HDFS 上文件块的副本数设置
一、使用 setrep 命令来设置
# 设置 /javafx-src.zip 的文件块只存三份
hadoop fs -setrep /javafx-src.zip
二、文件块在磁盘上的路径
# 设置的 hdfs 目录为
/opt/hadoop-tmp/
# hdfs 文件块的路径为
/opt/hadoop-tmp/dfs/data/current/BP-362764591-192.168.8.136-1554970906073/current/finalized/subdir0/subdir0

三、文件的分割
文件大小 < 块设定值,文件不会被切割,直接存放到 hdfs 上,占用磁盘的空间就是文件大小
文件大小 > 块设定值,文件被切割为块大小的 N 份文件,最后一份不够块大小也上面一样,只占用本身大小的磁盘空间 下图可以看到该文件副本为 3 份,分别存放在 h140、h138 和 h136 三台机器上
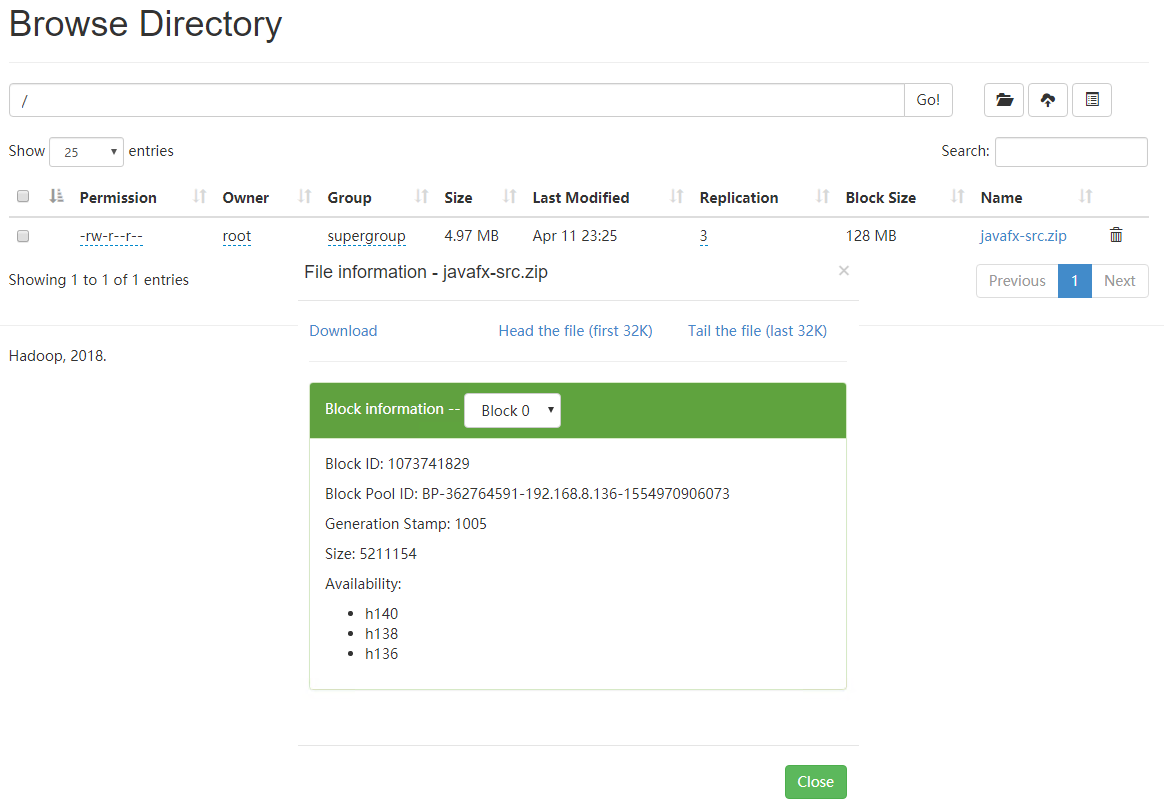
四、改变副本数后的文件的变化
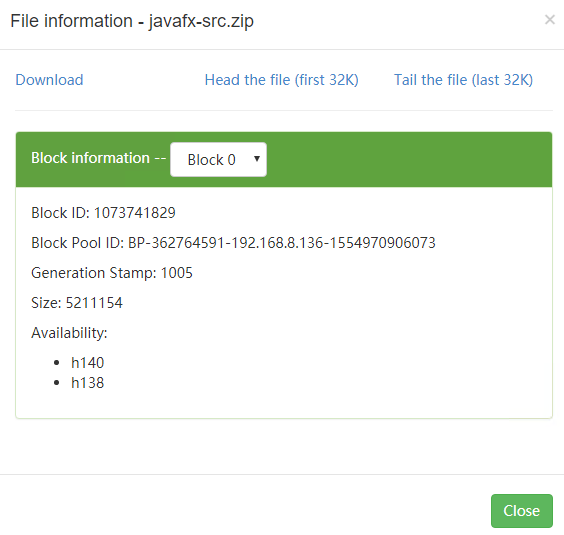
# 减少,会随机删除一个机器上的文件块,这里是删除了 h136 上的
hadoop fs -setrep 2 /javafx-src.zip
# 增加,由于只配置了三台机器无法截图
# 分两种情况:
# 机器数量 >= 副本数,会把所有文件块复制到新节点
# 机器数量 < 副本数,会等有新节点增加再执行复制操作,一直到达副本数为止
# 文件块的副本数储存在 NameNode 上
hadoop fs -setrep 5 /javafx-src.zip
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS 上文件块的副本数设置的更多相关文章
- impala删表,而hdfs上文件却还在异常处理
Impala/hive删除表,drop后,hdfs上文件却还在处理方法: 问题原因分析,如下如可以看出一个属组是hive,一个是impala,keberas账号登录hive用户无法删除impala用户 ...
- shell脚本监控Flume输出到HDFS上文件合法性
在使用flume中发现由于网络.HDFS等其它原因,使得经过Flume收集到HDFS上得日志有一些异常,表现为: 1.有未关闭的文件:以tmp(默认)结尾的文件.加入存到HDFS上得文件应该是gz压缩 ...
- MapReduce读取hdfs上文件,建立词频的倒排索引到Hbase
Hdfs上的数据文件为T0,T1,T2(无后缀): T0: What has come into being in him was life, and the life was the light o ...
- 通过spark sql 将 hdfs上文件导入到mongodb
功能:通过spark sql 将hdfs 中文件导入到mongdo 所需jar包有:mongo-spark-connector_2.11-2.1.2.jar.mongo-java-driver-3.8 ...
- SparkHiveContext和直接Spark读取hdfs上文件然后再分析效果区别
最近用spark在集群上验证一个算法的问题,数据量大概是一天P级的,使用hiveContext查询之后再调用算法进行读取效果很慢,大概需要二十多个小时,一个查询将近半个小时,代码大概如下: try: ...
- 如何修改HDFS上文件
如果只想append操作: . echo "<Text to append>" | hdfs dfs -appendToFile - yourHdfsPath/test ...
- hadoop修改MR的提交的代码程序的副本数
hadoop修改MR的提交的代码程序的副本数 Under-Replicated Blocks的数量很多,有7万多个.hadoop fsck -blocks 检查发现有很多replica missing ...
- hdfs fsck命令查看HDFS文件对应的文件块信息(Block)和位置信息(Locations)
关键字:hdfs fsck.block.locations 在HDFS中,提供了fsck命令,用于检查HDFS上文件和目录的健康状态.获取文件的block信息和位置信息等. fsck命令必须由HDFS ...
- ES的副本数量、插入大批量数据前,副本数应该设置为0
多副本可以提升检索的能力,但是如果副本数量太多,插入数据的时候容易出现卡顿现象: 因为主分片要把数据同步给所有的副本,所以建议副本数量最好是1-2个: ---- Es在索引数据的时候,如果存在副本,那 ...
随机推荐
- python字典与集合操作
字典操作 字典一种key - value 的数据类型,使用就像我们上学用的字典,通过笔划.字母来查对应页的详细内容. 语法: info = { 's1': "jack", 's3' ...
- Codeforces478D-Red-Green Towers-DP
不是特别难的一道dp题. 给r个红块,g个绿块,计算这些块能磊出的最高塔的方案数. 塔的每一层都比上一层多一块,每一层只能有一种颜色. dp[i][j]表示第i层,j个红块的方案数. 则dp[i][j ...
- ☆ [HDU2089] 不要62「数位DP」
类型:数位DP 传送门:>Here< 题意:问区间$[n,m]$的数字中,不含4以及62的数字总数 解题思路 数位DP入门题 先考虑一般的暴力做法,整个区间扫一遍,判断每个数是否合法并累计 ...
- CODEFORCES掉RATING记 #2
比赛:Codeforces Round #425 (Div. 2) 时间:2017.7.25晚 先orz zjt rank4 一场加300rating A:傻题,判断\(\lfloor\frac{n} ...
- 解决Eclipse每次修改完代码后需要先Clean,不然修改的代码无效
工具栏 Project-->Build Automatically 勾选上即可
- 【宝塔linux】 导入mysql 大文件失败的问题
导入数据库有四种方法 1.宝塔网站自带的数据库导入 2.phpmyadmin导入 3.远程到linux服务器用导入命令 使用xshell进入到控制台 1.首先建空数据库 mysql>create ...
- HDU 2604 Queuing(矩阵快速幂)
题目链接:Queuing 题意:有一支$2^L$长度的队伍,队伍中有female和male,求$2^L$长度的队伍中除 fmf 和 fff 的队列有多少. 题解:先推导递推式:$f[i]=f[i-1] ...
- 使用item pipeline处理保存数据
一个Item Pipeline 不需要继承特定基类,只需要实现某些特定方法,面向接口. class MyPipeline(object): def __init__(self): "&quo ...
- CANOE入门(三)
最好的学习方式是什么?模仿.有人会问,那不是山寨么?但是我认为,那是模仿的初级阶段,当把别人最好的设计已经融化到自己的血液里,变成自己的东西,而灵活运用的时候,才是真正高级阶段.正所谓画虎画皮难画骨. ...
- 基于Jenkins,docker实现自动化部署(持续交互)
前言 随着业务的增长,需求也开始增多,每个需求的大小,开发周期,发布时间都不一致.基于微服务的系统架构,功能的叠加,对应的服务的数量也在增加,大小功能的快速迭代,更加要求部署的快速化,智能化.因此 ...