node.js搭建代理服务器请求数据
1、引入node.js中的模块
var http = require("http");
var url = require("url");
var qs = require("querystring");
2、创建服务器
//用node中的http创建服务器 并传入两个形参
http.createServer(function(req , res) {
//设置请求头 允许所有域名访问 解决跨域
res.setHeader("Access-Control-Allow-Origin" , "*"); //获取地址中的参数
var query = url.parse(req.url).query; //用qs模块的方法 把地址中的参数转变成对象 方便获取
var queryObj = qs.parse(query);
//获取前端传来的myUrl=后面的内容 GET方式传入的数据
var myUrl = queryObj.myUrl;
//创建变量保存请求到的数据
var data = ""; //开始请求数据 http.get()方法
http.get(myUrl,function (request) {
//监听myUrl地址的请求过程
//设置编码格式
request.setEncoding("utf8"); //数据传输过程中会不断触发data信号
request.on("data", function (response) {
data += response;
}); //当数据传输结束触发end
request.on("end" , function () {
//把data数据返回前端
res.end(data);
});
}).on("error" , function () {
console.log("请求myUrl地址出错!");
});
}).listen(8989,function(err){
if(!err){
console.log("服务器启动成功,正在监听8989...");
}
});
3、启动服务器
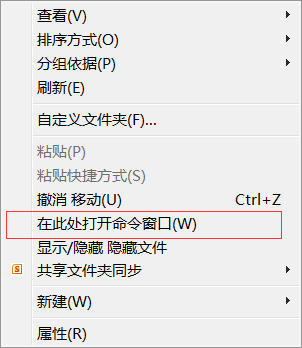
打开配置的nodejs所在文件夹,Shift+右键空白处 打开cmd终端
输入node 服务器名.js开启服务器
node.js搭建代理服务器请求数据的更多相关文章
- 使用 Node.js 搭建微服务网关
目录 Node.js 是什么 安装 node.js Node.js 入门 Node.js 应用场景 npm 镜像 使用 Node.js 搭建微服务网关 什么是微服务架构 使用 Node.js 实现反向 ...
- 使用Node.js搭建静态资源服务器
对于Node.js新手,搭建一个静态资源服务器是个不错的锻炼,从最简单的返回文件或错误开始,渐进增强,还可以逐步加深对http的理解.那就开始吧,让我们的双手沾满网络请求! Note: 当然在项目中如 ...
- Node.js GET/POST请求
在很多场景中,我们的服务器都需要跟用户的浏览器打交道,如表单提交. 表单提交到服务器一般都使用GET/POST请求. 我将为大家介绍 Node.js GET/POST请求. 获取GET请求内容 由于G ...
- 使用 Node.js 搭建 Web 服务器
使用Node.js搭建Web服务器是学习Node.js比较全面的入门教程,因为实现Web服务器需要用到几个比较重要的模块:http模块.文件系统.url解析模块.路径解析模块.以及301重定向技术等, ...
- body-parser Node.js(Express) HTTP请求体解析中间件
body-parser Node.js(Express) HTTP请求体解析中间件 2016年06月08日 781 声明 在HTTP请求中,POST.PUT和PATCH三种请求方法中包 ...
- node.js 发送http 请求
自己研究了一下 node.js 的 http模块 下面为想服务器发送请求的代码 ,通过学习了解http 请求的过程 ,node.js 对http请求的原始封装比较低,以前php 可以用$_GET , ...
- js跨域请求数据的3种常用的方法
由于js同源策略的影响,当在某一域名下请求其他域名,或者同一域名,不同端口下的url时,就会变成不被允许的跨域请求.那这个时候通常怎么解决呢,对此菜鸟光头我稍作了整理:1.JavaScript 在 ...
- Node.js处理I/O数据之Buffer模块缓冲数据
一.前传 在之前做web时也经常用到js对象转json和json转js对象.既然是Node.js处理I/O数据,也把这个记下来. Json转Js对象:JSON.parse(jsonstr); //可以 ...
- 使用Node.js搭建数据爬虫crawler
0. 通用爬虫框架包括: (1) 将爬取url加入队列,并获取指定url的前端资源(crawler爬虫框架主要使用Crawler类进行抓取网页) (2)解析前端资源,获取指定所需字段的值,即获取有价值 ...
随机推荐
- base 镜像 - 每天5分钟玩转容器技术(10)
上一节我们介绍了最小的 Docker 镜像,本节讨论 base 镜像. base 镜像有两层含义: 不依赖其他镜像,从 scratch 构建. 其他镜像可以之为基础进行扩展. 所以,能称作 base ...
- hdu1151有向图的最小顶点覆盖
有向图的最小路径覆盖=V-二分图最大匹配. Consider a town where all the streets are one-way and each street leads from o ...
- phtread_mutex 组合
phtread_mutex通过mutexattr设定其类型,并保存在成员__kind中.pthread_mutex的锁操作函数根据__kind进行方法的分派(dispatch).__kind由5个字段 ...
- 【css笔记】css中的盒模型和三种定位机制(固定定位,绝对定位,浮动)
html页面上的元素都可以看成是框组成的,框通过三种定位机制排列在一起就过程了我们看到的页面.而框就是盒模型. 盒模型 1.页面上的每个元素可以看成一个矩形框,每个框由元素的内容,内边距,边框和外边距 ...
- 设计模式--MVC(C++版)
MVC 模式代表 Model-View-Controller(模型-视图-控制器) 模式.这种模式用于应用程序的分层开发. Model(模型)-是应用程序中用于处理应用程序数据逻辑的部分.通常模型对象 ...
- HTML5工具做屏幕自适应的两种方法
近一两年,HTML5在中国很火,也出了不少HTML5工具和模板.别的先不说,对于不同的H5工具,解决屏幕自适应问题的区别是什么? 简单来说,感应式设计是当用不同设备访问时,能够根据设备的宽度和高度对设 ...
- Python变量运算字符串等
一,作用域 操作 name = 'liuyueming' if 1==1:... print name... liuyueming 两次回车执行 修改代码 >>> if 1==1:. ...
- CentOS系统搭建gitolite服务
1.安装相关支持软件 a.$yum install perl-Time-HiRes openssh-server perl -y b.$yum -y install git 2.服务端操作:创建git ...
- 掌握Docker命令
1.管理镜像命令 获取镜像 docker push ubuntu:14:04 查看镜像列表 docker images 重命名image docker tag IMAGE-NAME NEW-IMAGE ...
- Appium 1.6.4 环境搭建流程(Java, Android+IOS, Windows+Mac)
Appium1.6.4已经出来一段时间了,快速给大家串一下怎么搭建,贴了下载链接 1 基础环境: Windows + Mac: Java JDK 1.8+ (需配置环境变量),Appium1.6.4的 ...