excel 中怎么让两列姓名相同排序(转)
如图,A列B列不动,C列和D列行值不变,以A列姓名为主让C列姓名和A列相同姓名的对齐(行),D行跟着C行不变。
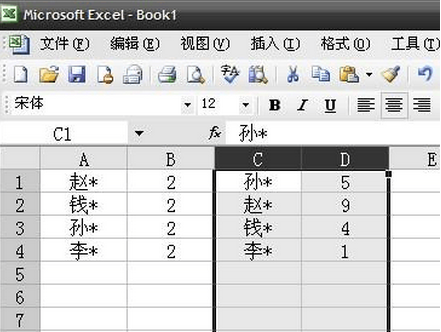
在E1输入公式=MATCH(C1,A:A,0)然后下拉,接著选中C,D,E列,以E列为标准升序排列即可
转自:https://wenku.baidu.com/view/b7f6198058fb770bf68a5559.html
pandas实现方法:
#! /usr/bin/env python
#-*- coding:utf8 -*-
import pandas as pd
from pandas import DataFrame
import numpy as np
pd.set_option('display.height',10000)
pd.set_option('display.max_rows',5000)
pd.set_option('display.max_columns',5000)
pd.set_option('display.width',10000)
df = pd.read_excel(r"F:\test.xlsx")
col_n = ['C','D']
col_A = ['A','B']
CD = pd.DataFrame(df,columns = col_n)
AB = pd.DataFrame(df,columns = col_A)
# print(CD)
# print(AB)
fi =pd.merge(AB,CD,left_on='A',right_on='C',how='left')
print(fi) zn=fi[fi.isnull().values==True]
print(zn.fillna(0))
改进版
#! /usr/bin/env python
#-*- coding:utf8 -*-
import pandas as pd
from locale import *
from pandas import DataFrame
import numpy as np
writer = pd.ExcelWriter('output.xlsx')
pd.set_option('display.height',10000)
pd.set_option('display.max_rows',5000)
pd.set_option('display.max_columns',5000)
pd.set_option('display.width',10000)
df = pd.read_excel(r"F:\test.xlsx", thousands=',')
print(df.info())
# df = pd.read_excel(r"F:\test.xlsx")
col_A = ['A','B']
col_n = ['C','D']
print(df)
AB = pd.DataFrame(df,columns = col_A)
CD = pd.DataFrame(df,columns = col_n) fi =pd.merge(AB,CD,left_on='A',right_on='C',how='left') # fi['E']=fi.apply(lambda x: (x['D'] - x['B'])/x['D']*100, axis=1).round(2) # fi['E']=fi.apply(lambda x: format((x['D'] - x['B'])/x['D'],'.2%'), axis=1) # fi['E']=(fi.D-fi.B)
# fi['F']=((fi.D-fi.B)/fi.D*100)
fi=fi.assign(E=fi.B-fi.D,F=((fi.B-fi.D)/fi.B)*100).round(2)
# fi=fi.assign(E=fi.B-fi.D,F=((fi.B-fi.D)/fi.B)) def number_to_flag(number):
if number > 0:
return '↑'
elif number == 0:
return '='
else:
return '↓' fi =fi.sort_values(by=['F'],ascending=False) #升序 fi['G'] =fi['F'].map(number_to_flag) fi['E'] = fi['E'].astype('str').str.replace("-","")
fi['F'] = fi['F'].astype('str').str.replace("-","")
fi['F'] = fi.F + '%'
fi=fi.dropna(axis=0)
fi=fi[ ~ fi['F'].str.contains('0.0') ]
fi['E'] = fi['E'].astype('float64')
print(fi)
print(fi.dtypes)
fi.to_excel(writer)
writer.save()
最终版
#! /usr/bin/env python
#-*- coding:utf8 -*-
import sys
reload(sys)
sys.setdefaultencoding('gbk')
from locale import *
from pandas import DataFrame
import pandas as pd
import numpy as np
writer = pd.ExcelWriter('output.xlsx')
pd.set_option('display.height',10000)
pd.set_option('display.max_rows',5000)
pd.set_option('display.max_columns',5000)
pd.set_option('display.width',10000)
df = pd.read_excel(r"F:\test.xlsx")
pd.options.display.float_format = '{:,}'.format print(df.info())
# df = pd.read_excel(r"F:\test.xlsx")
col_A = ['A','B']
col_n = ['C','D'] AB = pd.DataFrame(df,columns = col_A)
CD = pd.DataFrame(df,columns = col_n) fi =pd.merge(AB,CD,left_on='A',right_on='C',how='left') # fi['E']=fi.apply(lambda x: (x['D'] - x['B'])/x['D']*100, axis=1).round(2) # fi['E']=fi.apply(lambda x: format((x['D'] - x['B'])/x['D'],'.2%'), axis=1) # fi['E']=(fi.D-fi.B)
# fi['F']=((fi.D-fi.B)/fi.D*100)
fi=fi.assign(E=fi.B-fi.D,F=((fi.B-fi.D)/fi.B)*100).round(2)
# fi=fi.assign(E=fi.B-fi.D,F=((fi.B-fi.D)/fi.B)) def number_to_flag(number):
if number > 0:
return '↓'
elif number == 0:
return '='
else:
return '↑' fi =fi.sort_values(by=['F'],ascending=False) #升序 fi['G'] =fi['F'].map(number_to_flag) fi['E'] = fi['E'].astype('str').str.replace("-","")
fi['F'] = fi['F'].astype('str').str.replace("-","")
fi['F'] = fi.F + '%'
fi=fi.dropna(axis=0) fi=fi[ ~ fi['F'].str.contains('0.0') ]
fi['E'] = fi['E'].astype('float64')
fi['B'] = fi['B'].astype('float64') print(fi)
# print(fi.dtypes)
fi.to_excel(writer)
writer.save()
# fi.to_html('files.html',escape=False,index=False,sparsify=True,border=1,index_names=False,header=True)
excel 中怎么让两列姓名相同排序(转)的更多相关文章
- excel 快速比对两列数据差异
excel 快速比对两列数据差异 CreateTime--2018年5月31日11:19:35 Author:Marydon 1.情景展示 找出两列数据的差异 2.具体操作 方式一:使用条件格式 ...
- 在EXCEL中如何让一列数字变成文本格式?就是想让单元格的左上角变一个绿绿的?
如何在EXCEL中如何让一列数字变成文本格式?就是想让单元格的左上角变一个绿绿的? 解决方案:将整列单元格格式设为文本,然后,选中该列,数据--分列--完成 详细步骤: (1)选中1行或者1列,再单击 ...
- excel中快捷计算单一列中的所有的值
excel中快捷计算单一列中的所有的值 比如B列中所有的值 =SUM(B1:B100) 计算B列第一行到第100行的值 又学了一招 如果想统计B列所有的值 可以用 =SUM(B:B)
- excel中在某一列上的所有单元格的前后增加
excel中在某一列上的所有单元格的前后增加数字汉字字符等东西的函数这样写 “东西”&哪一列&“东西” 例如 “1111”&E1&“3333”
- 使用Eclipse在Excel中找出两张表中相同证件号而姓名或工号却出现不同的的项
1:首先把Excel中的文本复制到txt中,复制如下: A表: 证件号 工号 姓名 310110xxxx220130004 101 傅家宜3101 ...
- freeMarker中list的两列展示
前台界面中我使用freeMarker的机会有很多,自然也就会接触下<List>标签,我想大家应该都不陌生.<#list attrList as attr>${a.name}&l ...
- EXCELL中怎么将两列数据对比,找出相同的和不同的数据?
假设你要从B列中找出A列里没有的数据,那你就在C1单元格里输入“=IF(ISNA(VLOOKUP(B1,A:A,1,0)),"F","T")”显示T就表示有,F ...
- Excel两行交换及两列交换,快速互换相邻表格数据的方法
经常使用办公软件的人可能有遇到过需要将Excel相邻两行数据相互交换的情况,需要怎么弄才最方便呢?您还是像大家通常所做的那样先在Excel文件相应位置插入一个新的空白行然后在复制粘贴数据然后删除原来那 ...
- Excel中如何在两个工作表中查找重复数据
有时我们可能会在两种工作表中查找重复记录,当数据记录很多时,就必须通过简单的方法来实现.下面小编就与大家一起分享一下查看重复记录数据的方法,希望对大家有所帮助. 方法/步骤 为了讲解的需要,小编特 ...
随机推荐
- 20165231 预习作业3 linux安装及学习
linux安装 由于以前稍微关注过虚拟机相关知识,所以大致知道虚拟机软件的相关知识.目前我已知的普遍使用的虚拟机软件是VMware Workstation(下文简称VM),VirtualBox(下文简 ...
- 【转】python模块分析之typing(三)
[转]python模块分析之typing(三) 前言:很多人在写完代码一段时间后回过头看代码,很可能忘记了自己写的函数需要传什么参数,返回什么类型的结果,就不得不去阅读代码的具体内容,降低了阅读的速度 ...
- delphi 的插件机制与自动更新
delphi 的插件机制与自动更新 : 1.https://download.csdn.net/download/cxp_2008/2226978 参考 2.https://download.cs ...
- vue之登录和token处理
应用场景一 Vue刷新token,判断token是否过期.失效,进行登录判断跟token值存储 刷新token和token是否过期的操作都是由后端实现,前端只负责根据code的不同状态来做不同的操作: ...
- vc++基础班[27]---实现一个简单的任务管理器
因为任务管理器中涉及到进程的枚举操作,所以把两节课的知识点合并到一起来讲! ①.设计界面.以及列表控件变量的绑定: ②.列表控件样式的指定: m_TaskList.SetExtendedSty ...
- Android开发该学习哪些东西?
开篇: 本人也是众多Android开发道路上行走的一员,听了不少大神的知乎live,自己也看了不少书,也和不少前辈交流过,所以在这里分享一下Android开发应该学习的书籍以及知识,当然,也包括一些方 ...
- ifconfig相关参数及用法说明
一.ifconfig ifconfig 主要是可以手动启动.观察与修改网络接口的相关参数,可以修改的参数很多,包括 IP 参数以及 MTU 等都可以修改,它的语法如下: [root@linux ~]# ...
- Ubuntu14下nginx服务器链接PHP
报错:nginx下无法打开php,报错[error] 5040#0: *1 connect() failed (111: Connection ref ... server { listen ; #l ...
- Spring MVC的核心控制器DispatcherServlet的作用
关于Spring MVC的核心控制器DispatcherServlet的作用,以下说法错误的是( )? 它负责接收HTTP请求 加载配置文件 实现业务操作 初始化上下应用对象ApplicationC ...
- 新手-ios
最近突然让我学习一下ios,之前从未接触过(一脸蒙逼).而且我用的电脑也不是ios操作系统.上网查了下 网友说虚拟机也可以,于是本人从此举用上了ios系统. 需要的安装的工具有: 资源共享给大家: h ...