机器学习之高斯混合模型及EM算法
第一部分:
这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation)。
与k-means一样,给定的训练样本是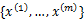 ,我们将隐含类别标签用
,我们将隐含类别标签用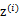 表示。与k-means的硬指定不同,我们首先认为
表示。与k-means的硬指定不同,我们首先认为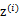 是满足一定的概率分布的,这里我们认为满足多项式分布,
是满足一定的概率分布的,这里我们认为满足多项式分布,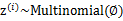 ,其中
,其中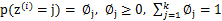 ,
,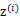 有k个值{1,…,k}可以选取。而且我们认为在给定
有k个值{1,…,k}可以选取。而且我们认为在给定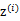 后,
后,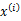 满足多值高斯分布,即
满足多值高斯分布,即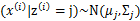 。由此可以得到联合分布
。由此可以得到联合分布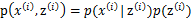 。
。
整个模型简单描述为对于每个样例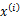 ,我们先从k个类别中按多项式分布抽取一个
,我们先从k个类别中按多项式分布抽取一个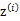 ,然后根据
,然后根据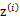 所对应的k个多值高斯分布中的一个生成样例
所对应的k个多值高斯分布中的一个生成样例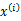 ,。整个过程称作混合高斯模型。注意的是这里的
,。整个过程称作混合高斯模型。注意的是这里的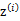 仍然是隐含随机变量。模型中还有三个变量
仍然是隐含随机变量。模型中还有三个变量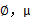 和
和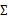 。最大似然估计为
。最大似然估计为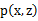 。对数化后如下:
。对数化后如下:
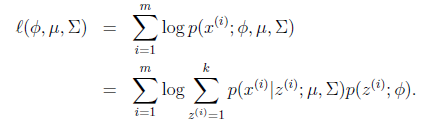
这个式子的最大值是不能通过前面使用的求导数为0的方法解决的,因为求的结果不是close form。但是假设我们知道了每个样例的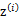 ,那么上式可以简化为:
,那么上式可以简化为:
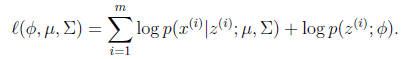
这时候我们再来对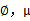 和
和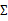 进行求导得到:
进行求导得到:
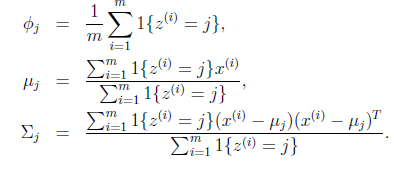
 就是样本类别中
就是样本类别中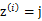 的比率。
的比率。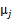 是类别为j的样本特征均值,
是类别为j的样本特征均值,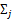 是类别为j的样例的特征的协方差矩阵。
是类别为j的样例的特征的协方差矩阵。
实际上,当知道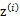 后,最大似然估计就近似于高斯判别分析模型(Gaussian discriminant analysis model)了。所不同的是GDA中类别y是伯努利分布,而这里的z是多项式分布,还有这里的每个样例都有不同的协方差矩阵,而GDA中认为只有一个。
后,最大似然估计就近似于高斯判别分析模型(Gaussian discriminant analysis model)了。所不同的是GDA中类别y是伯努利分布,而这里的z是多项式分布,还有这里的每个样例都有不同的协方差矩阵,而GDA中认为只有一个。
之前我们是假设给定了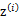 ,实际上
,实际上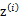 是不知道的。那么怎么办呢?考虑之前提到的EM的思想,第一步是猜测隐含类别变量z,第二步是更新其他参数,以获得最大的最大似然估计。用到这里就是:
是不知道的。那么怎么办呢?考虑之前提到的EM的思想,第一步是猜测隐含类别变量z,第二步是更新其他参数,以获得最大的最大似然估计。用到这里就是:
|
循环下面步骤,直到收敛: { (E步)对于每一个i和j,计算
(M步),更新参数:
} |
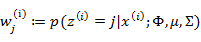
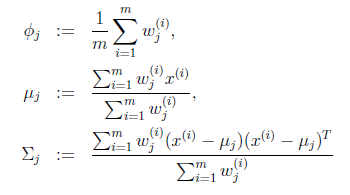
在E步中,我们将其他参数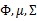 看作常量,计算
看作常量,计算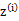 的后验概率,也就是估计隐含类别变量。估计好后,利用上面的公式重新计算其他参数,计算好后发现最大化最大似然估计时,
的后验概率,也就是估计隐含类别变量。估计好后,利用上面的公式重新计算其他参数,计算好后发现最大化最大似然估计时,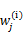 值又不对了,需要重新计算,周而复始,直至收敛。
值又不对了,需要重新计算,周而复始,直至收敛。
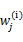 的具体计算公式如下:
的具体计算公式如下:
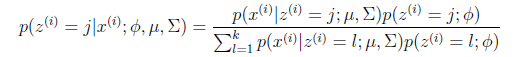
这个式子利用了贝叶斯公式。
这里我们使用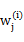 代替了前面的
代替了前面的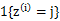 ,由简单的0/1值变成了概率值。
,由简单的0/1值变成了概率值。
对比K-means可以发现,这里使用了“软”指定,为每个样例分配的类别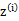 是有一定的概率的,同时计算量也变大了,每个样例i都要计算属于每一个类别j的概率。与K-means相同的是,结果仍然是局部最优解。对其他参数取不同的初始值进行多次计算不失为一种好方法。
是有一定的概率的,同时计算量也变大了,每个样例i都要计算属于每一个类别j的概率。与K-means相同的是,结果仍然是局部最优解。对其他参数取不同的初始值进行多次计算不失为一种好方法。
虽然之前再K-means中定性描述了EM的收敛性,仍然没有定量地给出,还有一般化EM的推导过程仍然没有给出。下一篇着重介绍这些内容。
第二部分:
EM是我一直想深入学习的算法之一,第一次听说是在NLP课中的HMM那一节,为了解决HMM的参数估计问题,使用了EM算法。在之后的MT中的词对齐中也用到了。在Mitchell的书中也提到EM可以用于贝叶斯网络中。
下面主要介绍EM的整个推导过程。
1. Jensen不等式
回顾优化理论中的一些概念。设f是定义域为实数的函数,如果对于所有的实数x,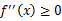 ,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的(
,那么f是凸函数。当x是向量时,如果其hessian矩阵H是半正定的(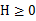 ),那么f是凸函数。如果
),那么f是凸函数。如果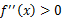 或者
或者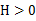 ,那么称f是严格凸函数。
,那么称f是严格凸函数。
Jensen不等式表述如下:
如果f是凸函数,X是随机变量,那么
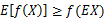
特别地,如果f是严格凸函数,那么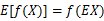 当且仅当
当且仅当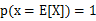 ,也就是说X是常量。
,也就是说X是常量。
这里我们将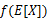 简写为
简写为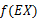 。
。
如果用图表示会很清晰:
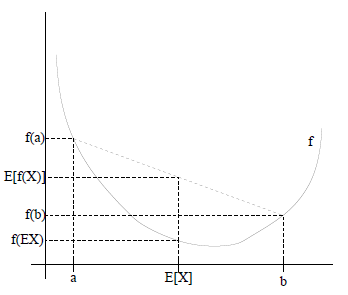
图中,实线f是凸函数,X是随机变量,有0.5的概率是a,有0.5的概率是b。(就像掷硬币一样)。X的期望值就是a和b的中值了,图中可以看到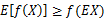 成立。
成立。
当f是(严格)凹函数当且仅当-f是(严格)凸函数。
Jensen不等式应用于凹函数时,不等号方向反向,也就是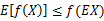 。
。
2. EM算法
给定的训练样本是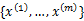 ,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:
,样例间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:
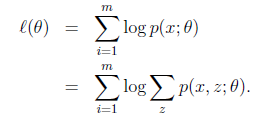
第一步是对极大似然取对数,第二步是对每个样例的每个可能类别z求联合分布概率和。但是直接求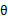 一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
一般比较困难,因为有隐藏变量z存在,但是一般确定了z后,求解就容易了。
EM是一种解决存在隐含变量优化问题的有效方法。竟然不能直接最大化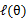 ,我们可以不断地建立
,我们可以不断地建立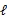 的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
的下界(E步),然后优化下界(M步)。这句话比较抽象,看下面的。
对于每一个样例i,让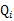 表示该样例隐含变量z的某种分布,
表示该样例隐含变量z的某种分布,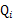 满足的条件是
满足的条件是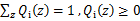 。(如果z是连续性的,那么
。(如果z是连续性的,那么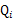 是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。
是概率密度函数,需要将求和符号换做积分符号)。比如要将班上学生聚类,假设隐藏变量z是身高,那么就是连续的高斯分布。如果按照隐藏变量是男女,那么就是伯努利分布了。
可以由前面阐述的内容得到下面的公式:
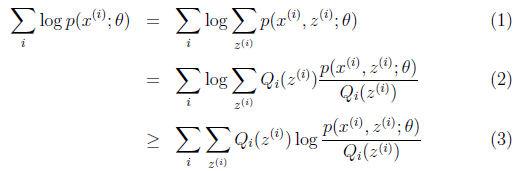
(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式,考虑到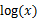 是凹函数(二阶导数小于0),而且
是凹函数(二阶导数小于0),而且
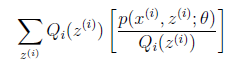
就是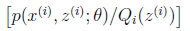 的期望(回想期望公式中的Lazy Statistician规则)
的期望(回想期望公式中的Lazy Statistician规则)
|
设Y是随机变量X的函数 (1) X是离散型随机变量,它的分布律为
(2) X是连续型随机变量,它的概率密度为
|
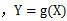 (g是连续函数),那么
(g是连续函数),那么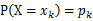 ,k=1,2,…。若
,k=1,2,…。若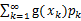 绝对收敛,则有
绝对收敛,则有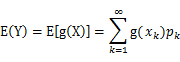
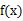 ,若
,若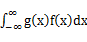 绝对收敛,则有
绝对收敛,则有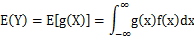
对应于上述问题,Y是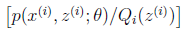 ,X是
,X是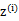 ,
,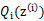 是
是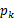 ,g是
,g是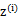 到
到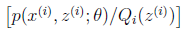 的映射。这样解释了式子(2)中的期望,再根据凹函数时的Jensen不等式:
的映射。这样解释了式子(2)中的期望,再根据凹函数时的Jensen不等式:
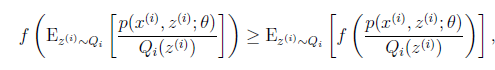
可以得到(3)。
这个过程可以看作是对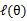 求了下界。对于
求了下界。对于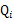 的选择,有多种可能,那种更好的?假设
的选择,有多种可能,那种更好的?假设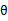 已经给定,那么
已经给定,那么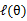 的值就决定于
的值就决定于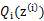 和
和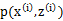 了。我们可以通过调整这两个概率使下界不断上升,以逼近
了。我们可以通过调整这两个概率使下界不断上升,以逼近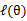 的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于
的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率能够等价于 了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,这里得到:
了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,这里得到:
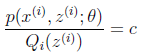
c为常数,不依赖于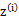 。对此式子做进一步推导,我们知道
。对此式子做进一步推导,我们知道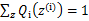 ,那么也就有
,那么也就有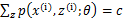 ,(多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),那么有下式:
,(多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c),那么有下式:
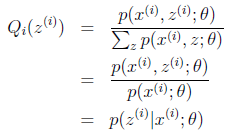
至此,我们推出了在固定其他参数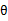 后,
后,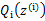 的计算公式就是后验概率,解决了
的计算公式就是后验概率,解决了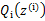 如何选择的问题。这一步就是E步,建立
如何选择的问题。这一步就是E步,建立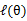 的下界。接下来的M步,就是在给定
的下界。接下来的M步,就是在给定 后,调整
后,调整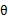 ,去极大化
,去极大化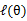 的下界(在固定
的下界(在固定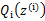 后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
|
循环重复直到收敛 { (E步)对于每一个i,计算
(M步)计算
|
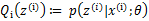
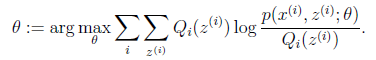
那么究竟怎么确保EM收敛?假定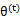 和
和 是EM第t次和t+1次迭代后的结果。如果我们证明了
是EM第t次和t+1次迭代后的结果。如果我们证明了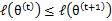 ,也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定
,也就是说极大似然估计单调增加,那么最终我们会到达最大似然估计的最大值。下面来证明,选定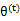 后,我们得到E步
后,我们得到E步
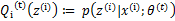
这一步保证了在给定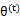 时,Jensen不等式中的等式成立,也就是
时,Jensen不等式中的等式成立,也就是
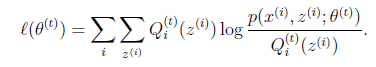
然后进行M步,固定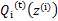 ,并将
,并将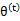 视作变量,对上面的
视作变量,对上面的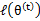 求导后,得到
求导后,得到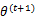 ,这样经过一些推导会有以下式子成立:
,这样经过一些推导会有以下式子成立:
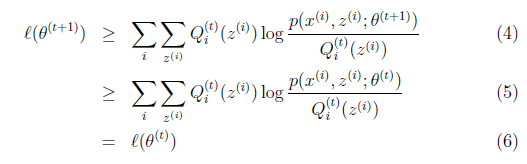
解释第(4)步,得到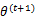 时,只是最大化
时,只是最大化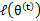 ,也就是
,也就是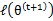 的下界,而没有使等式成立,等式成立只有是在固定
的下界,而没有使等式成立,等式成立只有是在固定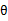 ,并按E步得到
,并按E步得到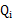 时才能成立。
时才能成立。
况且根据我们前面得到的下式,对于所有的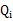 和
和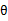 都成立
都成立
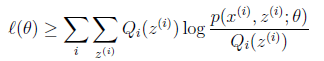
第(5)步利用了M步的定义,M步就是将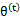 调整到
调整到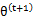 ,使得下界最大化。因此(5)成立,(6)是之前的等式结果。
,使得下界最大化。因此(5)成立,(6)是之前的等式结果。
这样就证明了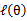 会单调增加。一种收敛方法是
会单调增加。一种收敛方法是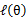 不再变化,还有一种就是变化幅度很小。
不再变化,还有一种就是变化幅度很小。
再次解释一下(4)、(5)、(6)。首先(4)对所有的参数都满足,而其等式成立条件只是在固定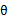 ,并调整好Q时成立,而第(4)步只是固定Q,调整
,并调整好Q时成立,而第(4)步只是固定Q,调整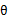 ,不能保证等式一定成立。(4)到(5)就是M步的定义,(5)到(6)是前面E步所保证等式成立条件。也就是说E步会将下界拉到与
,不能保证等式一定成立。(4)到(5)就是M步的定义,(5)到(6)是前面E步所保证等式成立条件。也就是说E步会将下界拉到与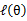 一个特定值(这里
一个特定值(这里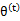 )一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与
)一样的高度,而此时发现下界仍然可以上升,因此经过M步后,下界又被拉升,但达不到与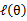 另外一个特定值一样的高度,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到最大值。
另外一个特定值一样的高度,之后E步又将下界拉到与这个特定值一样的高度,重复下去,直到最大值。
如果我们定义
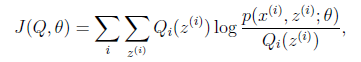
从前面的推导中我们知道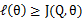 ,EM可以看作是J的坐标上升法,E步固定
,EM可以看作是J的坐标上升法,E步固定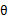 ,优化
,优化 ,M步固定
,M步固定 优化
优化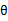 。
。
3. 重新审视混合高斯模型
我们已经知道了EM的精髓和推导过程,再次审视一下混合高斯模型。之前提到的混合高斯模型的参数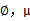 和
和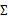 计算公式都是根据很多假定得出的,有些没有说明来由。为了简单,这里在M步只给出
计算公式都是根据很多假定得出的,有些没有说明来由。为了简单,这里在M步只给出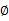 和
和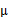 的推导方法。
的推导方法。
E步很简单,按照一般EM公式得到:
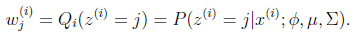
简单解释就是每个样例i的隐含类别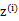 为j的概率可以通过后验概率计算得到。
为j的概率可以通过后验概率计算得到。
在M步中,我们需要在固定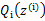 后最大化最大似然估计,也就是
后最大化最大似然估计,也就是
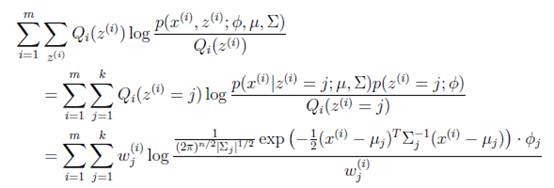
这是将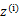 的k种情况展开后的样子,未知参数
的k种情况展开后的样子,未知参数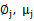 和
和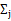 。
。
固定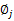 和
和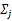 ,对
,对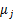 求导得
求导得
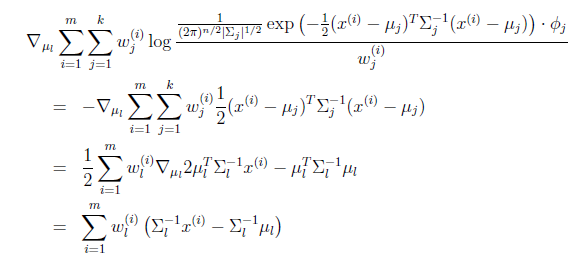
等于0时,得到
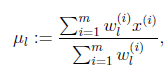
这就是我们之前模型中的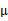 的更新公式。
的更新公式。
然后推导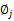 的更新公式。看之前得到的
的更新公式。看之前得到的
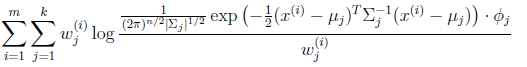
在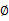 和
和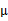 确定后,分子上面的一串都是常数了,实际上需要优化的公式是:
确定后,分子上面的一串都是常数了,实际上需要优化的公式是:
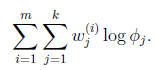
需要知道的是,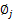 还需要满足一定的约束条件就是
还需要满足一定的约束条件就是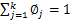 。
。
这个优化问题我们很熟悉了,直接构造拉格朗日乘子。
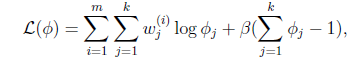
还有一点就是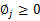 ,但这一点会在得到的公式里自动满足。
,但这一点会在得到的公式里自动满足。
求导得,
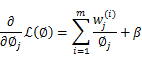
等于0,得到
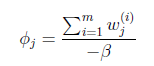
也就是说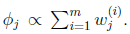 再次使用
再次使用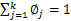 ,得到
,得到
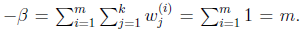
这样就神奇地得到了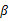 。
。
那么就顺势得到M步中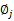 的更新公式:
的更新公式:
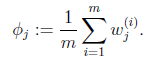
 的推导也类似,不过稍微复杂一些,毕竟是矩阵。结果在之前的混合高斯模型中已经给出。
的推导也类似,不过稍微复杂一些,毕竟是矩阵。结果在之前的混合高斯模型中已经给出。
4. 总结
如果将样本看作观察值,潜在类别看作是隐藏变量,那么聚类问题也就是参数估计问题,只不过聚类问题中参数分为隐含类别变量和其他参数,这犹如在x-y坐标系中找一个曲线的极值,然而曲线函数不能直接求导,因此什么梯度下降方法就不适用了。但固定一个变量后,另外一个可以通过求导得到,因此可以使用坐标上升法,一次固定一个变量,对另外的求极值,最后逐步逼近极值。对应到EM上,E步估计隐含变量,M步估计其他参数,交替将极值推向最大。EM中还有“硬”指定和“软”指定的概念,“软”指定看似更为合理,但计算量要大,“硬”指定在某些场合如K-means中更为实用(要是保持一个样本点到其他所有中心的概率,就会很麻烦)。
另外,EM的收敛性证明方法确实很牛,能够利用log的凹函数性质,还能够想到利用创造下界,拉平函数下界,优化下界的方法来逐步逼近极大值。而且每一步迭代都能保证是单调的。最重要的是证明的数学公式非常精妙,硬是分子分母都乘以z的概率变成期望来套上Jensen不等式,前人都是怎么想到的。
在Mitchell的Machine Learning书中也举了一个EM应用的例子,明白地说就是将班上学生的身高都放在一起,要求聚成两个类。这些身高可以看作是男生身高的高斯分布和女生身高的高斯分布组成。因此变成了如何估计每个样例是男生还是女生,然后在确定男女生情况下,如何估计均值和方差,里面也给出了公式,有兴趣可以参考。
原博文:http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html(一)
http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html(二)
机器学习之高斯混合模型及EM算法的更多相关文章
- 机器学习 : 高斯混合模型及EM算法
Mixtures of Gaussian 这一讲,我们讨论利用EM (Expectation-Maximization)做概率密度的估计.假设我们有一组训练样本x(1),x(2),...x(m),因为 ...
- 高斯混合模型的EM算法
高斯混合模型的EM算法 混合高斯模型 高斯混合模型的概率分布可以写成多个高斯分布的线形叠加,即 \[ p(\mathbf x) = \sum_{k=1}^{K}\pi_k\mathcal N(\mat ...
- SIGAI机器学习第二十三集 高斯混合模型与EM算法
讲授高斯混合模型的基本概念,训练算法面临的问题,EM算法的核心思想,算法的实现,实际应用. 大纲: 高斯混合模型简介实际例子训练算法面临的困难EM算法应用-视频背景建模总结 高斯混合模型简写GMM,期 ...
- 机器学习基础知识笔记(一)-- 极大似然估计、高斯混合模型与EM算法
似然函数 常说的概率是指给定参数后,预测即将发生的事件的可能性.拿硬币这个例子来说,我们已知一枚均匀硬币的正反面概率分别是0.5,要预测抛两次硬币,硬币都朝上的概率: H代表Head,表示头朝上 p( ...
- 高斯混合模型与EM算法
对于高斯混合模型是干什么的呢?它解决什么样的问题呢?它常用在非监督学习中,意思就是我们的训练样本集合只有数据,没有标签. 它用来解决这样的问题:我们有一堆的训练样本,这些样本可以一共分为K类,用z(i ...
- 聚类之高斯混合模型与EM算法
一.高斯混合模型概述 1.公式 高斯混合模型是指具有如下形式的概率分布模型: 其中,αk≥0,且∑αk=1,是每一个高斯分布的权重.Ø(y|θk)是第k个高斯分布的概率密度,被称为第k个分模型,参数为 ...
- 机器学习第三课(EM算法和高斯混合模型)
极大似然估计,只是一种概率论在统计学的应用,它是参数估计的方法之一.说的是已知某个随机样本满足某种概率分布,但是其中具体的参数不清楚,参数估计就是通过若干次试验,观察其结果,利用结果推出参数的大概值. ...
- 机器学习笔记(十)EM算法及实践(以混合高斯模型(GMM)为例来次完整的EM)
今天要来讨论的是EM算法.第一眼看到EM我就想到了我大枫哥,EM Master,千里马.RUA!!!不知道看这个博客的人有没有懂这个梗的. 好的,言归正传.今天要讲的EM算法,全称是Expectati ...
- 高斯混合和EM算法
首先介绍高斯混合模型: 高斯混合模型是指具有以下形式的概率分布模型: 一般其他分布的混合模型用相应的概率密度代替(1)式中的高斯分布密度即可. 给定训练集,我们希望构建该数据联合分布 这里,其中是概率 ...
随机推荐
- Emmet 记录
Refs 熟悉 css 有优势,emmet 的的缩写语法特别像 css 选择器. =>参考本博笔记 # id > 直接子元素 child . class + Sibling 同级相邻的一个 ...
- Andrew NG 机器学习编程作业6 Octave
问题描述:使用SVM(支持向量机 )实现一个垃圾邮件分类器. 在开始之前,先简单介绍一下SVM ①从逻辑回归的 cost function 到SVM 的 cost function 逻辑回归的假设函数 ...
- 前段js的各种弹出框
artDialog 首页 > 文档与示例 artDialog —— 经典的网页对话框组件,内外皆用心雕琢. 支持普通与 12 方向气泡状对话框 完善的焦点处理,自动焦点附加与回退 支持 ARIA ...
- php的2种域名转向写法
第一种 echo '<meta http-equiv="Refresh" content="0;url=' . $url . '">' ; 第二种 ...
- Coursera Deep Learning 3 Structuring Machine Learning Projects, ML Strategy
Why ML stategy 怎么提高预测准确度?有了stategy就知道从哪些地方入手,而不至于找错方向做无用功. Satisficing and Optimizing metric 上图中,run ...
- 例:判断是不是自有属性hasOwnProperty方法
自有属性和共有属性: 自有属性:直接保存在对象本地的属性 共有属性:保存在原型对象中,被所有子对象共享的属性 获取时:都可用对象.属性方法 赋值时:自有属性,必须:对象.属性 = 值 共有属性,必须: ...
- Jmeter+Ant+Jenkins 接口自动化之简单demo
之前的文章我们已经分享过了 Jmeter+Ant 的批量执行 ,并且搭建好了Jenkins部署平台,如何再将三者完美结合呢? 1.首先打开Jenkins主页面,进入“系统管理-插件管理”,安装相关的插 ...
- spring boot 与 spring cloud 关系
公司使用spring cloud,所以稍微了解一下 看了一下spring官网对 spring boot 以及 spring cloud 的解释 Spring Boot Spring Boot make ...
- 前端 - jquery方式 / iframe +form 方式 上传文件
环境与上一章一样 jquery 方式上传文件: HTML代码 {#html代码开始#} <input type="file" id="img" > ...
- nutz学习笔记(1)
写在前头 最近到了合肥分公司,分公司用的架构为nutz·····目前在根据官方文档(http://nutzam.com/core/nutz_preface.html)自学并实践中,此笔记将不会如官方文 ...