CUDA compiler driver nvcc 散点 part 2
● nvcc 编译流程图
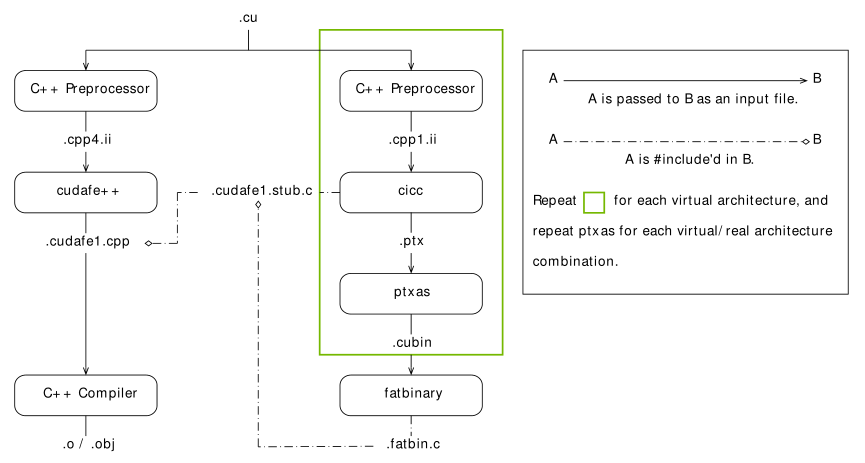
● sm 是向前兼容的,高的版本号是在低版本号的基础上添加了新功能得到的,同一 compute_XY 编译的 .cu 文件仅能向后 sm_ZW 的实 GPU 版本(Z > X)


● 虚拟 GPU 完全由它提供给应用程序的一组功能或特征来定义
● PTX 可以视为虚拟 GPU 的 汇编,以文本格式表示,便于进一步编译为各格式的二进制机器码
● 编译时应尽量降低虚拟 GPU 版本(增加兼容性),同时尽量提高实际 GPU 版本(在知道运行 GPU 的情况下)
● 即时编译(JIT)模式下驱动知道 runtime GPU 的信息,可以编译最佳版本的代码,离线编译和 JIT 的流程图分别如下:

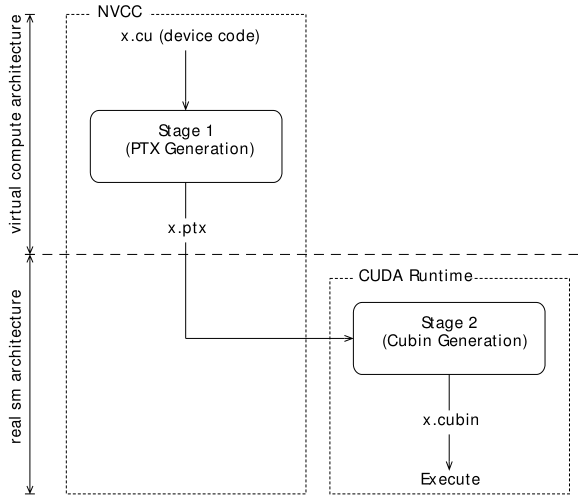
● 仅指定虚 GPU 版本而不指定实 GPU 版本时(如 nvcc x.cu -arch=compute_50 [-code=compute_50]),PTX 将延迟到运行时才进行编译,有启动延迟
● 消灭启动延迟的方法:
■ CUDA 驱动编译缓存
■ 编译时指定多个实 GPU 版本(如 nvcc x.cu -arch=compute_50 -code=sm_50,sm_52),设备函数的多个版本存储在 x.fatbin 中,运行时由驱动自动识别和调用
● 关于 -arch 和 -code 的要点
■ 仅指定 -arch 为虚 GPU 版本,-code 自动匹配最接近的版本(如 nvcc x.cu -arch=compute_50 等价于 nvcc x.cu -arch=compute_50 -code=compute_50)
■ 仅指定 -arch 为实 GPU 版本,-code 自动匹配最接近的版本(如 nvcc x.cu -arch=sm_50 等价于 nvcc x.cu -arch=compute_50 -code=sm_50,compute_50)
■ 同时指定 -arch 和 -code 为虚 GPU 版本,必须一致
■ 均不指定,使用默认值(如 nvcc x.cu 等价于 nvcc x.cu -arch=compute_30 -code=)
■ 默认 -arch 值就是 sm_XX
■ 编译第一阶段中有宏定义 __CUDA_ARCH__ 代表虚 GPU 版本,可用于 __device__ 函数中,用于指明该函数所用的虚 GPU 版本
● 没有指定 --keep 时 nvcc 使用临时目录来保存中间文件,编译完成后立即删除,Windows 中使用环境变量 TEMP 或默认目录 C:\Windows\temp,Linux 使用环境变量 TMPDIR 或默认目录 /tmp
● CUDA 5.0 开始支持分离编译,流程图如下。
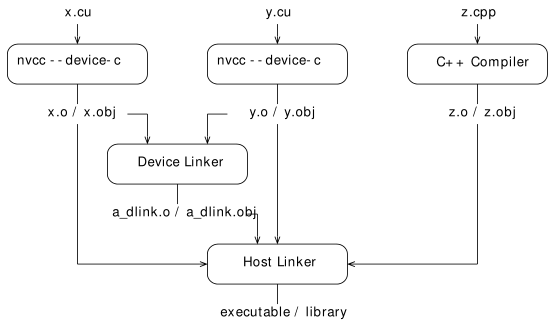
■ 自己在电脑上实验分离编译,VS中能通过,gcc 中没有成功,编译过程没有问题,运行时提示 couldn't get the symbol addr,留坑。
//---------- b.h ----------
#define N 8
extern __device__ int g[N];
extern __device__ void bar(void); //---------- b.cu ----------
#include "b.h"
__device__ int g[N];
__device__ void bar(void)
{
g[threadIdx.x]++;
} //---------- a.cu ----------
#include <stdio.h>
#include "b.h"
__global__ void foo(void)
{
__shared__ int a[N];
a[threadIdx.x] = threadIdx.x;
__syncthreads();
g[threadIdx.x] = a[blockDim.x - threadIdx.x - ];
bar();
} int main(void)
{
unsigned int i;
int *dg, hg[N];
int sum = ;
foo << <, N >> >();
if (cudaGetSymbolAddress((void**)&dg, g))
{
printf("couldn't get the symbol addr\n");
return ;
}
if (cudaMemcpy(hg, dg, N * sizeof(int), cudaMemcpyDeviceToHost))
{
printf("couldn't memcpy\n");
return ;
}
for (i = ; i < N; i++)
sum += hg[i];
if (sum == )
printf("PASSED\n");
else
printf("FAILED (%d)\n", sum);
return ;
}
■ 书上用到的编译命令
nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 a.o b.o nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 --device-link a.o b.o --output-file link.o
g++ a.o b.o link.o --library-path=<path> --library=cudart nvcc --gpu-architecture=sm_50 --device-link a.o b.o --cubin --output-file link.cubin nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --lib a.o b.o --output-file test.a
nvcc --gpu-architecture=sm_50 test.a nvcc --gpu-architecture=sm_50 --device-c a.ptx nvcc --gpu-architecture=sm_50 --device-c a.cu b.cu
nvcc --gpu-architecture=sm_50 --device-link a.o b.o --output-file link.o
nvcc --lib --output-file libgpu.a a.o b.o link.o
g++ host.o --library=gpu --library-path=<path> --library=cudadevrt --library=cudart
CUDA compiler driver nvcc 散点 part 2的更多相关文章
- CUDA compiler driver nvcc 散点 part 1
▶ 参考[https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html] ▶ nvcc 预定义的宏 __NVCC__ // 编译 ...
- 显卡,显卡驱动,nvcc, cuda driver,cudatoolkit,cudnn到底是什么?
在使用深度学习框架的过程中一定会经常碰到这些东西,虽然anaconda有时会帮助我们自动地解决这些设置,但是有些特殊的库却还是需要我们手动配置环境,但是我对标题上的这些名词其实并不十分清楚,所以老是被 ...
- centos7.0安装cuda驱动
00.CUDA简介 CUDA和GPU的并行处理能力来加速深度学习和其他计算密集型应用程序 01.CPU+GPU协同架构 02.部署环境 [docker@lab-250 ~]$ cat /etc/*re ...
- cuda cudnn anaconda gcc tensorflow 安装及环境配置
1.首先,默认你已经装了适合你的显卡的nvidia驱动. 到 http://www.nvidia.com/Download/index.aspx 搜索你的显卡需要的驱动型号 那么接下来就是cuda的 ...
- [笔记] Ubuntu 18.04安装cuda 10及cudnn 7流程
安装环境 OS:Ubuntu 18.04 64 bit 显卡:NVidia GTX 1080 任务:安装 CUDA 10及cuDNN 7 工具下载 NVidia官网下载下列文件: CUDA 10:cu ...
- Jetson tx1 安装cuda错误
前两天安装Jetpack3.0的时候,看着网上的教程以为cuda会自动安装上,但是历经好几次安装,都安装不上cuda,也刷了好几次jetpack包.搜遍了网上的教程,也没有安装上.错误如下图所示: 这 ...
- 记录下自己安装cuda以及cudnn
之前已经装过一次了,不过没有做记录,现在又要翻一堆博客安装,长点记性,自己记录下. 环境 ubuntu16.04 python2.7 商家送过来时候已经装好了显卡驱动,所以省去了一大麻烦. 剩下的就是 ...
- Caffe+Kubuntu16.04_X64+CUDA 8.0配置
前言: 经过尝试过几次Caffe,theano,MxNet之后,很长时间没有进行caffe的更新,此次在Ubuntu16.04下安装Caffe,折腾了一天时间,终于安装成功. 参考链接:Caffe+U ...
- 安装CUDA和cuDNN
GPU和CPU区别 1,CPU主要用于处理通用逻辑,以及各种中断事物 2,GPU主要用于计算密集型程序,可并行运作: NVIDIA 的 GeForce 显示卡系列采用 GPU 特性进行快速计算,渲染电 ...
随机推荐
- 只有mdf文件和ldf文件--怎么恢复数据库
1.将mdf和ldf放到你电脑的路径中. 2.执行以下语句 USE master; GO CREATE DATABASE DBName ON (FILENAME = 'C:\Program Files ...
- visual stutio 20017
Visual Studio 2017入門: https://www.atmarkit.co.jp/ait/articles/1704/10/news026.html vb 手册: http://vb. ...
- qt+opencv LNK4272:library machine type 'x64' conflicts with target mathine type 'x86'
运行时报错如上图所示,原因是你使用的opencv库是64位的,qt里面使用的编译器MSVC是32位的,解决方法如下: 将构建套件修改位64bit:
- JZ2440支持设备树(1)-添加设备树之后kernel的启动参数跟dts里面不一致
在做之前参考了如下博客文章,再次非常感谢: http://www.cnblogs.com/pengdonglin137/p/6241895.html Uboot中需要在config中添加如下宏: #d ...
- Oracle深入学习
一.甲骨文公司介绍 甲骨文公司,是全球最大的企业级软件公司,总部位于美国加利福尼亚州的红木滩.1989年正式进入中国市场. 2013年,甲骨文已超越 IBM ,成为继 Microsoft 后全球第二大 ...
- java基本数据类型和运算符
一.基本数据类型 种类: 内置数据类型 引用数据类型 1.内置数据类型 一共有八种基本类型,六个数字类型(四个整数类型,两个浮点型),一个布尔型,一个字符类型. (1)byte: byte数据类型是8 ...
- 经典问题----最小生成树(kruskal克鲁斯卡尔贪心算法)
题目简述:假如有一个无向连通图,有n个顶点,有许多(带有权值即长度)边,让你用在其中选n-1条边把这n个顶点连起来,不漏掉任何一个点,然后这n-1条边的权值总和最小,就是最小生成树了,注意,不可绕成圈 ...
- 常用的几个CSS前端效果
做页面需要一定的CSS基本功,虽然现在有很多成熟的框架如bootstrap等,我们轻松的就就可以做出一些页面效果.但是掌握每一个常见效果的写法还是很重要的,下面整理出一些常见的CSS前端效果,让你更轻 ...
- 学习php
一.php是什么? 1.PHP:Hypertext Preprocessor(超文本预处理语言),是一种开源脚本语言. 2.PHP是脚本语言 3.PHP最流行的网站开发语言 4.PHP官网:http: ...
- 芯灵思Sinlinx A64开发板设置qt程序自启动
开发平台 芯灵思Sinlinx A64 内存: 1GB 存储: 4GB 开发板详细参数 https://m.tb.cn/h.3wMaSKm 对于开发板开机启动程序的设置可以这样做通过串口连接开发板 v ...