先通过根节点(GC Roots),标记所有从根节点开始的对象,未被标记的对象就是未被引用的垃圾对象. ...
- 小师妹学JVM之:GC的垃圾回收算法
目录 简介 对象的生命周期 垃圾回收算法 Mark and sweep Concurrent mark sweep (CMS) Serial garbage collection Parallel g ...
随机推荐
- idea live template高级知识, 进阶(给方法,类,js方法添加注释)
为了解决用一个命令(宏)给方法,类,js方法添加注释,经过几天的研究.终于得到结果了. 实现的效果如下: 给Java中的method添加方法: /** * * @Method : addMenu * ...
- Spring mvc 中使用 kaptcha 验证码
生成验证码的方式有很多,个人认为较为灵活方便的是Kaptcha ,他是基于SimpleCaptcha的开源项目.使用Kaptcha 生成验证码十分简单并且参数可以进行自定义.只需添加jar包配置下就可 ...
- python 标准库 -- re
re 正则表达式 语法 import re m = re.search('[0-9]','abc4def67') # 匹配字符及匹配范围 print m.group(0) # 返回匹配结果 re.se ...
- An abandoned sentiment from past
An abandoned sentiment from past time limit per test 1 second memory limit per test 256 megabytes in ...
- js中的事件,内置对象,正则表达式
[JS中的事件分类] 1.鼠标事件: click/dbclick/mouseover/mouseout/mousemove/mousedown/mouseup 2.键盘事件: keydown: 键盘按 ...
- 各开放平台API接口通用SDK序列文章 前言
最近两年一直在做API接口相关的工作,在平时工作中以及网上看到很多刚接触API接口调用的新人一开始会感到很不适应,要看的文档一大堆,自己要调用的接口找不着,或都找着了不知道怎么去调用,记得包括自己刚开 ...
- 如何在前端模版引擎开发中避免使用eval函数
前段时间,想着自己写一个简单的模版引擎,便于自己平时开发demo时使用.于是根据自己对模版引擎的理解,定义自己的模版格式,然后,根据自己定义的格式,编写处理函数,将模版标签中的字符串,解析成可执行的字 ...
- 使用awk进行日志信息的分组统计
起因 这是今天我线上出了一个bug,需要查看日志并统计一个我需要的信息出现的频率,可以叫做分组统计. 日志文件部分内容 00:09:07.655 [showcase_backend][topsdk] ...
- js对象中动态读取属性值 动态属性值 js正则表达式全局替换
$(document).ready(function(){ var exceptionMsg = '${exception.message }'; var exceptionstr = ''; //j ...
- 常用html标签的只读写法
<a href="baidu.com" onclick="event.returnValue=false;">百度</a> a链接的只读 ...