JDownload: 一款可以从网络上下载文件的小程序第四篇(整体架构描述)
一 前言
时间过得真快,距离本系列博客第一篇的发布已经过去9个月了,本文是该系列的第四篇博客,将对JDownload做一个整体的描述与介绍。恩,先让笔者把记忆拉回到2017年年初,那会笔者在看Unix环境高级编程这本书,其中有些章节是socket相关的,这引起了我很大的兴趣。然后有一天,看着屏幕上正在下载文件的迅雷,突然灵光一闪,要不自己也写个下载工具吧,正所谓学以致用嘛,然后网上简单搜索了一下,发现是可行的,于是乎就开始着手实现之。该系列的第一篇博客实现了一个基本的http站点迷你下载工具,第二篇加入了断点续传功能,第三篇加入了多线程的功能。本篇将从总体上对JDownload做一个描述,以图形的方式来展示一下JDownload的工作流程,因此笔者建议读者先阅读一下该系列的另外三篇博客:
- JWebFileTrans: 一款可以从网络上下载文件的小程序(一) 链接请点击我
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(二) 链接请点击我
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(三),多线程断点下载 链接请点击我
GitHub代码链接请点击我
PS: 本篇博客是博客园用户“cs小学生”的原创作品,转载请注明原作者和原文链接,谢谢。
二 JDownload执行流程图
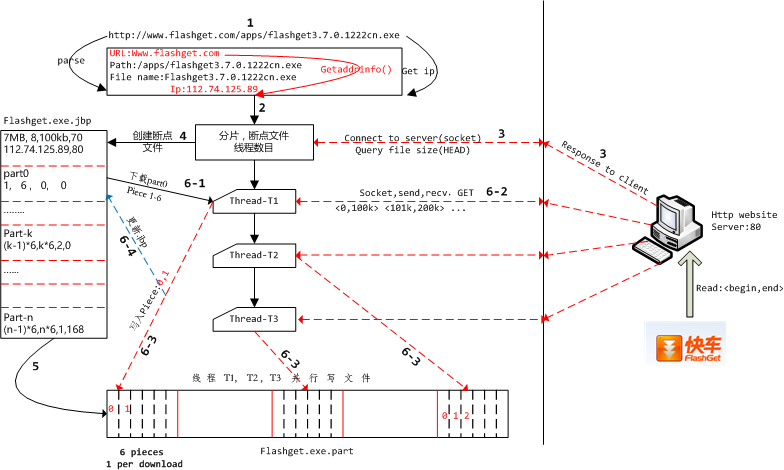
如上图所示,描述了JDownload从快车官网上下载“快车”软件的整个执行流程图,图中的数字标志了执行的先后顺序。诸如6-1,6-2之类的表示这几个步骤的关系比较紧密,6表示都属于同一个大操作,后面的1,2,3,4,表示在这个大操作的内部的执行顺序。在图中每一个线程都会经历6-1,2,3,4的这样一个执行流过程,但是为了防止图变得太过稠密而影响美观,只有线程1完整标志出了6-1,2,3,4这几个标识符,其他几个线程也会经历这几个过程,但是图中省略了这几个标识符。当然对于步骤6,图中的线程是并行执行的。
接下来让我们从标识符1开始,来走一遍整个下载过程:
1. 解析http链接
首先是用户输入下载链接“http://www.flashget.com/apps/flashget3.7.0.1222cn.exe”给JDownload,然后如图最上端的矩形框所示,JDownload会从这个链接里面解析出3个部分,分别是
- URL: www.flashget.com,通过该URL可以得到对应的ip地址
- 服务端资源路径:/apps/flashget3.7.0.1222cn.exe
- 文件名:flashget3.7.0.1222cn.exe
相信学过计算机网络这门课程的童鞋应该记得:ip地址和端口号唯一标志了一台计算机上面的一个服务,所谓服务比如80端口对应的是http服务,端口号21对应的是ftp服务等等。想象一下,我们要下载的东西必定存储在网络中的某台计算机上,但是这台计算机上很可能存在着很多服务,比如http服务、ftp服务、邮箱服务,由于这些服务是用约定好的端口号来标志的,而我们已经知道下载的东西在http站点上,所以我们向端口号80请求下载文件即可。那么端口号80我们已经知道了,服务器的ip地址怎么找呢?其实linux库函数getaddrinfo()就具备通过域名来查找ip地址的功能,具体使用请参考APUE.
前面我们说过,通过GET可以向http站点请求下载文件,我们每一次向服务器请求文件的一部分,然后不断地请求,最后就可以把整个文件下载下来。所以我们需要知道文件的大小是多少,每一次下载多少字节量的数据,这样我们就可以知道总共需要下载多少次。文件的大小可以通过HEAD命令来向服务器查询,每次下载的量我们可以自定义比如500kb等。Get、Head命令都会收到服务器发过来的一个描述文件信息的头部,而对于Get来说,头部数据后面紧跟着就是文件的真正数据,这正是我们要下载的目标。
sprintf(send_buffer,"GET %s",path);
strcat(send_buffer," HTTP/1.1\r\n");
strcat(send_buffer,"host: ");
strcat(send_buffer,host_ip);
strcat(send_buffer," : ");
strcat(send_buffer,port);
strcat(send_buffer,buffer_range);
strcat(send_buffer, "\r\nKeep-Alive: 200");
strcat(send_buffer,"\r\nConnection: Keep-Alive\r\n\r\n");
上面的代码便是构造Get命令的代码,其中的path就是我们解析出来的服务端资源路径,host_ip就是通过getaddrinfo(url)得到的ip地址,buffer_range表示要下载的文件的范围,比如第1字节到第1000字节。这些格式化的信息要通过Linux send()函数发送给服务端,然后我们通过recv()函数接收服务端发送过来的响应。
2. 创建断点文件
什么是断点文件呢?以大家最熟悉的迅雷为例,没有下载完的文件,下次可以启动迅雷接着下载,而不用从头开始下载,其实是迅雷记住了上次下载中断时的一些信息,而我们的断点文件就是用来还原上次下载中断时的现场,以便我们可以继续上次结束的地方接着下载,也即断点续传。
顺着流程图中的数字2我们来到一个矩形小方框,从框里的内容我们可以得知我们需要对文件进行分片,所谓的分片也即把整个文件分成N等分,然后其中的每m个等分组成一个task,这样的话就会有N/m个task,后续将会创建一些线程,每一个线程负责下载其中的若干task. 为了完成这件事情,我们首先来到数字3标志的执行流:向服务器发起连接,发送HEAD请求、服务器响应请求向客户端发送信息。根据这些信息,JDownlaod就可以对文件进行分片,然后创建断点文件了。
顺着图中数字4标志的箭头,我们为快车创建了一个断点文件:flashget.exe.jbp. 正如上文所述,断点文件时用来恢复下载现场用的,因此要记录一下关键信息。最开头的部分记录了文件的大小、被分成了多少个task(后续每一个线程会下载其中的1个或多个task)、每一个分片的大小、分片的数目。紧接着后面挨个描述了每一个task(或者part)的信息,以part-n为例,该task包含了第(n-1)*6到第n*6个分片,当前已经下载完成了1个分片,该task包含一个168字节的数据,168不足一个分片的大小,因此单独拿出来描述(图中的数据只是一个示意,并不是真实数据)。当然只有最后一个task才会出现不足一个分片的情况。显然有了这些信息,不管下载的过程何时中断,以及中断多少次,我们都可以恢复现场。
断点文件创建完毕后,我们沿着图中的数字5表示的箭头,在本地磁盘创建同名文件,为后续接收socket发来的数据做准备。
3. 多线程下载
从图中我们可以看出,创建了3个线程用于下载文件,以线程1为例,从数字6-1处可以看到,先从断点文件里读取part-0处的信息,得知需要下载第1到6个分片,而且当前并没有已经下载完毕的分片。于是沿着6-2,线程向服务端挨个请求这6个分片的数据。收到数据后沿着6-3将文件数据写到对应的offset处。这里多个线程是并发写入文件的,由于每一个线程写入的范围并没有交集,所以不需要用锁来保护数据的一致性。从图中可以看出线程1将分片1,2写入了文件中,紧接着沿着数字6-4线程应该更新断点文件,具体是更新当前已经下载了多少个分片的那个字段,这样如果文件没有下载完毕,下次重新启动的时候可以从接着已经下载的分片继续下载,而不用重复下载。
当然,未下载完成的文件,下次继续下载时就不用执行数字1,2,3标志的过程了,而是直接读取断点文件,创建线程,每个线程从断点文件里面读取自己分配到的task,如果该task分配已下载完毕则忽略,否则接着上次下载的地方继续下载。
三 结束语
在前几篇博客里面,我们以文字和代码片段的形式叙述了JDownload的实现过程,而本篇博客以图形的方式展示了JDownload的整体概貌,并且顺着图形走了一条完整的下载路径。主要涉及到下载链接的解析、断点文件的设计、多线程的运用。在未来可能会考虑添加FTP的支持。
时间过得真快啊,距离写关于JDownload的第一篇博客已经过去了9个月。
联系方式:https://github.com/junhuster/
JDownload: 一款可以从网络上下载文件的小程序第四篇(整体架构描述)的更多相关文章
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(三),多线程断点下载
一 前言 本篇博客是<JWebFileTrans(JDownload):一款可以从网络上下载文件的小程序>系列博客的第三篇,本篇博客的内容主要是在前两篇的基础上增加多线程的功能.简言之,本 ...
- JWebFileTrans(JDownload): 一款可以从网络上下载文件的小程序(二)
一 前言 本文是上一篇博客JWebFileTrans:一款可以从网络上下载文件的小程序(一)的续集.此篇博客主要在上一篇的基础上加入了断点续传的功能,用户在下载中途停止下载后,下次可以读取断点文件, ...
- JWebFileTrans: 一款可以从网络上下载文件的小程序(一)
一 摘要 JWebFileTrans是一款基于socket的网络文件传输小程序,目前支持从HTTP站点下载文件,后续会增加ftp站点下载.断点续传.多线程下载等功能.其代码已开源到github上面,下 ...
- C# 中从网络上下载文件保存到本地文件
下面是C#中常用的从Internet上下载文件保存到本地的一些方法,没有太多的技巧. 1.通过 WebClient 类下载文件 WebClient webClient = new WebClien ...
- JDFS:一款分布式文件管理系统,第五篇(整体架构描述)
一 前言 截止到目前为止,虽然并不完美,但是JDFS已经初步具备了完整的分布式文件管理功能了,包括:文件的冗余存储.文件元信息的查询.文件的下载.文件的删除等.本文将对JDFS做一个总体的介绍,主要是 ...
- 从网络上下载文件到sd卡上
String SDPATH = Environment.getExternalStorageDirectory() + "/"; String path = SDPATH + &q ...
- Android开发 ---从互联网上下载文件,回调函数,图片压缩、倒转
Android开发 ---从互联网上下载文件,回调函数,图片压缩.倒转 效果图: 描述: 当点击“下载网络图像”按钮时,系统会将图二中的照片在互联网上找到,并显示在图像框中 注意:这个例子并没有将图 ...
- 通过cmd命令到ftp上下载文件
通过cmd命令到ftp上下载文件 点击"开始"菜单.然后输入"cmd"点"enter"键,出现cmd命令执行框 2 输入"ftp& ...
- 【转】精选十二款餐饮、快递、票务行业微信小程序源码demo推荐
微信小程序的初衷是为了线下实体业服务的,必须有实体相结合才能显示小程序的魅力.个人认为微信小程序对于餐饮业和快递业这样业务比较单一的行业比较有市场,故整理推荐12款餐饮业和快递业微信小程序源码demo ...
随机推荐
- 开源项目Druid的提取SQL模板
在数据库审计中,常常用到SQL模板,这样提取一次模板,下一次就不用对相同的模板的SQL进行相关操作.对此Druid提供相应的工具类进行SQL模板提取: package com.dbappsecurit ...
- C#之实参和形参
1.值类型 例如:我们定义一个函数 static void Exchange(int x, int y) { int flag = x; flag = y; y = x; x = flag; } 其中 ...
- 第二次项目冲刺(Beta阶段)5.20
1.提供当天站立式会议照片一张 会议内容: ①检查前一天的任务情况,心得分享以及困难分析. ②制定新一轮的任务计划. 2.每个人的工作 (1)工作安排 队员 今日进展 明日安排 王婧 #42文件分类改 ...
- 201521123003《Java程序设计》第7周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图或其他)归纳总结集合相关内容. 参考资料: XMind 2. 书面作业 Q1.ArrayList代码分析 1.1 解释ArrayList的contains源 ...
- 201521123006 《Java程序设计》第3周学习总结
本周学习总结 1. 本周学习总结 初学面向对象,会学习到很多碎片化的概念与知识.尝试学会使用思维导图将这些碎片化的概念.知识组织起来.请使用纸笔或者下面的工具画出本周学习到的知识点.截图或者拍照上传. ...
- 201521123105 第10周Java学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结异常与多线程相关内容. 2. 书面作业 本次PTA作业题集异常.多线程 1.finally 题目4-21.1 截图你的提交结果(出现 ...
- JAVA课程设计猜数游戏 个人
1.团队课程设计博客链接 https://i.cnblogs.com/EditPosts.aspx?postid=7067843&update=1 2.个人负责模块说明 输入用户ID 2.主要 ...
- Optional变量初学者指南
苹果三周前发布了Swift. 从那时起,我一直在阅读Swift的官方指南,并在Xcode 6测试版中使用. 我开始喜欢Swift的简单和语法. 与我的团队一起,我仍然在研究新的语言,并看看它与Obje ...
- MD格式示例
一个例子: 例子开始 1. 本章学习总结 今天主要学习了三个知识点 封装 继承 多态 2. 书面作业 Q1. java HelloWorld命令中,HelloWorld这个参数是什么含义? 今天学了一 ...
- 商城项目整理(四)JDBC+富文本编辑器实现商品增加,样式设置,和修改
UEditor富文本编辑器:http://ueditor.baidu.com/website/ 相应页面展示: 商品添加: 商品修改: 前台商品展示: 商品表建表语句: create table TE ...