SQLServer 常见高CPU利用率原因
1.缺失索引:
USE AdventureWorks2014
SET STATISTICS TIME ON;
SET STATISTICS IO ON ;
SELECT per.FirstName,per.LastName,p.Name,p.ProductNumber,soh.OrderDate,sod.LineTotal,soh.TotalDue
FROM sales.SalesOrderHeader AS soh
INNER JOIN sales.SalesOrderDetail sod ON soh.SalesOrderID=sod.SalesOrderID
INNER JOIN Production.Product AS p ON sod.ProductID=p.ProductID
INNER JOIN sales.Customer AS c ON soh.CustomerID=c.CustomerID
INNER JOIN Person.Person AS per ON c.PersonID=per.BusinessEntityID
WHERE sod.LineTotal>25000 SET STATISTICS IO OFF;
SET STATISTICS TIME OFF;
得到下面的信息:
SQL Server 执行时间:
CPU 时间 = 63 毫秒,占用时间 = 378 毫秒。
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
--创建一个索引
CREATE NONCLUSTERED INDEX idx_SalesOrderDetail_LineTotal ON sales.SalesOrderDetail(LineTotal)
索引后结果如下:
SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 SQL Server 执行时间:
CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
2.统计信息过时
你明知道返回和处理的结果集都很小,而优化器却选择了hash连接,这是就可以检查一下图形化执行计划中是否有黄色叹号,或者用文本化执行计划看看预估和实际行数的差异是否很大。如果是使用UPDATE STATISTICS语句更新统计信息,同时检查为什么统计信息过时
3.非SARG查询
如果是一个谓词(特别是Where条件中)能用到索引查找操作,就可以理解为SARG,
如果在where 条件所用到的列中使用了标量函数(YEAR、UPPER)或使用like ‘%%’这类的查询,称为非SARG查询会导致索引无效
--非SARG(聚集索引扫描)
SELECT soh.SalesOrderID,soh.OrderDate,soh.DueDate,soh.ShipDate,soh.Status,soh.SubTotal,soh.TaxAmt,soh.Freight,soh.TotalDue
FROM sales.SalesOrderHeader AS soh
INNER JOIN sales.SalesOrderDetail AS sod
ON soh.SalesOrderID=sod.SalesOrderID
WHERE CONVERT(DATE,sod.ModifiedDate)='07/01/2005'
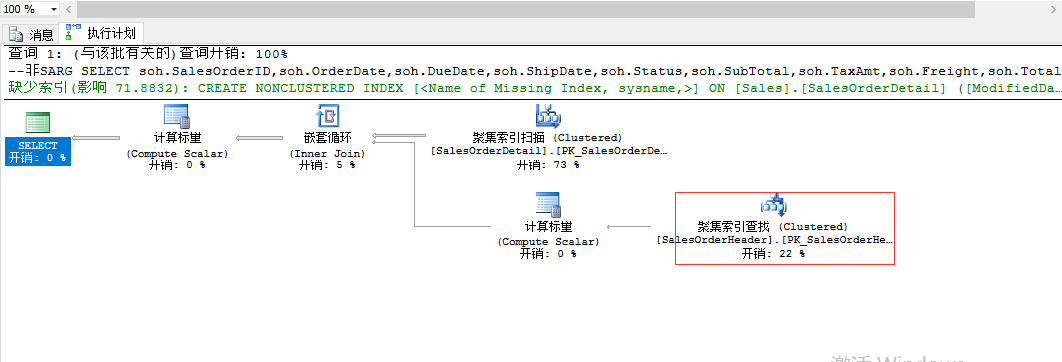
进行改写:(聚集索引查找)
SELECT soh.SalesOrderID,soh.OrderDate,soh.DueDate,soh.ShipDate,soh.Status,soh.SubTotal,soh.TaxAmt,soh.Freight,soh.TotalDue
FROM sales.SalesOrderHeader AS soh
INNER JOIN sales.SalesOrderDetail AS sod
ON soh.SalesOrderID=sod.SalesOrderID
WHERE sod.ModifiedDate>='2005-07-01 00:00:00.000'
AND sod.ModifiedDate<'2005-07-02 00:00:00.000'
非SARG对where条件中的列使用UPPER/LTRIM/ISNULL之类的标量函数,对于这种情况,改写查询解决。
4.隐式转换
指一个查询From/Where子句中,用于关联和判断列之间数据类型不同,导致优化器需要根据数据类型的优先级高低进行类型转换然后在优化、执行。
SELECT p.FirstName,p.LastName,c.AccountNumber FROM Sales.Customer AS c
INNER JOIN Person.Person AS p
ON c.PersonID =p.BusinessEntityID
WHERE c.AccountNumber=N'AW00029594'
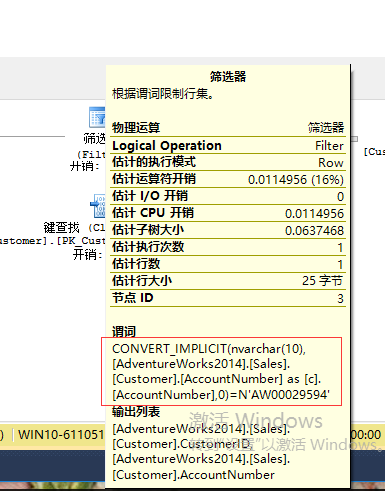
如上图加宽部分就是需要把varchar类型转换成nvarchar类型。可以考虑在传入where条件之前先进行显式数据类型转换。
5.参数嗅探
创建针对存储过程、函数或者参数化查询的执行计划时,根据传入的参数进行预估并生成执行计划的一个功能,参数嗅探出现在执行计划的编译或者重编译过程中。
CREATE PROCEDURE user_GetCustomerShipDates
(
@ShipDateStart Datetime,
@ShipDateEnd datetime
)
AS
SELECT CustomerID,SalesOrderNumber
FROM Sales.SalesOrderHeader
WHERE ShipDate BETWEEN @ShipDateStart AND @ShipDateEnd --创建非聚集索引
CREATE NONCLUSTERED INDEX IDX_ShipDate_ASC
ON Sales.SalesOrderHeader(ShipDate) --清空缓存
DBCC FREEPROCCACHE
EXEC user_GetCustomerShipDates '2005/07/08','2008/01/01'
EXEC user_GetCustomerShipDates '2005/07/10','2008/07/20' --删除索引
drop index IDX_ShipDate_ASC on Sales.SalesOrderHeader
在ShipDate上有索引,还是进行了聚集索引扫描。
在第一个存储过程的参数中,查询条件的时间范围几乎包括了全表的所有时间,另外非聚集索引没有覆盖查询,因此使用了聚集索引扫描
第二个存储过程仍然会用上面的执行计划。
把存储过程的顺序调换一下:(执行计划)
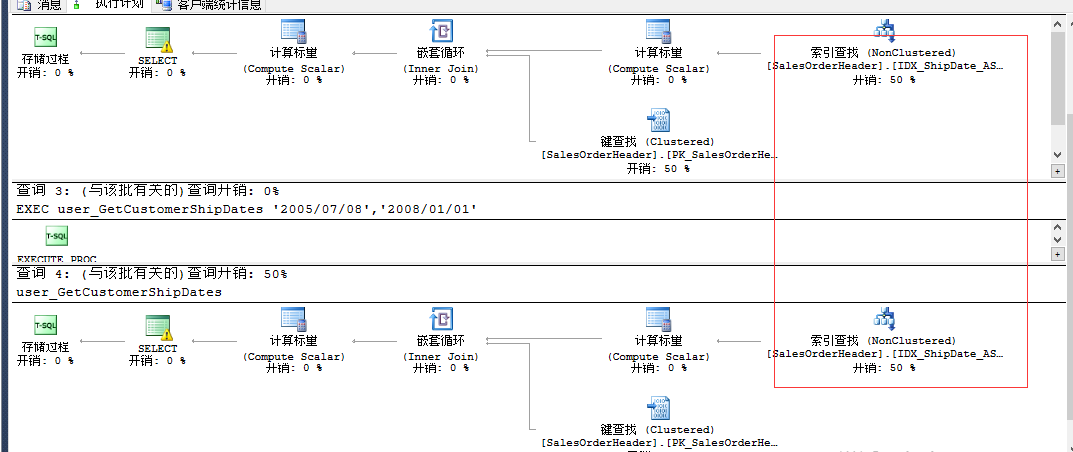
对于参数嗅探问题,可以使用部分编译、编译提示等功能来避免,更多的优化应该考虑数据和研究数据分布问题
6.--非参数化Ad—hoc查询
Ad-hoc称为即席查询,可以理解为没有使用存储过程、SP_Executesql或其他方式强制预定义SQL语句。
如:SELECT * FROM bt WHERE id=***这类查询引起的问题
可以把:高级--真对即席工作负荷进行优化:true
或者在数据库层面强制参数化:
ALTER DATABASE AdventureWorks2014 SET PARAMETERIZATION FORCED
7.非必要的并行查询
并行操作会把一个查询分开到多个线程中执行,然后在合并到一起返回结果
数据库事务:
事务是对数据库操作的单元,可以是一个Select语句,也可以是包好多个Select、Update、Delete、Insert的操作的命名集合
1.原子性:意味着一个事务内的所有操作必须全部完成或者全部回滚。
2.一致性:要求整个事务在运行的前后数据库的状态必须一致,不能打破数据定义中的一致性约束
3.隔离性:保证同一时间中,一个事务的运行不能被另一个事务影响。
4.持久性:事务一旦提交成功,将永久存储到服务器的文件系统中,即使系统在中途奔溃,所发生的的效果都不会丢失,这个会通过日志来保证。
显示事务隐式事务(区别在于创建和提交的方式)
隐式事务:由SQL Server自己去开启和提交/回滚,并且在内部保证ACID特性。
显示事务:以Begin Tran/Transaction开始以Commit Tran/Transaction 或者Rollback Tran结束
SQLServer 常见高CPU利用率原因的更多相关文章
- 排查Java高CPU占用原因
近期java应用,CPU使用率一直很高,经常达到100%,通过以下步骤完美解决,分享一下. 方法一: 转载:http://www.linuxhot.com/java-cpu-used-high.htm ...
- High CPU Usage 原因及分析
常见的高CPU利用率出现几个原因: Missing Index 统计信息过时 非SARG查询 Implicit Conversions Parameter Sniffing Non-parameter ...
- [转帖]震惊,用了这么多年的 CPU 利用率,其实是错的
震惊,用了这么多年的 CPU 利用率,其实是错的 2018年12月22日 08:43:09 Linuxer_ 阅读数:50 https://blog.csdn.net/juS3Ve/article/d ...
- CPU 利用率背后的真相,只有 1% 人知道【转】
导读:本文翻译自 Brendan Gregg 去年的一篇博客文章 “CPU Utilization is Wrong”,从标题就能想到这篇文章将会引起争议.文章一上来就说,我们“人人皆用.处处使用,每 ...
- 震惊,用了这么多年的 CPU 利用率,其实是错的
导读:本文翻译自 Brendan Gregg 去年的一片博客文章 "CPU Utilization is Wrong",从标题就能想到这篇文章将会引起争议.文章一上来就说,我们&q ...
- Linux下如何查看高CPU占用率线程 LINUX CPU利用率计算
目录(?)[-] proc文件系统 proccpuinfo文件 procstat文件 procpidstat文件 procpidtasktidstat文件 系统中有关进程cpu使用率的常用命令 ps ...
- [Oracle]Oracle数据库CPU利用率很高解决方案
Oracle数据库经常会遇到CPU利用率很高的情况,这种时候大都是数据库中存在着严重性能低下的SQL语句,这种SQL语句大大的消耗了CPU资源,导致整个系统性能低下.当然,引起严重性能低下的SQL语句 ...
- MongoDB优化之三:如何排查MongoDB CPU利用率高的问题
遇到这个问题,99.9999% 的可能性是「用户使用上不合理导致」,本文主要介绍从应用的角度如何排查 MongoDB CPU 利用率高的问题. Step1: 分析数据库正在执行的请求 用户可以通过 M ...
- MongoDB CPU利用率很高,怎么破(转)
经常有用户咨询:MongoDB CPU 利用率很高,都快跑满了,应该怎么办? 遇到这个问题,99.9999% 的可能性是「用户使用上不合理导致」,本文主要介绍从应用的角度如何排查 MongoDB CP ...
随机推荐
- linux下 gdb+coredump 调试偶发crash的程序
1. 打开 core dump 查看是否打开 ulimit -c 如果输出0, 说明没有打开. 方法一:使用命令 ulimit -c unlimited 可以打开,但是只对当前终端有效, 方法二: 配 ...
- 20165231 2017-2018-2《Java程序设计》课程总结
每周作业链接汇总 预备作业一:我期待的师生关系 预备作业二:学习基础和C语言基础调查 预备作业三:linux安装及学习 第一周作业:初识JAVA,注册码云并配置Git 第二周作业:JAVA基本语法,标 ...
- c++从文件路径获取目录
场景 c++从文件路径获取目录 实现代码 初始化是不正确的,因为需要转义反斜杠: string filename = "C:\\MyDirectory\\MyFile.bat"; ...
- JavaScript-DOM(重点)
解析过程 DOM树(一切皆是节点) DOM可以做什么 清楚DOM的结构 获取其它DOM(事件源)的三种方式 事件 事件的三要素 绑定事件的方式 JavaScript入口函数 window.onload ...
- CLR via C# 中关于装箱拆箱的摘录
装箱: 为了将一个值类型转换成一个引用类型,要使用一个名为装箱(boxing)的机制.下面总结了对值类型的一个实例进行装箱操作时在内部发生的事情. 1.在托管堆中分配好内存.分配的内存量是值类型的各 ...
- spring集成cxf实现webservice接口功能
由于cxf的web项目已经集成了Spring,所以cxf的服务类都是在spring的配置文件中完成的.以下是步骤:第一步:建立一个web项目.第二步:准备所有jar包.将cxf_home\lib项目下 ...
- 微信小程序-两个input叠加,多次点击字体变粗或闪动
问题描述: 当两个input叠加,多次点击input框, placeholder 字体变粗或input框闪动.如图: 代码: <!-- 最上层input-1 --> <input p ...
- 快速安装freeswitch
前不久在Centos 6.4上安装了一台Freeswitch,测试已经OK.为了测试FS 的集群效果,从新在安装一台FS,快速安装的过程如下: 方案一:快速安装前提:不用重新下载Freeswitch. ...
- Linux命令之useradd和userdel(添加、删除用户)
一.[useradd]:添加用户命令 1.作用 useradd或adduser命令用来建立用户帐号和创建用户的起始目录,使用权限是超级用户. 2.格式 useradd [-d home] [-s sh ...
- 本地http://localhost打不开怎么办
本地http://localhost打不开怎么办 出自:http://jingyan.baidu.com/article/c45ad29cebb95a051753e2b6.html 学过计算机的都知道 ...