redis主从架构,分片集群详解
写在前面:这篇笔记有点长,如果你认真看完,收获会不少,如果你只是忘记了相关命令,请翻到末尾。
redis的简单介绍:
一个提供多种数据类类型储存,整个系统都在内存中运行的,
定期通过异步的方式把数据刷到磁盘进行保存的一个内存数据库
因为实在内存中操作数据,所以效率非常高,但受制于物理内存的限制,一般用作处理少量数据的高性能操作;
下面开始玩redis,包括主从架构和3.0后的分片集群:
首先安装依赖:
yum -y install cpp binutils glibc glibc-kernheaders glibc-common glibc-devel gcc make gcc-c++ libstdc++-devel tcl
创建文件夹,将rediss上传到该文件夹内,并进行解压:
tar -xvf redis-3.0.2.tar.gz
获得解压文件

进入到解压文件 进行先编译 , 然后安装 :
make (编译) , make install (安装)
把配置文件复制一份到上一级目录(以配置文件驱动redis,完成多个redis服务的启动):
感觉那个压缩包有点扎眼睛,心狠手辣的删掉它,现在编程这样

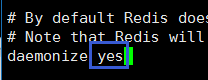
准备后台启动redis,修改配置文件 redis .conf如下所示,保存后退出:
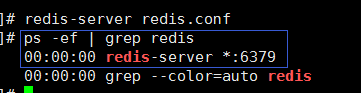
启动redis,因为是后台启动,所以没什么反应,我们查询进程看看是否启动:
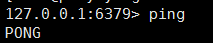
我们运行客户端测试一把,是否 ping 通: redis-cli
好!上面已经将 redis 安装到了我们的服务器,下面开始搭建 redis的主从复制(读写分离):
首先说说主从复制的好处是什么:
1.避免单点故障,预防一个redis挂掉后,redis插槽有空挡,导致集群不可用
2.构建读写分离架构,满足读多写少的的场景(数据库80%的操作都是在读取,这句话是谁说的?)
开始操作,我们需要启动三台 redis 服务,完成主从架构:
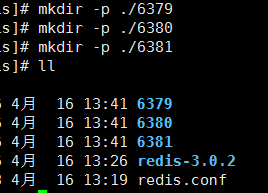
redis 默认的端口为6379 ,我们创建三个目录,放着三个配置文件,分别代表不同的端口:
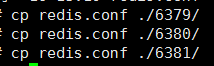
并把配置文件分别复制进这三个端口所代表的目录:
然后分别修改三个文件夹中的配置文件,我们把6379端口的 redis 服务设为 主,其他两个为从


然后以配置文件方式 依次启动三个 redis 服务:
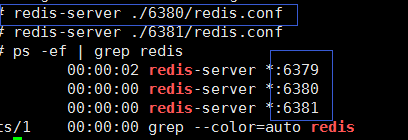
启动客户端分别对三个服务进行测试:


设置主从关系一共有两种方式,:
第一种为在 redis.conf 中配置 ,永久生效 slaveof <主ip> <主端口>
第二种为在redis-cli 中键入,重启服务失效 slaveof <主ip> <主端口>
今天我们测试采用第二种,因为后面还有其他的演示,生产环境下应该使用第一种 永久性配置
我们以6379 做为主 其他两个作为从,完成一下操作


登录 6379 的客户端 查看主从信息:

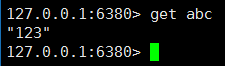
在主库写入和读取数据测试:

我们把数据存放到了 端口为6379 的主库,做了主从,我们就能在从库中把数据拿出来
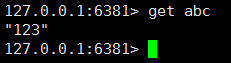
上面我们演示了 主从架构,下面我们演示,主从从架构(链式主从)
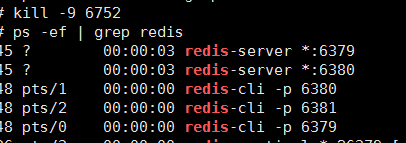
使用 kill -9 命令杀死刚刚我启动的三个 redis 服务,取消刚刚建立的暂时的主从关系:
下面我们建立 6381以 6380 为主,6380 以 6379 为主的链式主从从架构
6381 ——> 6780 ——> 6379
重启服务后,开始搭建我们的主从从架构:
还记得我们刚刚搭建主从的命令吗? slaveof <主ip> <主端口>
6381 以6380 为主:

6380 以 6379 为主 :

我们来到 6379 主库查看 主从信息
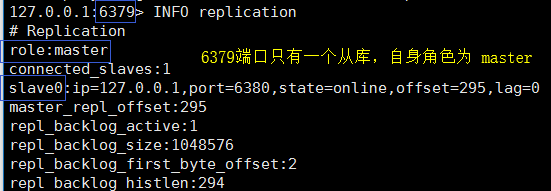
随后我们再来到6380,看看主从情况:
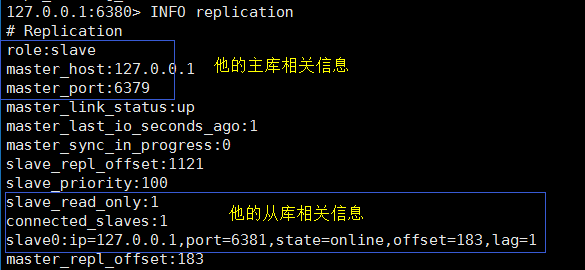
最后一个6381,作为从库,我们就不看了,下面我们再6379 中存取的读取数据测试 (没毛病)
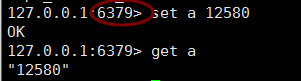
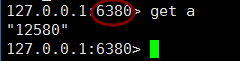
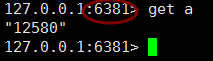
默认情况下从库是不能写入输入的,如要要开启需要配置文件中开启,非只读:
slave-read-only no
说说原理:为什么我们建立主从架构后,在主库中的数据 可以在从库中获取呢?
1、 当从库和主库建立MS关系后,从库会向主数据库发送PSYNC命令;
2、 主库接收到PSYNC命令后会开始在后台保存快照(RDB),并缓存该期间的命令;
3、 当快照完成后,主Redis会将快照文件和所有缓存的写命令发送给从Redis;
4、 从Redis接收到后,会载入快照文件并且执行收到的缓存的命令;
5、 之后,主Redis每当接收到写命令时就会将命令发送从Redis,从而保证数据的一致;
注意:数据是持久化到磁盘,从库redis 加载数据,完成数据同步,中间涉及到磁盘IO
现在可以通过开启无磁盘复制完成数据同步 : repl-diskless-sync yes
原理是不持久化数据到磁盘,直接通过网络发送给 从redis,避免IO性能差(还在测试阶段,不稳定)
常见问题:服务宕机 处理手段:
如果是从库redis 宕机,直接重启,会自动加入主从架构,并自动通过增量复制完成数据同步
如果是主库宕机:选择一个从库断掉主从关系,并将自身提升为主库提供服务 : SLAVEOF NO ONE
重启挂掉的服务,通过 SLAVEOF ip port 将其设置为其他从库的从库,保持主从架构
在上面的主从架构中,主服务宕机没我们得手动重启并加入,这就显得很麻烦,redis有个哨兵机制,可以自动应对上述情况:
哨兵的主要作用:监控redis服务是否正常运行,如果 主reids 宕机,在从库中选取 leader 当新的主库:
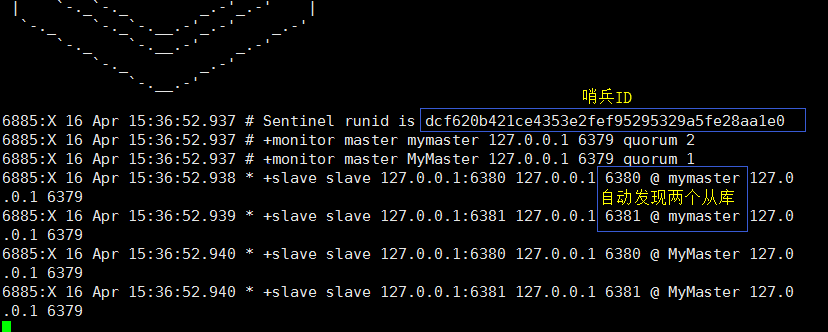
单个哨兵的监控:只监控 master ,自动发现master 下的 slave
多个哨兵的监控:在监控master时,还会互相监督;
下面来看看一主多从下 哨兵的表现:
以 6379 为主 6380 6381 均为 6379 的从,在刚刚的环境下 只需修改6381 重新绑定6379 为主即可:

进入redis 的解压目录 编辑 sentinel.conf 配置文件,追加一个配置 :sentinel monitor MyMaster 127.0.0.1 6379 1

解释: MyMster : 自定义监听主数据的名称
127.0.0.1:监控主数据的 IP
6379 :监控主数据的 port
1 : 最低通过票数
配置完成后,启动哨兵: redis-sentinel ./sentinel.conf
接下来,我们先让从库 6381 宕机,观察哨兵反应如何
 我估计 +sdown 为shutdown的意思 关闭
我估计 +sdown 为shutdown的意思 关闭

我们重启 6381 ,看哨兵反应: reboot : 重新启动 | conver -to slave :使其转变为从库

从库已经试过了,我们再来试试主库宕机会怎么样:
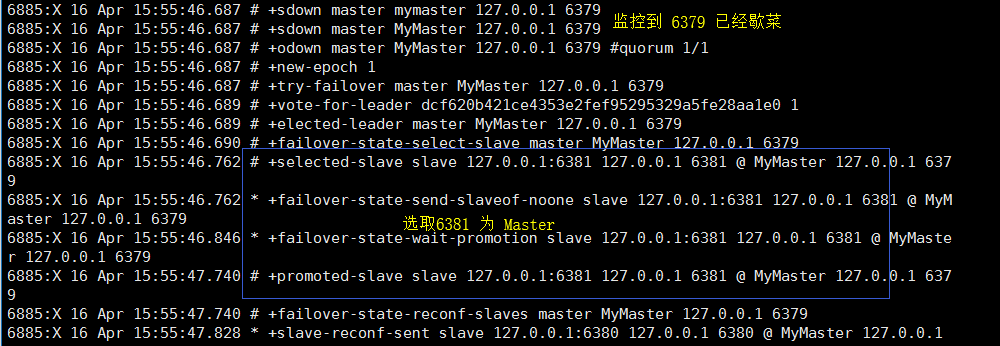
然后我们重启 6379,看看反应:

可以看到 6379 和 6381 都已经成为了 6380 的从库,自动完成主从架构
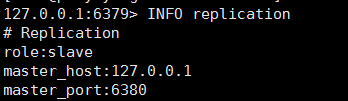
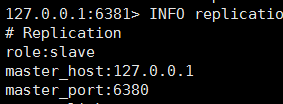
好了,哨兵也就讲到这儿了,下面来架设redis3.0 的自带的分片集群:
所有redis节点互联,超过半数以上的节点检测为失效,才确认为失效,客户端随意连接一个redis即可
参与集群的redis 分摊 16384 个插槽
首先。我们把刚刚搭建的所有redis的服务全部 kill 掉,
删除RDB持久化文件,搭建集群时,所有的 redis 均无数据,为空的
进入三个 redis 修改配置文件: 注意改端口,随后启动启动全部redis 服务

除了点小意味,启动报错不能再slaveof 下开启集群 我把配置文件删掉重新刷了一份,
按理说我关闭服务后 ,主从架构应该消失啊,但是我在创建集群时,主从架构还在,
所以配置文件: 修改端口——开启后台启动——开启集群—— 开启并修改集群配置文件后启动:

因为我们开启集群的配置文件,所以现在目录是这样的了
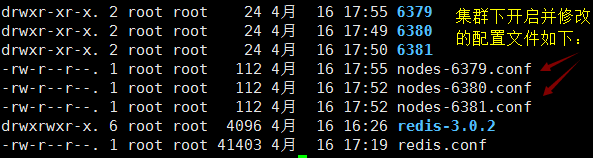
接下来安装 ruby 环境: yum -y install zlib ruby rubygems
rz上传 redis-3.2.1.gem: gem install -l redis-3.2.1.gem
搭建集群环境:
进入到 redis 的解压目录:ll /usr/src/redis/redis-3.0.2/src/
./redis-trib.rb create --replicas 0 192.168.41.130:6379 192.168.41.130:6380 192.168.41.130:6381
replicas 0 : 表示从库数量为 0
后面跟三个要加入集群的机器的 IP Port
注意:ifconfig 查看虚拟机的 ip 这里不能使用127.0.0.1 ,否则 jedis 客户端连接不上
创建集群:
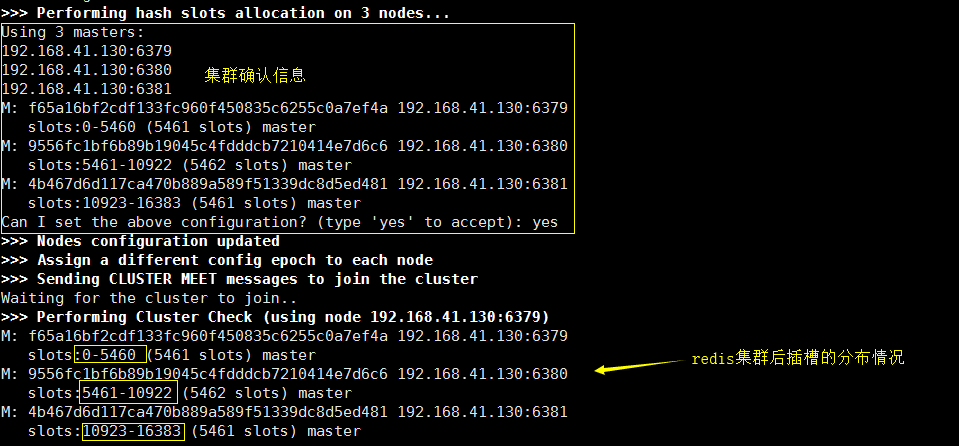
插入数据和获取数据测试:
提示:现在我们不能再使用 redis-cli 来插入数据,因为集群的每个 redis 都有自己的插槽值,
当我们插入一个数据时,不知道 key 的 hash 值是多少,可能该key对应的hash槽不在此区间
我们的6379 的插槽数区间为 0-5460 ,而 abc 的 hash对应的槽所在的redis 应该为 6380 ( 列子)

我们再去6380,插入这条数据,就能成功,但是这样显得就很搓了,
使用 redis-cli -p 6379 -c 连接集群中的6379端口的机器, c: cluster
存入值的时候,自动为我们重定向了 redis

我们登录6381 客户端 redis-cli -p 6381 -c 获取数据,也是给我吗自动定向到了6380:
现在可以随意插入和获取数据了

要吃饭了,先搁置一下,吃完饭再续,好了,睡觉之前把它总结完。
下面我们来查看集群信息,随便选取一个节点,通过 : cluster nodes

其中显示的信息有每个节点的 id , redis的ip port 和身份,连接数,插槽区间;
当我们往集群中插入一条数据时,执行流程为:
首先计算出 key 的插槽值,计算出hash值对 16384取余,得到插槽值
然后根据插槽值找到对应的 redis 节点,
定向到高节点执行插入的命令;
整个集群包含16384个插槽点,被 ./redis-trib.rb 脚本均分给参加集群的 机器节点
集群环境我们已经搭建好了,下面我们来实现 redis 节点的 增 删:
增加节点:
我们再创建一个 6382 端口的redis 服务,
主要修改配置文件中的 :开启后台启动,修改端口,打开集群,打开并修改 集群配置文件,直接启动
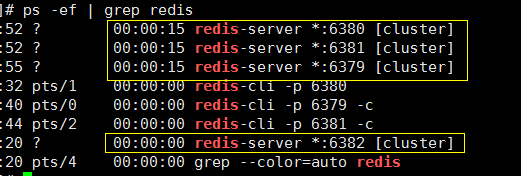
进入redis的解压文件 src/,执行脚本,指定加入集群的随便一个节点的 ip 和 port 即可
cd /usr/src/redis/redis-3.0.2/src/
执行脚本 : ./redis-trib.rb add-node 192.168.41.130:6382 192.168.41.130:6379
第一个 IP port 为要加入集群的redis 的IP和port 第二个为已在集群中的随意一台机器的 IP和port
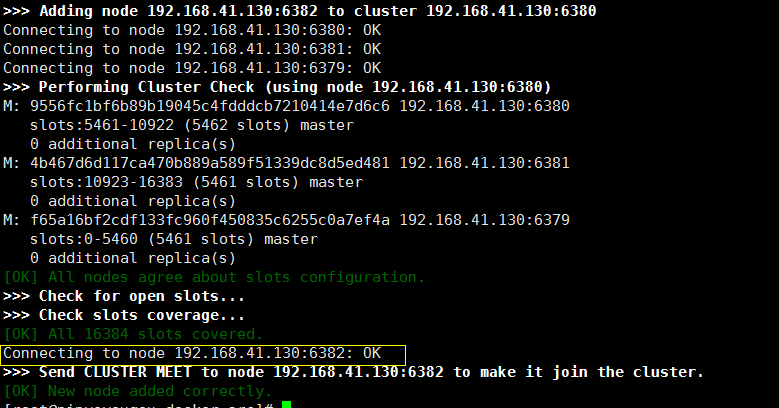
我们再次查看集群信息:随便选取一个节点

集群虽然已经加入,但是并没有自动分配插槽给该节点,我们手动从其他节点(6379) ,划分一点过来
./redis-trib.rb reshard 192.168.41.130:6381(没截到图,用的资料上的图)
给定要分配的插槽数就,比如给 1000
输入接受高插槽数的一个redis 的节点ID
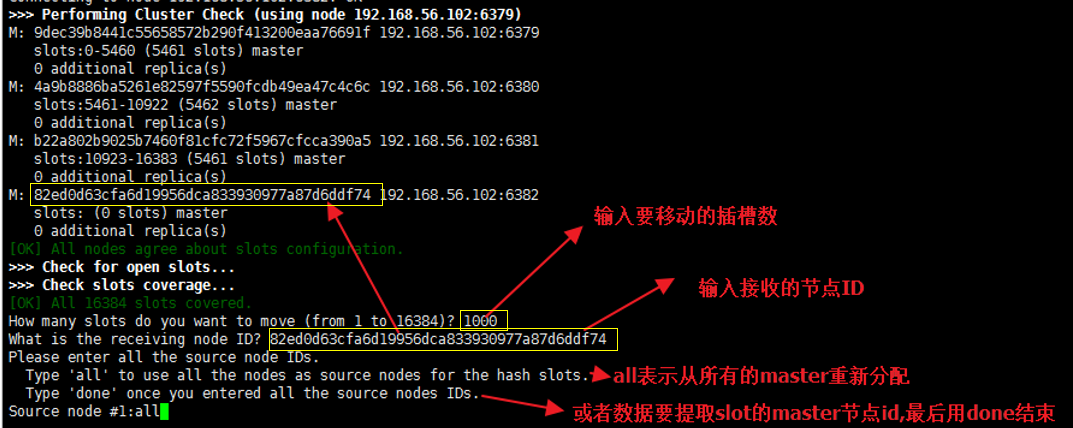
然后通过其他随意一个节点查看集群信息: cluster nodes
总结步骤:
启动服务——> 使用 redis-trib.rb add-node 添加到集群 ——> 分配插槽redis-trib.rb reshard
删除节点:
删除一个节点首先就得把它所有的节点拨给其他的节点,比如我们要删除 6382 节点
我们就应该把 6382节点上的插槽 拨出去 列子中我们拨给 6381,最后必须采用done 类型拨出去
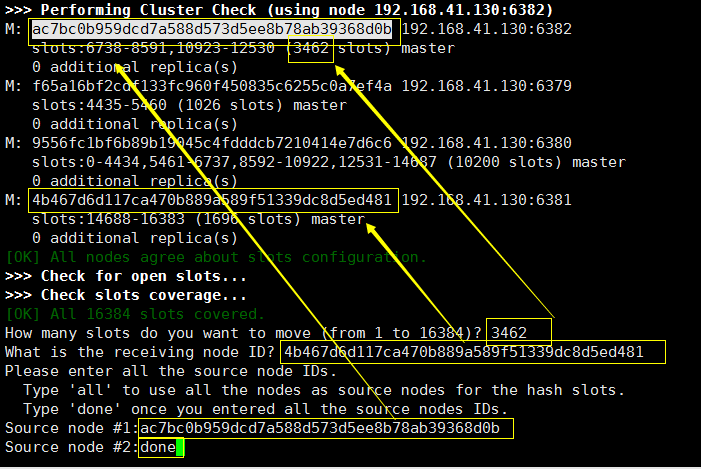
然后我们观察集群的相关信息: 6382 没有插槽点了

删除节点:./redis-trib.rb del-node 192.168.41.130:6380 ac7bc0b959dcd7a588d573d5ee8b78ab39368d0b
del-onde ip :port node_id
查看集群节点信息:发现6382节点已经被我们删除了

集群到这里就结束了,但是离我们的高并发和高可用还有一截路,下面我们来说说:
1、 集群中的每个节点都会定期的向其它节点发送PING命令,并且通过有没有收到回复判断目标节点是否下线;
2、 集群中每一秒就会随机选择5个节点,然后选择其中最久没有响应的节点放PING命令;
3、 如果一定时间内目标节点都没有响应,那么该节点就认为目标节点疑似下线;
4、 当集群中的节点超过半数认为该目标节点疑似下线,那么该节点就会被标记为下线(fail);
5、 当集群中的任何一个节点下线,就会导致插槽区有空档,不完整,那么该集群将不可用;
6、 如何解决上述问题?
a) 在Redis集群中可以使用主从模式实现某一个节点的高可用
b) 当该节点(master)宕机后,集群会将该节点的从数据库(slave)转变为(master)继续完成集群服务;
下面引出 “集群下的主从复制”,三台master搭建集群,分别为每一台master 做一个主从架构,6台服务
6379,6380,6381 为主 ,搭建集群
6382,6383,6384 为从,大家主从

2019年4月17日 00:13:51 先休息了,明天补完....
开始搭建集群架构:
./redis-trib.rb create --replicas 192.168.41.130:6379 192.168.41.130:6380 192.168.41.130:6381 192.168.41.130:6382 192.168.41.130:6383 192.168.41.130:6384
1:代表从库数量为1
前三个 IP port : 依次为构建集群的三台机器的 IP port
后三个 IP port : 依次为为前面机器搭建主从的机器的 IP port
然后我就报错了,如下所示:

这个问题来自于:你重新建立集群,但是你的 rdb持久化文件 以及 node-xxx.conf 没有删除干净,
如果还不行,登录后刷一下数据 : flushdb
再次执行搭建主从集群:

查看集群信息 : cluster nodes
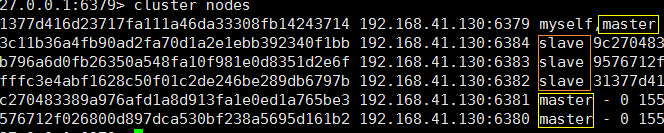
接下来用数据说话:

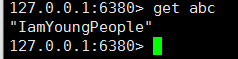
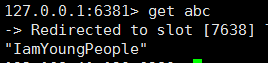
运行一切正常,下面可是测试 该环境下的高可用性:
如果从库宕机 (6384),看效果:

我们再次获取数据,观察集群是否可用:
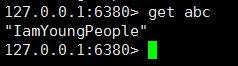
我们重启挂掉的从库机器: 自动加入集群中的主从架构
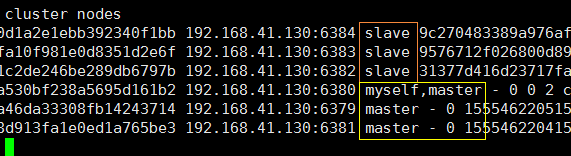
下面我们测试 主库宕机(6380),观察变化:
连接被拒绝 ???

我换一个机器试试:因为6380端口机器被挂掉了,我刚刚实在6380键入命令,所以失效
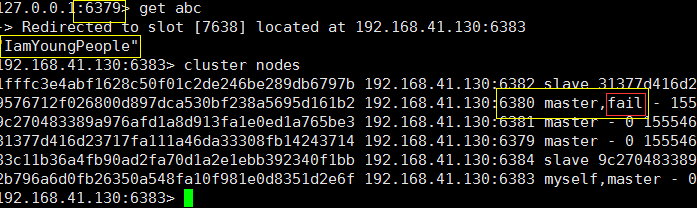
上面可以看出,6380 (Master)是 fail 状态,但是我们依旧能够获取到数据,集群可用;
你再看看 是不是除了 6380 宕机的Master 外,好像 6383 也是Master 了?
因为Master (6380 ) 对应的 从库就是 Slave (6383),当主库挂掉后,提升从库为主库,继续对外提供服务,
下面,我们重启挂掉的 6380,看看它是否会造反?


可以看出 6380,在经过一番宕机重启后,已经变为6383的从库,继续加入集群保持主从架构;
集群到这里也说完了,下面说说 在这个过程中常用的命令:
redis-server ./xxx/redis.conf : 以配置文件启动 redis 服务
redis-cli -p 6379 : 启动 redis 客户端,连接6379 服务
redis-cli -p 6379 -c : 启动 redis 客户端,连接在集群中的 6379 服务
info plication : 查看当前节点的信息,角色? 主库与从库相关信息
cluster nodes : 在集群环境某个节点中使用,查看当前集群的机器信息
slaveof <master Ip><Master Port> : 暂时建立主从关系,在配置文件可长久配置 (生产环境都是长久配置)
./redis-trib.rb create --replicas 0 <ip:port> <ip:port> <ip:port> :创建集群 从库为0
./redis-trib.rb create --replicas 1 <ip:port> <ip:port> <ip:port> <ip:port> <ip:port> <ip:port> :集群+主从
./redis-trib.rb add-node <new-node_IP :port> <集群服务机器_ip:port> : 为集群添加 节点
./redis-trib.rb del-node <ip : port> node_id : 集群下删除某个节点,需要吧插槽拨出去
kill -9 server_id : 杀死 Server_id 的服务进程
ps auxf|grep redis |grep -v grep|xargs kill -9 : 杀死所有与 redis 相关的进程服务
基本上就是这些了吧,终于快写完了!!!
使用集群注意:
多键的命令操作(如MGET、MSET),如果每个键都位于同一个节点,则可以正常支持,否则会提示错误。
集群中的节点只能使用0号数据库,如果执行SELECT切换数据库会提示错误。
redis主从架构,分片集群详解的更多相关文章
- redis + 主从 + 持久化 + 分片 + 集群 + spring集成
Redis是一个基于内存的数据库,其不仅读写速度快,每秒可以执行大约110000的写操作,81000的读取操作,而且其支持存储字符串,哈希结构,链表,集合丰富的数据类型.所以得到很多开发者的青睐.加之 ...
- kubernetes部署redis主从高可用集群
1.redis主从高可用集群结构 2.k8s部署有状态的服务选择 对于K8S集群有状态的服务,我们可以选择deployment和statefulset statefulset service& ...
- windows下安装redis3.2.100单机和集群详解
下载redis 下载地址:https://github.com/MicrosoftArchive/redis/releases 我下载的是3.2.100版本的Redis-x64-3.2.100.zip ...
- Redis主从哨兵和集群搭建
主从配置 哨兵配置 集群配置 1.主从: 国王和丞相,国王权力大(读写),丞相权利小(读) 2.哨兵: 国王和王子,国王死了(主服务挂掉),王子继位(从服务变主服务) 3.集群: 国王和国王,一个国王 ...
- java架构之路-(MQ专题)RocketMQ从入坑到集群详解
这次我们来说说我们的RocketMQ的安装和参数配置,先来看一下我们RocketMQ的提出和应用场景吧. 早在2009年,阿里巴巴的淘宝第一次提出了双11购物狂欢节,但是在2009年,服务器无法承受到 ...
- Hadoop(四)HDFS集群详解
前言 前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群.接下来这篇我详细的分享一下HDFS. HDFS前言: 设计思想:(分而治之)将大文件.大 ...
- adoop(四)HDFS集群详解
阅读目录(Content) 一.HDFS概述 1.1.HDFS概述 1.2.HDFS的概念和特性 1.3.HDFS的局限性 1.4.HDFS保证可靠性的措施 二.HDFS基本概念 2.1.HDFS主从 ...
- redis主从切换的集群管理
集群配置最少需要三台机器,那么我就三台虚拟机,三台虚拟机分别安装同样的redis的环境ip分别:192.168.9.17 (redis sentinel 集群监控)192.168.9.18 (redi ...
- 使用acs-engine在Azure中国区部署kubernetes集群详解
转载请注明出处:http://www.cnblogs.com/wayneiscoming/p/7649642.html 1. acs-engine简介 ACS是微软在2015年12月推出的一项基于容器 ...
随机推荐
- 解决了好几天的关于django xadmin后台增加链接并执行函数的问题
由于xadmin后台封装的完整性,想要在后台做一些改动对于新手来说还是有点困难,目前解决的第一个问题: 在admin后台增加链接,使其改变上级签收状态 如图 点击签收按钮之后,改变其状态 代码展示: ...
- 18-matlab知识点复习一
clc; clear; %% 输出 clc, clear; fprintf('%.19f', pi); fprintf('%d', 110); inf pi disp([1,3,5]) disp('a ...
- Taro-ui TabBar组件使用路由跳转
1. 安装taro-ui (此处使用cnpm) cnpm install taro-ui 2. 全局引入样式 app.scss sass :@import "~taro-ui/dist/st ...
- 2018年 js 简易控制滚动条滚动的简单方法
首先是es2015 的新api Element.scrollIntoView() // 滚动到最上方 等同于 dom.scrollIntoView(true) Element.scrollIntoVi ...
- Linux 学习笔记 4:Shell 编程
1.简单过滤器 a. pr [OPTION] [FILE] 功能:改变文件打印格式 选项 功能 -l n 设定页面长度为n行 -w n 设定页面总宽度为n个字符(不够会被砍掉) -h str 设定页眉 ...
- 1.为什么使用spring boot
最近2年spring cloud微服务比较流行,Spring Cloud基于SpringBoot,为微服务体系开发中的架构问题提供了一整套的解决方案, 本文总结一下为什么要使用Spring boot, ...
- Convolutional LSTM Network: A Machine LearningApproach for Precipitation Nowcasting
Convolutional LSTM Network: A Machine LearningApproach for Precipitation Nowcasting 这篇文章主要是了解方法. 原始文 ...
- Jquery 数组操作大全【转载】
转载于:https://www.jb51.net/article/43164.htm 1. $.each(array, [callback]) 遍历[常用] 解释: 不同于例遍 jQuery 对象的 ...
- PCL-安装
1.安装定期更新维护的PCL开发包. 通过PPA支持的Ubuntu系统,安装命令为: sudo add-apt-repository ppa:v-launched-jochen-sprickerhof ...
- 【Selenium】【BugList9】windows环境,fp = open("./"+ time.strftime("%Y-%m-%d %H:%M:%S") + " result.html",'wb'),报错:OSError: [Errno 22] Invalid argument: './2018-09-05 10:29:32 result.html'
[代码] if __name__=="__main__": suite = unittest.TestSuite() suite.addTest(Baidu("test_ ...