Python开发简单爬虫(一)
一 、简单爬虫架构:
爬虫调度端:启动爬虫,停止爬虫,监视爬虫运行情况
URL管理器:对将要爬取的和已经爬取过的URL进行管理;可取出带爬取的URL,将其传送给“网页下载器”
网页下载器:将URL指定的网页下载,存储成一个字符串,在传送给“网页解析器”
网页解析器:解析网页可解析出 ①有价值的数据 ②另一方面,每个网页都包含有指向其他网页的URL,解析出来后可补充进“URL管理器”,不断循环。
二、简单爬虫架构的动态运行流程
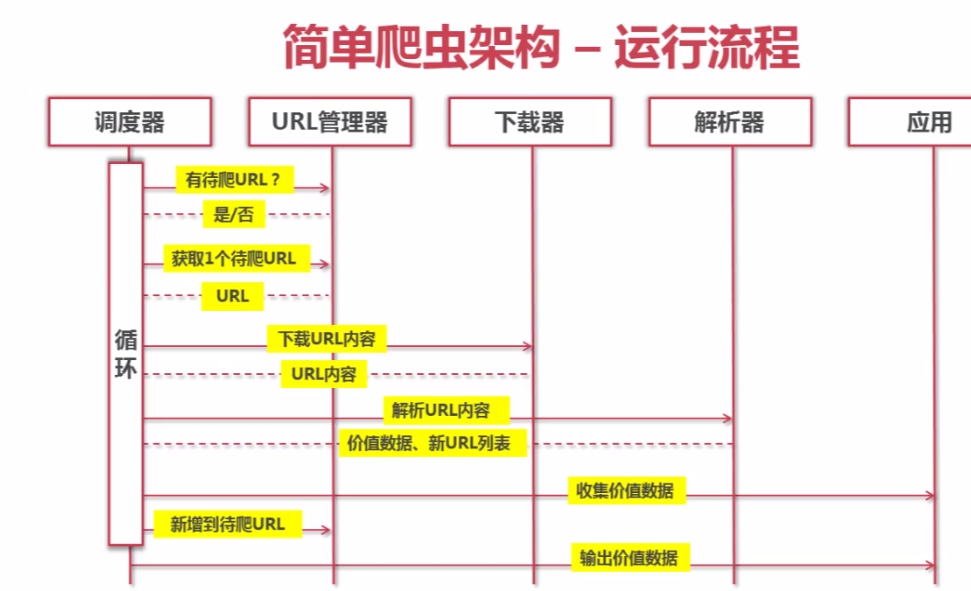
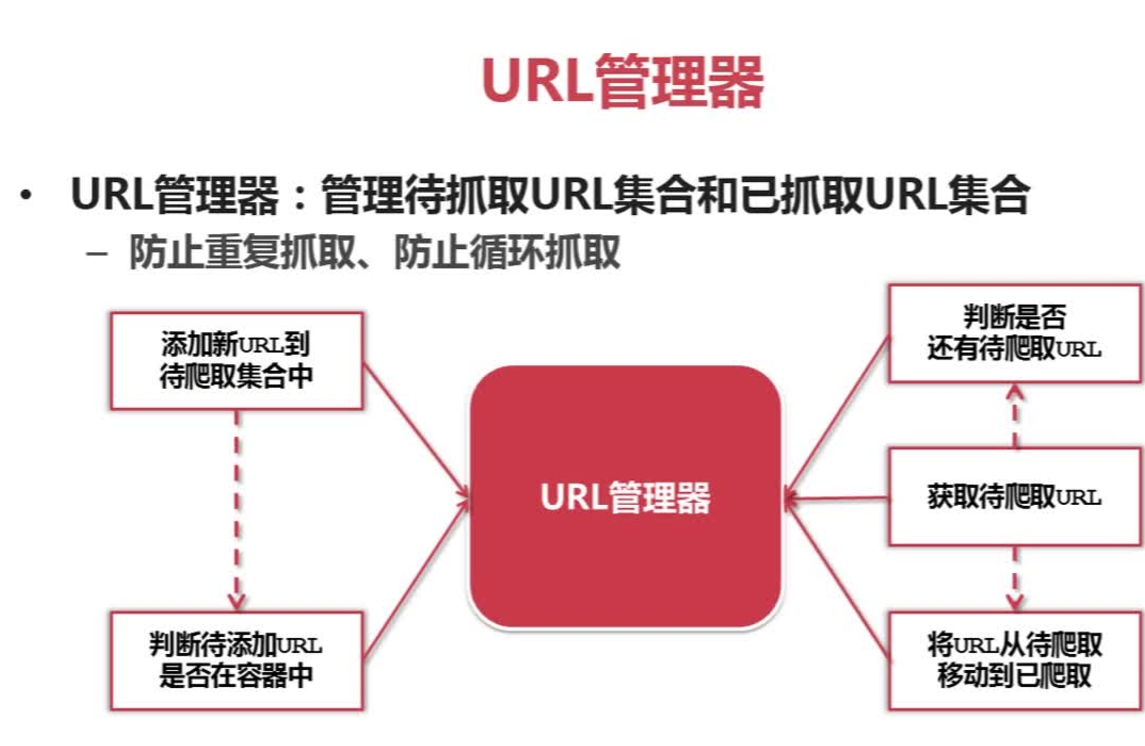
三、爬虫URL管理
URL管理器:管理待抓取URL集合和已抓取URL集合 防止重复抓取。
url: 添加新url到爬取集合中, 判断待添加url是否在容器中, 判断是否还有待爬取的url, 获取待爬取url, 将url从待爬移动到已爬
四、爬虫URL管理器的实现方式
URL管理器的三种实现方式:内存、关系数据库、缓存数据库
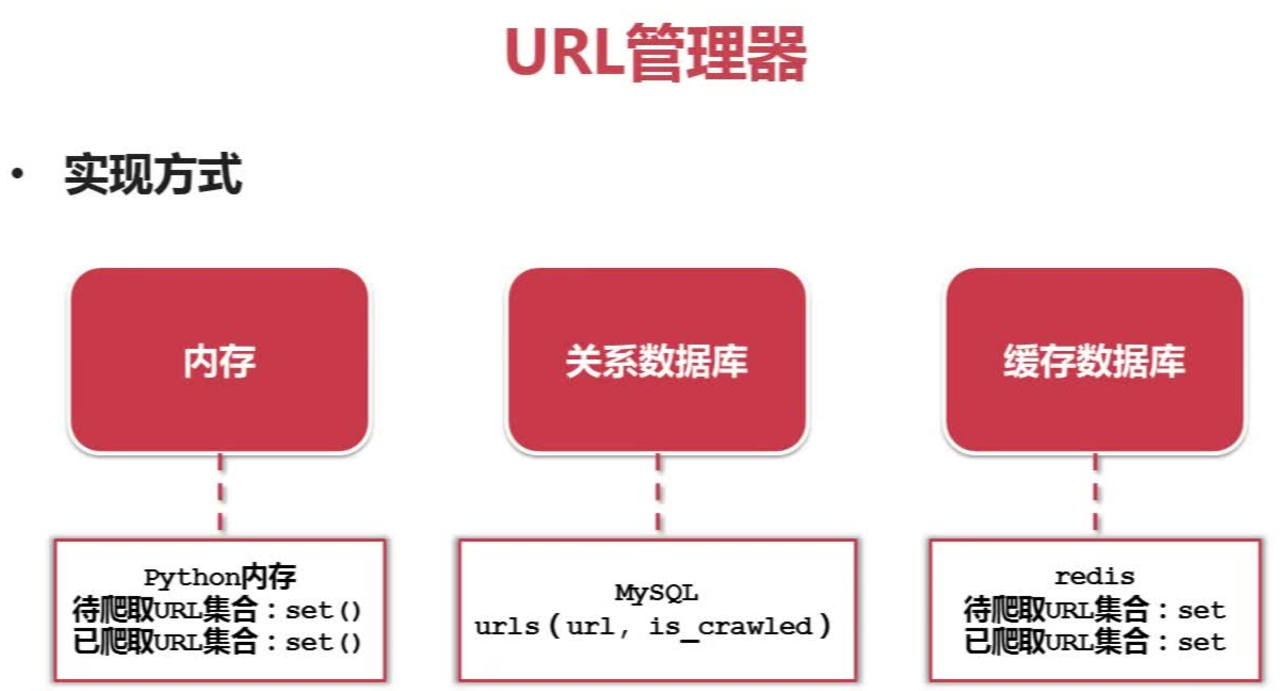
存放在内存中是利用set()集合,可以去除重复元素,利用MySQL里的is_crawled参数是用来标记已爬取还是未爬取,redis数据库同样利用set集合。
五、爬虫网页下载器
Python网页下载器有:
1)urllib2 (Python官方基础模块)python 3.x中urllib库和urilib2库合并为urllib库。
2)requests (第三方包,更强大)
爬虫urlib2下载器网页的三种方法:
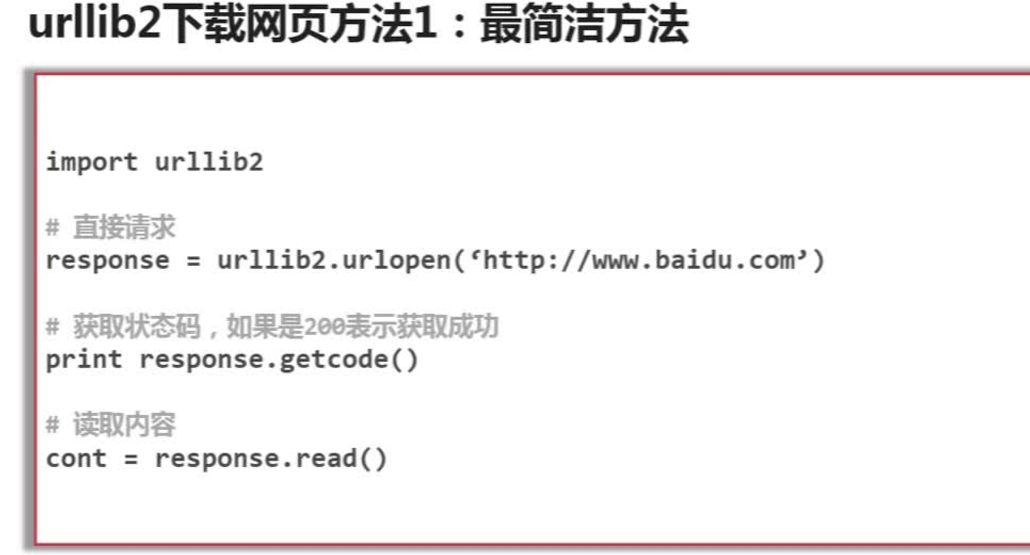
方法一:直接将url传送给urllib2模块的urlopen()方法
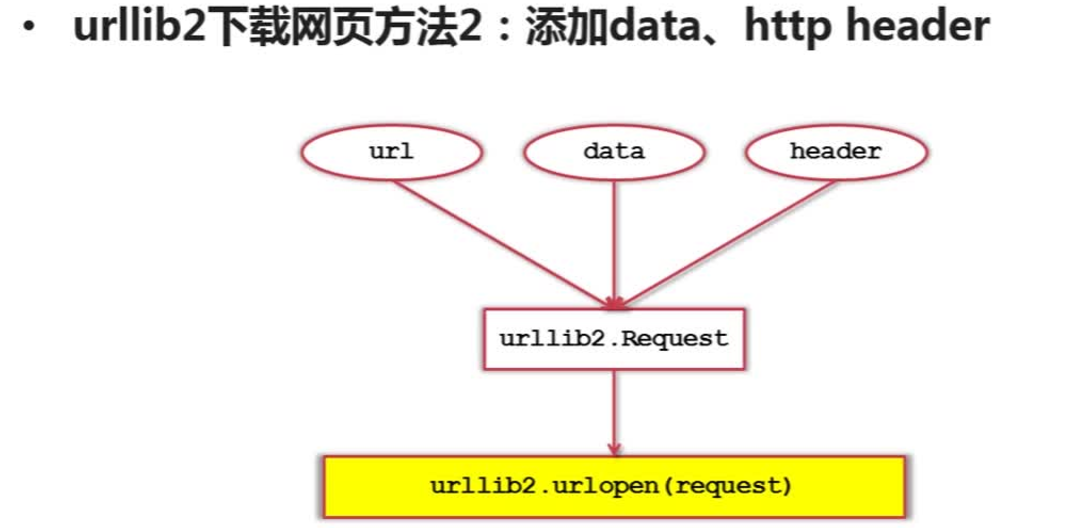
方法二:共享处理,添加data、http header
可以将url,data,header三个参数传送给urllib2的Request类,生成Resquest对象,再将Resquest对象作为参数传递给urlopen()方法来发送网页请求
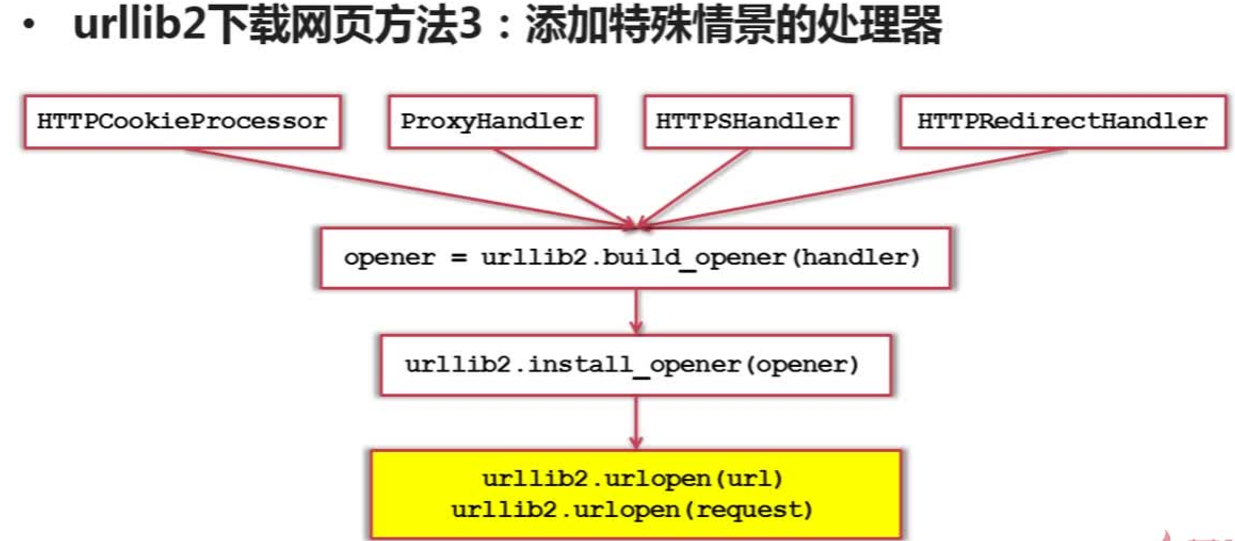
方法三:添加特殊情景的处理器
有些网页需要用户登录才能访问,此时需要添加cookie的处理,则使用HTTPCookieProcessor进行处理
有些网页需要代理才能访问,则使用ProxyHandler进行处理
有些网页使用的是HTTPS协议加密访问的,则使用HTTPSHandler进行处理
还有些网页中的url存在相互的自动的跳转关系,则使用HTTPRedirectHandler进行处理
可将这些handler传送给build_opener()方法生成一个opener对象,然后给urlib2安装该opener,再利用urlopen()方法发送网页请求,实现网页的下载
例:增强cookie的处理

六、网页下载器urllib2三种方法实例代码
方法一:
import urllib2 # -*- coding: utf-8 -*- #第一种方法 url = 'http://www.baidu.com' response1 = urllib2.urlopen(url) print response1.getcode() #打印一下状态码,确定请求是否成功 print len(response1.read()) #打印返回的网页内容的长度
方法二:
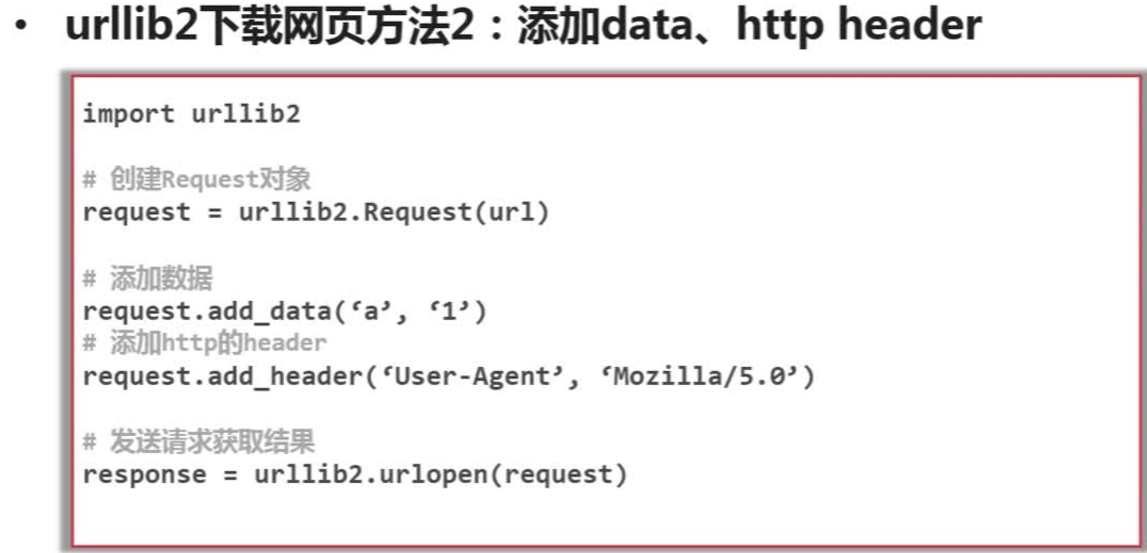
# -*- coding: utf-8 -*-
import urllib2
url = 'http://www.baidu.com'
request = urllib2.Request(url)
request.add_header("user-agent","Mozilla/5.0") #为request对象添加了http头信息,并将爬虫伪装成了Mozilla浏览器
response2 = urllib2.urlopen(request)
print response2.getcode()
print len(response2.read())
方法三:
先创建一个cookie容器为cj,
然后创建一个opener,是以容器作为参数通过urllib2.HTTPCookieProcessor()方法创建一个handler,再传给build_opener()方法实现,
为urllib2安装opener,此时urllib2就具有了cookie处理的增强能力,
最后然后就使用urlopen()方法访问正常的url
最后即可打印出cookie的内容和网页的内容
import urllib2 import cookielib url = 'http://www.baidu.com' cj = cookielib.CookieJar() opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) urllib2.install_opener(opener) response3 = urllib2.urlopen(url) print response3.getcode() print cj print response3.read()
七、爬虫网页解析器
网页解析器:从网页中提取有价值数据的工具
python四种网页解析方式:
模糊匹配:
1.正则表达式(最直观的一种方式,将网页或文档看成是一个字符串,以模糊匹配的方式提取出有价值的数据,但如果文档比较复杂时此方式非常麻烦)
结构化解析:(即将整个网页加载成一个DOM树,以树的形式来进行上下级的遍历和访问)
2.html.parser;(Python的模块)
3.BeautifulSoup,(第三方插件,同时可以使用html.parser和lxml作为解析器)
4.lxml;(第三方插件,可解析html网页或xml网页)
八、使用BeautifulSoup4
BeautifulSoup是Python的第三方库,用于从HTML或XML中提取数据
安装BeautifulSoup4:
1)打开cmd命令窗口
2)进入Python的安装目录下的Scripts
cd C:\Python27\Scripts
3) 输入dir,显示pip.exe已安装
4)输入pip install beautifulsoup4,即可安装beautifulsoup4
BeautifulSoup的语法:
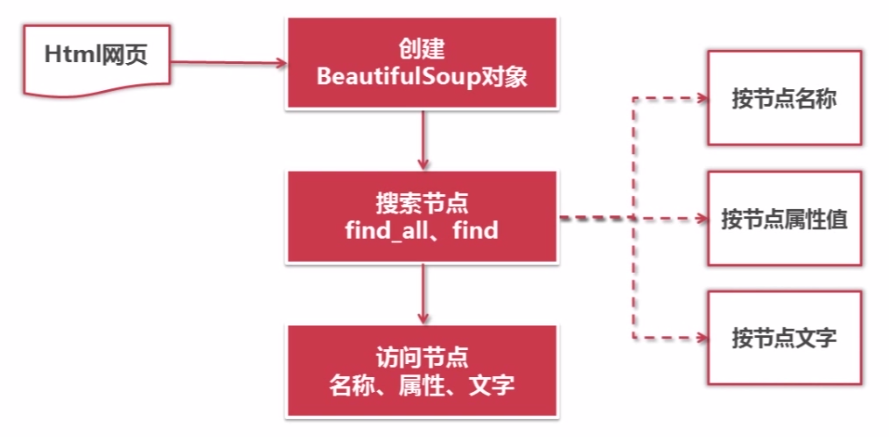
1)根据已下载好的html网页创建一个beautifulsoup对象,创建该对象的同时就已将整个文档加载成一个DOM树,
2)然后根据此DOM就可对节点进行搜索,搜索节点有两个方法:
find_all方法和find方法,两个方法的参数相同,find_all方法会搜索出所有满足要求的节点,find方法只会搜索出第一个满足要求的节点,
在搜索节点时,可按照节点的名称,属性或文字进行搜索。
3)得到了节点之后,就可以访问节点的名称、属性和内容文字。
例:可使用三种方式对下面a链接进行搜索和访问

代码如下:
1.创建BeautifulSoup对象并同时加载好了DOM树
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
#根据HTML网页字符串创建BeautifulSoup对象
soup = BeautifulSoup(
html_doc, #HTML文档字符串,指利用网页下载器下载好的html文件或者是存在本地的html文件,是要提前赋值的
'html.parser', #HTML解析器
from_encoding = 'utf-8' #HTML文档的编码
)
2.搜索节点(find_all,find)
#方法:find_all(name,attrs,string)
#查找所有标签为a的节点
soup.find_all('a')
#查找所有标签为a,链接符合/view/123.htm形式的节点
soup.find_all('a',href='/view/123.htm')
soup.find_all('a',href=re.compile(r'/view/\d+\.htm')) #可以使用正则表达式进行匹配
#查找所有标签为div,class为abc,文字为Python的节点
soup.find_all('div',class_='abc',string='Python') #因为class是Python的关键字,为了避免冲突使用class_
3.访问节点的信息
#例:得到节点<a href='1.html'>Python</a> #获取查找到的节点的标签名称 node.name #获取查找到的a节点的href属性 node['href'] #获取查找到的a节点的链接文字 node.get_text()
BeautifulSoup实例演示:
# -*- coding: utf-8 -*-
import os
import re
from bs4 import BeautifulSoup
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
print '获取所有的a链接:'
soup = BeautifulSoup(html_doc,'html.parser',from_encoding='utf-8')
links = soup.find_all('a')
for link in links:
print link.name,link['href'],link.get_text()
print '获取lacie的链接:'
link_node1 = soup.find('a',href='http://example.com/lacie')
print link_node1.name,link_node1['href'],link_node1.get_text()
print '使用正则表达式匹配:'
link_node2 = soup.find('a',href=re.compile(r"ill"))
print link_node2.name,link_node2['href'],link_node2.get_text()
print '获取指定p段落的文字:'
p_node = soup.find('p',class_='title')
print p_node.name,p_node.get_text()
输出结果:

Python开发简单爬虫(一)的更多相关文章
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
- Python开发简单爬虫
简单爬虫框架: 爬虫调度器 -> URL管理器 -> 网页下载器(urllib2) -> 网页解析器(BeautifulSoup) -> 价值数据 Demo1: # codin ...
- Python开发简单爬虫(二)---爬取百度百科页面数据
一.开发爬虫的步骤 1.确定目标抓取策略: 打开目标页面,通过右键审查元素确定网页的url格式.数据格式.和网页编码形式. ①先看url的格式, F12观察一下链接的形式;② 再看目标文本信息的标签格 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python 开发轻量级爬虫03
Python 开发轻量级爬虫 (imooc总结03--简单的爬虫架构) 现在来看一下一个简单的爬虫架构. 要实现一个简单的爬虫,有哪些方面需要考虑呢? 首先需要一个爬虫调度端,来启动爬虫.停止爬虫.监 ...
- Python 开发轻量级爬虫01
Python 开发轻量级爬虫 (imooc总结01--课程目标) 课程目标:掌握开发轻量级爬虫 为什么说是轻量级的呢?因为一个复杂的爬虫需要考虑的问题场景非常多,比如有些网页需要用户登录了以后才能够访 ...
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
随机推荐
- php高性能开发阅读笔记
1.http请求与响应的简单流程 上图简单的描述了一个http请求与响应的过程,首先是用户请求过程,这是该生命周期的第一部分,用户发起请求,经过路由器与ips网关和dns服务器(域名服务器),通过we ...
- NodeJs的包漏洞扫描与漏洞测试攻击
一个典型的Node应用可能会有几百个,甚至上千个包依赖(大部分的依赖是间接的,即下载一个包,这个包会依赖其他的好多包),所以最终的结果是,应用程序就会像是这个样子的:
- IIS无法启动,应用程序池自动关闭,应用程序池XXXX将被自动禁用 解决方案之一
最近,新任职的公司有一台测试服务(Windows Server 2008 R2 + IIS6.1)器因突然停电,造成了意外“损伤”.来电后再次开机,发现IIS里大部分的网站均打不开.均为如下(图01) ...
- IPad分屏,当电脑第二显示屏
最在在网上看到使用IPad可以做为电脑的第二个显示屏,对于我这样一个程序猿来说,这真是我的福音呀!因此在网上搜了许多关于Ipad投屏的信息,下面简单说明一下,包括怎么使用! 1.根据在网上搜索的结果, ...
- 用NIO实现http协议
先来看一下本篇博文的目录: 一:简介Nio 二:Nio的好处 三:关于http协议 四:代码实现 五:总结 一:简介Nio 我们都知道io流,那么NIO是什么呢?本篇博文将会带你一探NIO,NIO的全 ...
- python List和String 转换注意
不能用str(list),t=['\x87\xe9\xa5\xb0\xef\xbc']In [28]: str(t)Out[28]: "['\\x87\\xe9\\xa5\\xb0\\xef ...
- servlet与jsp
Servlet生命周期 一.初始化阶段 当WEB客户第一次请求访问某个Servlet的时候,WEB容器将创建这个Servlet的实例.调用init()方法进行Servlet的初始化 一.响应客户请 ...
- javacpp-opencv图像处理之1:实时视频添加文字水印并截取视频图像保存成图片,实现文字水印的字体、位置、大小、粗度、翻转、平滑等操作
欢迎大家积极开心的加入讨论群 群号:371249677 (点击这里进群) javaCV图像处理系列: javaCV图像处理之1:实时视频添加文字水印并截取视频图像保存成图片,实现文字水印的字体.位置. ...
- (文件)图片上传,Spring或SpringMVC框架
spring或springMVC框架图片(文件)上传 页面部分,用一个简单的form表单提交文件,将图片或文件提交到服务端.一个输入框,用于输入图片的最终名称,一个file文件选择,用于选择图片. 页 ...
- Windows系统如何使用sqlmap
使用方法:需要安装python,不能安装最新版本的python3.2.2只能安装2.6-3.0这些版本,包括2.6,3.0 这里,我提供一个Python的安装包.点击这里下载→ Python2.7 然 ...