数学建模:2.监督学习--分类分析- KNN最邻近分类算法
1.分类分析
分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术,建立分类模型,对于没有分类的数据进行分类的分析方法。
分类问题的应用场景:分类问题是用于将事物打上一个标签,通常结果为离散值。例如判断一副图片上的动物是一只猫还是一只狗,分类通常是建立在回归之上。
本文主要讲基本的分类方法 ----- KNN最邻近分类算法
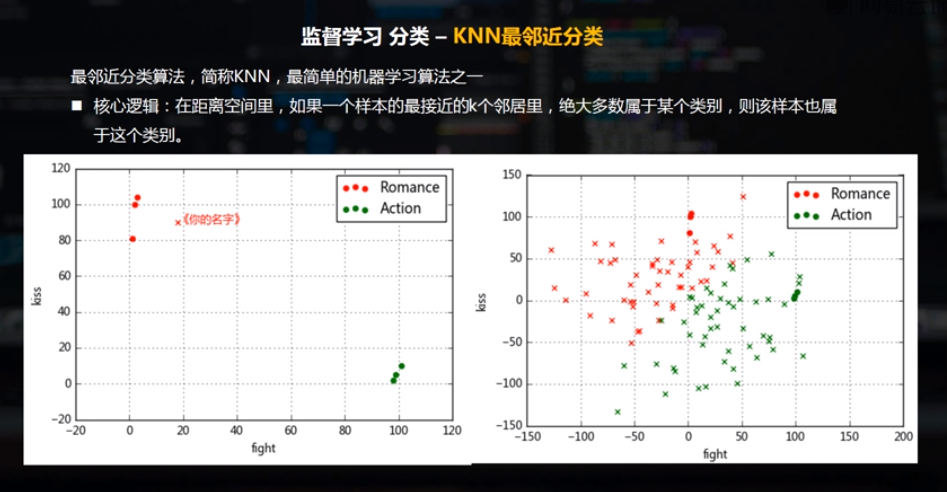
KNN最邻近分类算法 ,简称KNN,最简单的机器学习算法之一。
核心逻辑:在距离空间里,如果一个样本的最接近的K个邻居里,绝大多数属于某个类别,则该样本也属于这个类别。

2. KNN最邻近分类的python实现方法
最邻近分类的python实现方法
在距离空间里,如果一个样本的最接近的k个邻居里,绝大多数属于某个类别,则该样本也属于这个类别
电影分类 / 植物分类
2.1电影分类
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
% matplotlib inline
# 案例一:电影数据分类 from sklearn import neighbors # 导入KNN分类模块
import warnings
warnings.filterwarnings('ignore')
# 不发出警告 data = pd.DataFrame({'name':['北京遇上西雅图','喜欢你','疯狂动物城','战狼2','力王','敢死队'],
'fight':[3,2,1,101,99,98],
'kiss':[104,100,81,10,5,2],
'type':['Romance','Romance','Romance','Action','Action','Action']})
print(data)
print('-------')
# 创建数据 plt.scatter(data[data['type'] == 'Romance']['fight'], data[data['type'] == 'Romance']['kiss'], color = 'r',marker = 'o',label = 'Romance')
plt.scatter(data[data['type'] == 'Action']['fight'],data[data['type'] == 'Action']['kiss'],color = 'g',marker = 'o',label = 'Action')
plt.grid()
plt.legend()
data[data['type'] == 'Romance']['fight'] # 3 2 1
data[data['type'] == 'Romance']['kiss'] #104 100 81
knn = neighbors.KNeighborsClassifier() # 取得knn分类器
knn.fit(data[['fight','kiss']], data['type'])

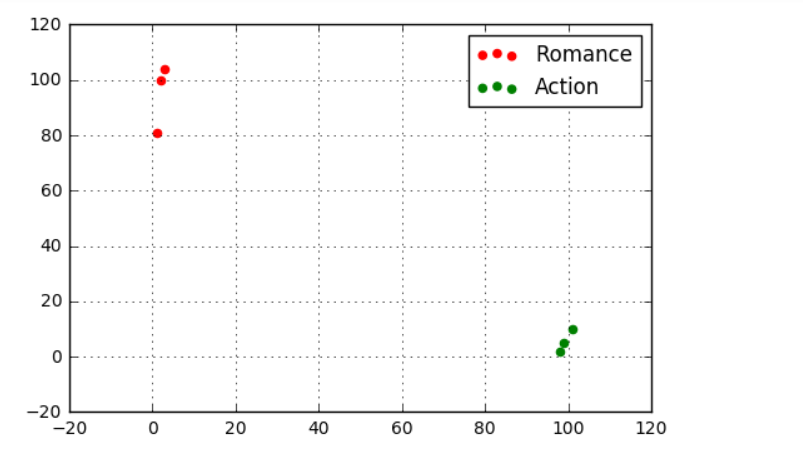
print('预测电影类型为:', knn.predict([18, 90]))
# 加载数据,构建KNN分类模型
# 预测未知数据

plt.scatter(18,90,color = 'r',marker = 'x',label = 'Romance')
plt.ylabel('kiss')
plt.xlabel('fight')
plt.text(18,90,'《你的名字》',color = 'r')
# 绘制图表

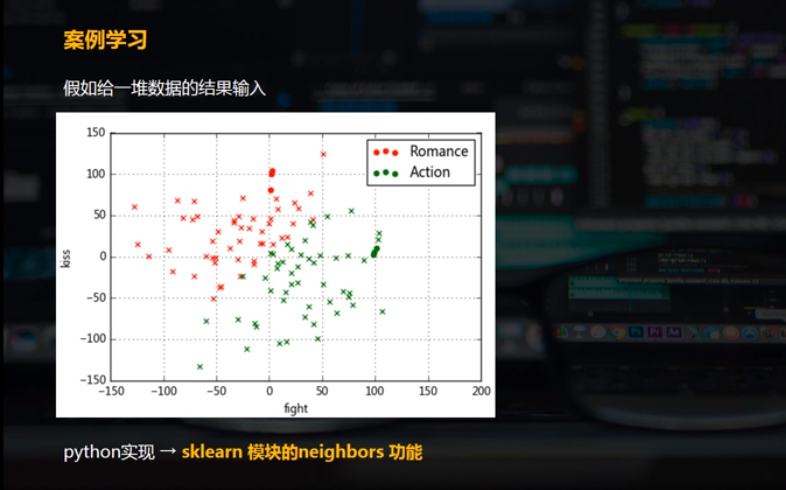
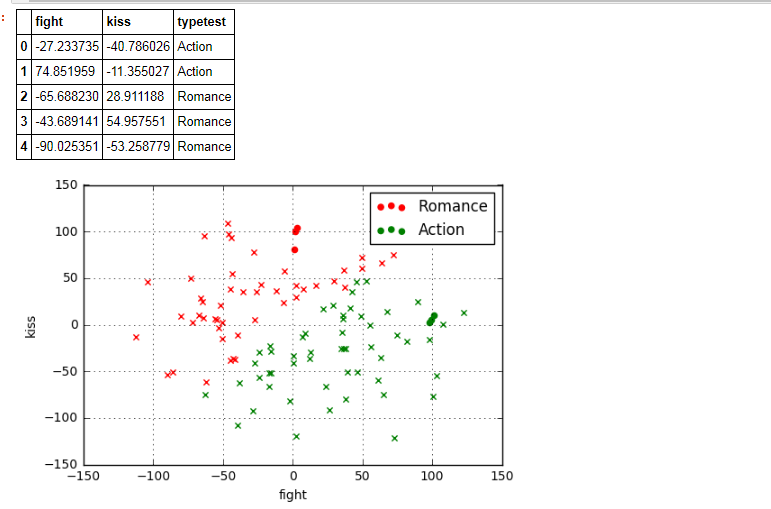
data2 = pd.DataFrame(np.random.randn(100, 2)*50, columns = ['fight', 'kiss'])
data2['typetest'] = knn.predict(data2) plt.scatter(data[data['type'] == 'Romance']['fight'],data[data['type'] == 'Romance']['kiss'],color = 'r',marker = 'o',label = 'Romance')
plt.scatter(data[data['type'] == 'Action']['fight'],data[data['type'] == 'Action']['kiss'],color = 'g',marker = 'o',label = 'Action')
plt.grid()
plt.legend() #做一个可视化
plt.scatter(data2[data2['typetest'] == 'Romance']['fight'],data2[data2['typetest'] == 'Romance']['kiss'],color = 'r',marker = 'x',label = 'Romance')
plt.scatter(data2[data2['typetest'] == 'Action']['fight'],data2[data2['typetest'] == 'Action']['kiss'],color = 'g',marker = 'x',label = 'Action')
# plt.legend()
plt.ylabel('kiss')
plt.xlabel('fight')
# 绘制图表
data2.head()
2.2植物分类
# 案例二:植物分类 from sklearn import datasets
iris = datasets.load_iris()
print(iris.keys())
print('数据长度为:%i条' % len(iris['data']))
# 导入数据 print(iris.feature_names)
print(iris.target_names)
#print(iris.target)
print(iris.data[:5])
# 150个实例数据
# feature_names - 特征分类:萼片长度,萼片宽度,花瓣长度,花瓣宽度 → sepal length, sepal width, petal length, petal width
# 目标类别:Iris setosa, Iris versicolor, Iris virginica.
data = pd.DataFrame(iris.data, columns = iris.feature_names)
data['target'] = iris.target
iris.target
data.head()

knn = neighbors.KNeighborsClassifier()
knn.fit(iris.data, iris.target) #构建一个分类模型 prt_data = knn.predict([0.2, 0.1, 0.3, 0.4]) #array([0])
prt_data
ty = pd.DataFrame({'target':[0, 1, 2],
'target_names':iris.target_names})
iris.target
df = pd.merge(data, ty, on = 'target')
df.head()

knn = neighbors.KNeighborsClassifier()
# knn.fit(iris.data, iris.target) #构建一个分类模型
knn.fit(iris.data, df['target_names']) #监督学习一定要有它的特征量和目标值
prt_data = knn.predict([0.2, 0.1, 0.3, 0.4]) #做预测
prt_data

数学建模:2.监督学习--分类分析- KNN最邻近分类算法的更多相关文章
- 监督学习-KNN最邻近分类算法
分类(Classification)指的是从数据中选出已经分好类的训练集,在该训练集上运用数据挖掘分类的技术建立分类模型,从而对没有分类的数据进行分类的分析方法. 分类问题的应用场景:用于将事物打上一 ...
- 【数学建模】day10-主成分分析
0. 关于主成分分析的详细理解以及理论推导,这篇blog中讲的很清楚. 主成分分析是一种常用手段.这应该与因子分析等区别开来,重点在于理解主成分分析的作用以及什么情况下使用主成分分析,本文重点讲解如何 ...
- 【数学建模】day09-聚类分析
0. 多元分析之聚类分析. 聚类分析是一种定量方法,从数据的角度,对样本或指标进行分类,进而进行更好的分析. 分为Q型聚类和R型聚类. 1. Q型聚类分析是对样本进行分类.有若干样本,我们把这些样本分 ...
- 数学建模:1.概述& 监督学习--回归分析模型
数学建模概述 监督学习-回归分析(线性回归) 监督学习-分类分析(KNN最邻近分类) 非监督学习-聚类(PCA主成分分析& K-means聚类) 随机算法-蒙特卡洛算法 1.回归分析 在统计学 ...
- BITED数学建模七日谈之四:数学模型分类浅谈
本文进入到数学建模七日谈第四天:数学模型分类浅谈 大家常常问道,数学模型到底有哪些,分别该怎么学习,这样能让我们的学习有的放矢,而不至于没了方向.我想告诉大家,现实生活中的问题有哪些类,数学模型就有哪 ...
- MATLAB之数学建模:深圳市生活垃圾处理社会总成本分析
MATLAB之数学建模:深圳市生活垃圾处理社会总成本分析 注:MATLAB版本--2016a,作图分析部分见<MATLAB之折线图.柱状图.饼图以及常用绘图技巧> 一.现状模式下的模型 % ...
- Python小白的数学建模课-A1.国赛赛题类型分析
分析赛题类型,才能有的放矢. 评论区留下邮箱地址,送你国奖论文分析 『Python小白的数学建模课 @ Youcans』 带你从数模小白成为国赛达人. 1. 数模竞赛国赛 A题类型分析 年份 题目 要 ...
- 2020华为杯数学建模B题-RON建模 赛后总结与分析
好久好久没有写博客了...挺累的,从二月份开始找暑期实习,接着在进行暑期实习,然后马不停蹄地进行秋招,现在总算结束实习,前两天又参加了华为杯数学建模竞赛,感觉接下来就会很轻松了,希望能好好休息休息.这 ...
- “GANs”与“ODEs”:数学建模的终结?
在本文中,我想将经典数学建模和机器学习之间建立联系,它们以完全不同的方式模拟身边的对象和过程.虽然数学家基于他们的专业知识和对世界的理解来创建模型,而机器学习算法以某种隐蔽的不完全理解的方式描述世界, ...
随机推荐
- Android调试adb devices找不到设备【转】
adb驱动已经安装成功,但是adb devices却无法找到设备,USB大容量存储也是正常: 以前如果出现此种情况,我能想到的原因如下: 1.杀毒软件问题(关闭MacAfee) 2.驱动安装有误,重新 ...
- Go数组和切片定义和初始化
1 前言 切片是动态数组,数组数组是按值赋值,切片是按地址赋值(引用) 2 代码 2.1 数组初始化 func basic_array(){ //var arr2 = [3]int{2,4,6} // ...
- 解决layui选中项下一页清空问题
项目中遇到给用户在所有产品中匹配一部分产品.用layui 第一页选好之后到第二页再选,等回到第一页时之前选择的都没了,解决这个问题的办法如下: //勾选的产品id集合 var chooseAdids ...
- linq基本操作
一.Linq有两种语法: 1. 方法语法 2. 查询语法 下面举个例子看看这两种方法的区别 比如现在有一个学生类 public class student { public string user ...
- FTP服务器配置和管理
一:ftp 简介 1:ftp服务: internet 是一个非常复杂额计算机环境,其中有pc/mac/小型机/大型机等.而在这些计算机上运行的操作系统也是五花八门,有 unix.Linux.微软的wi ...
- Confluence 6 隐藏人员目录
人员目录提供了你 Confluence 中所有用户的列表. 如果你希望禁用人员目录,请在你应用程序命令行中的 Configuring System Properties 进行设置. 希望为匿名用户禁用 ...
- 初识ActiveMQ
消息中间件的初步认识 什么是消息中间件? 消息中间件是利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成.通过提供消息传递和消息排队模型,可以在分布式架构下扩展进程 ...
- PHP编译安装时常见错误解决办法
转载自:http://www.bkjia.com/PHPjc/1008013.html This article is post on https://coderwall.com/p/ggmpfa c ...
- 制作linux下的.run安装包
前言 之前往linux上安装一个软件,都是以压缩包或者压缩包+shell的方法,这每次安装,都是先scp到某个目录, 解压,安装......稍微厉害的,会写个shell脚本.但是还是达不到真正的快速方 ...
- swagger2常用注解说明
说明: 1.这里使用的版本:springfox-swagger2(2.4)springfox-swagger-ui (2.4) 2.这里是说明常用注解的含义和基本用法(也就是说已经对swagger进行 ...