SQL Server 自动循环归档分区数据脚本
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/表分区
概述
在很多业务场景下我们需要对一些记录量比较大的表进行分区,同时为了保证性能需要将一些旧的数据进行归档。在分区表很多的情况下如果每一次归档都需要人工干预的话工程量是比较大的而且也容易发生纰漏。接下来分享一个自己编写的自动归档分区数据的脚本,原理是分区表和归档表使用相同的分区方案,循环利用当前的文件组。
一、创建测试数据
----01创建文件组
USE [master]
GO
ALTER DATABASE [chenmh] ADD FILEGROUP [Group1]
GO
ALTER DATABASE [chenmh] ADD FILEGROUP [Group2]
GO
ALTER DATABASE [chenmh] ADD FILEGROUP [Group3]
GO
ALTER DATABASE [chenmh] ADD FILEGROUP [Group4]
GO
USE [master]
GO
ALTER DATABASE [chenmh] ADD FILE ( NAME = N'datafile1', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\datafile1.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Group1]
GO
ALTER DATABASE [chenmh] ADD FILE ( NAME = N'datafile2', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\datafile2.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Group2]
GO
ALTER DATABASE [chenmh] ADD FILE ( NAME = N'datafile3', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\datafile3.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Group3]
GO
ALTER DATABASE [chenmh] ADD FILE ( NAME = N'datafile4', FILENAME = N'C:\Program Files\Microsoft SQL Server\MSSQL12.MSSQLSERVER\MSSQL\DATA\datafile4.ndf' , SIZE = 8192KB , FILEGROWTH = 65536KB ) TO FILEGROUP [Group4]
GO ----02创建分区函数
USE [chenmh]
GO
CREATE PARTITION FUNCTION [Pt_Range](BIGINT) AS RANGE RIGHT FOR VALUES (1000000, 2000000, 3000000)
GO ----03创建分区方案,分区方案对应的文件组数是分区函数指定的数量+1
CREATE PARTITION SCHEME Ps_Range
AS PARTITION Pt_Range
TO (Group1, Group2, Group3, Group4); ---04创建表,指定的分区列的数据类型一定要和分区函数指定的列类型一致。
CREATE TABLE [dbo].[News](
[id] [bigint] NOT NULL,
[status] [int] NULL,
CONSTRAINT [PK_News] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Ps_Range](id)
) ON [Ps_Range](id) -----创建归档分区表
CREATE TABLE [dbo].[NewsArchived](
[id] [bigint] NOT NULL,
[status] [int] NULL,
CONSTRAINT [PK_NewsArchived] PRIMARY KEY CLUSTERED
(
[id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [Ps_Range](id)
) ON [Ps_Range](id) ----插入测试数据
DECLARE @id INT
SET @id=1
WHILE @id<5001000
BEGIN
INSERT INTO News VALUES(@id,@id%2)
SET @id=@id+1 END

可以看到当前总共有4个分区,每一个分区定义的范围区间是100万,分区4我故意多插入了200多万的数据来验证自动归档分区。
二、自动归档分区脚本
CREATE PROCEDURE Pro_Partition_AutoArchiveData
(@PartitionTable VARCHAR(300),
@SwitchTable VARCHAR(300)
)
AS
BEGIN
DECLARE @FunName VARCHAR(100),@SchemaName VARCHAR(100),@MaxPartitionValue sql_variant ---根据归档表查找对应的分区方案、分区函数、最小分区数、最大分区范围值
SELECT
DISTINCT
@FunName=MAX(pf.name),
@SchemaName=MAX(ps.name),
@MaxPartitionValue=max(isnull(prv.value,0))
FROM sys.partitions p inner join sys.indexes i ON p.object_id=i.object_id and p.index_id=i.index_id
inner join sys.partition_schemes ps ON i.data_space_id=ps.data_space_id
inner join sys.destination_data_spaces dds ON ps.data_space_id=dds.partition_scheme_id and dds.destination_id=p.partition_number
inner join sys.data_spaces ds ON dds.data_space_id=ds.data_space_id
inner join sys.partition_functions pf ON ps.function_id=pf.function_id
LEFT join sys.partition_range_values prv ON pf.function_id=prv.function_id AND prv.boundary_id=p.partition_number-pf.boundary_value_on_right
LEFT join sys.partition_parameters pp ON prv.function_id=pp.function_id and prv.parameter_id=pp.parameter_id
LEFT join sys.types t ON pp.system_type_id=t.system_type_id and pp.user_type_id=t.user_type_id
WHERE OBJECT_NAME(p.OBJECT_ID)=@PartitionTable DECLARE @MaxId BIGINT,@MinId BIGINT,@Sql NVARCHAR(MAX),@GroupName VARCHAR(100),@MinPartitionNumber INT
SET @Sql= N'SELECT @MaxId=MAX(id),@MinId=Min(id) FROM '+@PartitionTable
EXEC sp_executesql @Sql,N'@MaxId BIGINT out,@MinId BIGINT out',@MaxId OUT,@MinId OUT SELECT @FunName AS FunName,@SchemaName AS SchemaName,@MaxPartitionValue AS MaxPartitionValue ,@MaxId AS MaxId,@MinId AS MinId ---判断当前表的最大的id是否已经在最大的分区中
IF @MaxId>=@MaxPartitionValue
BEGIN
----归档分区数据,根据表的最小值找到它所属的分区.
SET @Sql= N'SELECT @MinPartitionNumber=$PARTITION.'+@FunName+N'('+CONVERT(VARCHAR(30),@MinId)+N')';
EXEC sp_executesql @Sql,N'@MinPartitionNumber INT out',@MinPartitionNumber OUT
SET @Sql=N'ALTER TABLE ' +@PartitionTable+ N' SWITCH PARTITION '+CONVERT(VARCHAR(10),@MinPartitionNumber)+ N' TO ' +@SwitchTable+ N' PARTITION ' +CONVERT(VARCHAR(10),@MinPartitionNumber);
--PRINT @Sql
EXEC (@Sql)
---修改分区方案,增加新的分区对应的文件组,根据最小的分区id找到对应的文件组。
SELECT
DISTINCT
@GroupName=ds.name
FROM sys.partitions p inner join sys.indexes i ON p.object_id=i.object_id and p.index_id=i.index_id
inner join sys.partition_schemes ps ON i.data_space_id=ps.data_space_id
inner join sys.destination_data_spaces dds ON ps.data_space_id=dds.partition_scheme_id and dds.destination_id=p.partition_number
inner join sys.data_spaces ds ON dds.data_space_id=ds.data_space_id
inner join sys.partition_functions pf ON ps.function_id=pf.function_id
WHERE pf.name=@FunName AND ps.name=@SchemaName AND p.partition_number=@MinPartitionNumber
SET @Sql=N'ALTER PARTITION SCHEME '+@SchemaName+N' NEXT USED '+@GroupName
--PRINT @Sql
EXEC (@Sql)
---修改分区函数,增加新的分区,增加新的分区范围值,在现有的最大的值的基础上加100万(需要和现有的分区函数的范围保持一致)
SET @MaxPartitionValue=CONVERT(BIGINT,@MaxPartitionValue)+1000000
SET @Sql=N'ALTER PARTITION FUNCTION '+@FunName+N'('+N')'+N' SPLIT RANGE ('+CONVERT(VARCHAR(30),@MaxPartitionValue)+N')'
--PRINT @Sql
EXEC (@Sql) END END
三、自动归档分区数据
1.首次测试
EXEC Pro_Partition_AutoArchiveData 'news','NewsArchived';
注意:每调用一次归档一个最小分区的数据。


分区表的News分区1的数据被归档到了NewsArchived表中,且创建了分区5,分区5使用的是已归档的分区1的文件组,达到了循环利用文件组的效果。
2.再调用一次归档分区脚本
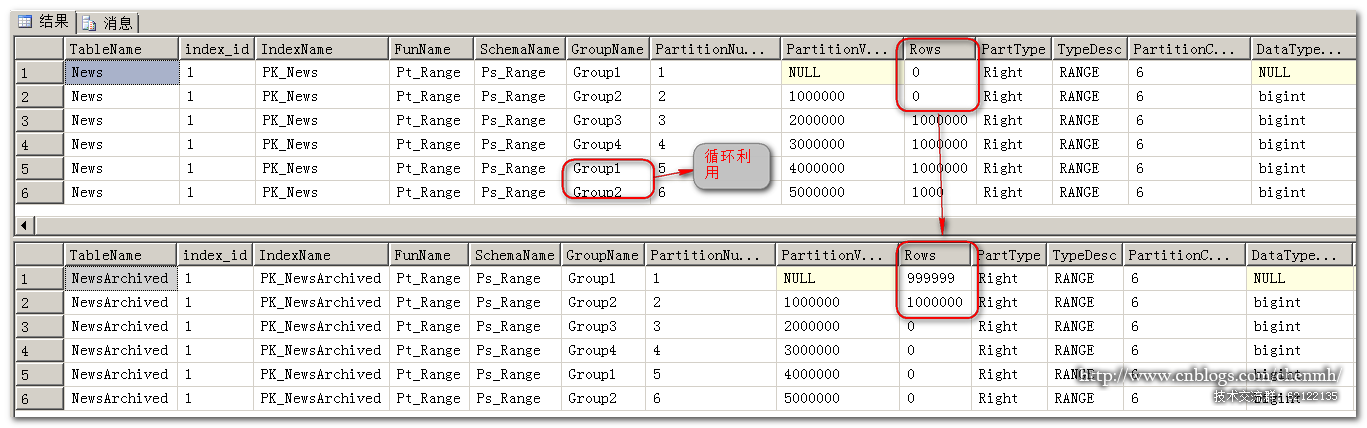
当分区表最大的id小于最大的分区值时自动归档分区脚本就不会生效。所以当前的测试表数据还可以再归档分区3的数据。
3.经过一段时间的运行归档数据可能是这样的效果

Group1→Group4→Group1→.......
四、脚本注意事项
1.@PartitionTable和@SwitchTable表必须使用同名的分区方案和分区函数,否则@SwitchTable就需要单独修改分区方案和函数,且表结构完全一致。
2.归档的表分区列数据类型必须是INT类型,且值是自增规律.
3.分区归档作业在备份作业后执行
4.建议使用Right分区,Left分区会出现有的最后一个分区文件组不会循环替换,一直处于分区的最后,比如Group1,Group2,Group3,Group1,Group2,Group3,Group1,Group4。期望的应该是Group1,Group2,Group3,Group4,Group1,Group2,Group3,Group4,Group1
5.注意我当前的每个分区大小是100万和分区函数保持一致,如果范围值不同,需要修改最末尾代码的"修改分区函数"处代码.
总结
当前自动归档分区脚本如果要拷贝去用还是得能完全理解每一段代码,根据自己的业务做适当的修改,毕竟数据是无价的!!!。最后只需要创建一个作业定期跑作业就行,重复执行也不影响。
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接,否则保留追究责任的权利。 《欢迎交流讨论》 |
SQL Server 自动循环归档分区数据脚本的更多相关文章
- SQLServer 自动循环归档分区数据脚本
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/表分区 概述 在很多业务场景下我们需要对一些记录量比较大的表进行分区,同时为了保证性能需要将一些旧的数据进行归档.在分区表很多的情 ...
- SQL SERVER 游标循环读取表数据
[cursor]游标:用于循环表行数据,类似指针 格式如下: declare tempIndex cursor for (select * from table) --定义游标 open tempIn ...
- 【Transact-SQL】SQL Server自动把left join自动转化为inner join、以及关联时的数据重复问题
原文:[Transact-SQL]SQL Server自动把left join自动转化为inner join.以及关联时的数据重复问题 1.SQL Server自动把left join自动转化为inn ...
- 清空SQL Server数据库中所有表数据的方法(转)
清空SQL Server数据库中所有表数据的方法 其实删除数据库中数据的方法并不复杂,为什么我还要多此一举呢,一是我这里介绍的是删除数据库的所有数据,因为数据之间可能形成相互约束关系,删除操作可能陷入 ...
- 清空SQL Server数据库中所有表数据的方法
原文:清空SQL Server数据库中所有表数据的方法 其实删除数据库中数据的方法并不复杂,为什么我还要多此一举呢,一是我这里介绍的是删除数据库的所有数据,因为数据之间可能形成相互约束关系,删除操作可 ...
- SQL Server内部如何管理对象的数据Page?
一个表或Index使用的数据页空间是由IAM Page Chain来管理的.SQL Server 使用一个IAM(Index Allocation Map)Page来管理数据库文件中最多4GB的空间, ...
- SQL Server 解读【已分区索引的特殊指导原则】(2)- 唯一索引分区
一.前言 在MSDN上看到一篇关于SQL Server 表分区的文档:已分区索引的特殊指导原则,如果你对表分区没有实战经验的话是比较难理解文档里面描述的意思.这里我就里面的一些概念进行讲解,方便大家的 ...
- 腾讯云图片鉴黄集成到C# SQL Server 怎么在分页获取数据的同时获取到总记录数 sqlserver 操作数据表语句模板 .NET MVC后台发送post请求 百度api查询多个地址的经纬度的问题 try{}里有一个 return 语句,那么紧跟在这个 try 后的 finally {}里的 code 会 不会被执行,什么时候被执行,在 return 前还是后? js获取某个日期
腾讯云图片鉴黄集成到C# 官方文档:https://cloud.tencent.com/document/product/641/12422 请求官方API及签名的生成代码如下: public c ...
- 使用Sql Server Management Studio 2008将数据导出到Sql文件中
最近需要将一个Sql Server 2005数据库中的数据导出,为了方便,就希望能导出成Sql文件,里面包含的数据是由Insert 语句组成的. 在Sql Server Management St ...
随机推荐
- 《Java从入门到精通》学习总结3
1. 3种构成重载的条件: 参数类型不同.参数个数不同.参数顺序不同 只有返回值类型不同并不足以区分两个方法的重载. 2. import关键字除了导入包之外,还可以导入静态成员,这是JDK 5.0以上 ...
- mysql学习--1.事务
转载自孤傲苍狼的博客:http://www.cnblogs.com/xdp-gacl/p/3984001.html 四.事务的四大特性(ACID) 4.1.原子性(Atomicity) 原子性是指事务 ...
- java常用集合浅层解析-面试必备
ArrayList 1.动态数组 2.线程不安全 3.存储空间连续 4.查询快,添加删除慢 构造方法 /** + Shared empty array instance used for defaul ...
- VNF网络性能提升解决方案及实践
VNF网络性能提升解决方案及实践 2016年7月 作者: 王智民 贡献者: 创建时间: 2016-7-20 稳定程度: 初稿 修改历史 版本 日期 修订人 说明 1.0 20 ...
- Python用HTMLTestRunner生成html测试报告
小编的主机:mac 一.引入HTMLTestRunner包 1.下载HTMLTestRunner.py,已上传到网盘,点击下载 2.将HTMLTestRunner.py复制到python安装目录的Li ...
- GarageBand mac怎么剪切音频片段? GarageBand mac使用教程
garageband mac智能控制轻松修饰声音资源库中任何乐器的音色,让你在世界各地都可以开始你的创意,让世界听到你的歌声.GarageBand mac剪切音频片段的操作小伙伴们也是需要掌握的,Ga ...
- Python脚本字符集问题
运行脚本的时候,总是报错: SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xb9 in position 0: inval ...
- 斗地主 ai的一些资料
zt https://programming.iteye.com/blog/1491470 https://blog.csdn.net/abc1234679/article/details/79458 ...
- HTTP之状态码
状态代码有三位数字组成,第一个数字定义了响应的类别,共分五种类别: 1xx:指示信息--表示请求已接收,继续处理 2xx:成功--表示请求已被成功接收.理解.接受 3xx:重定向--要完成请求必须进行 ...
- Spring-boot集成RabbitMQ踩过的坑
1.java.net.SocketException: socket closed 官方文档已经说明,新建user和guest的账户是没有远程登录的权限的 需要对登录所用账户授权 解决方法: rabb ...