java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
环境: Spark2.1.0 、Hadoop-2.7.5 代码运行系统:Win 7
在运行Spark程序写出文件(savaAsTextFile)的时候,我遇到了这个错误:
// :: ERROR Utils: Aborting task
java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
at org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(Native Method)
at org.apache.hadoop.util.NativeCrc32.calculateChunkedSumsByteArray(NativeCrc32.java:)
at org.apache.hadoop.util.DataChecksum.calculateChunkedSums(DataChecksum.java:)
at org.apache.hadoop.fs.FSOutputSummer.writeChecksumChunks(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSOutputSummer.flushBuffer(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSOutputSummer.flushBuffer(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSOutputSummer.write1(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSOutputSummer.write(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:)
at java.io.DataOutputStream.write(DataOutputStream.java:)
at org.apache.hadoop.mapred.TextOutputFormat$LineRecordWriter.writeObject(TextOutputFormat.java:)
at org.apache.hadoop.mapred.TextOutputFormat$LineRecordWriter.write(TextOutputFormat.java:)
at org.apache.spark.internal.io.SparkHadoopWriter.write(SparkHadoopWriter.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$$$anonfun$apply$.apply$mcV$sp(PairRDDFunctions.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$$$anonfun$apply$.apply(PairRDDFunctions.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$$$anonfun$apply$.apply(PairRDDFunctions.scala:)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$.apply(PairRDDFunctions.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$.apply(PairRDDFunctions.scala:)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:)
at org.apache.spark.scheduler.Task.run(Task.scala:)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
// :: ERROR Executor: Exception in task 0.0 in stage 11.0 (TID )
查到的还是什么window远程访问Hadoop的错误,最后查阅官方文档HADOOP-11064
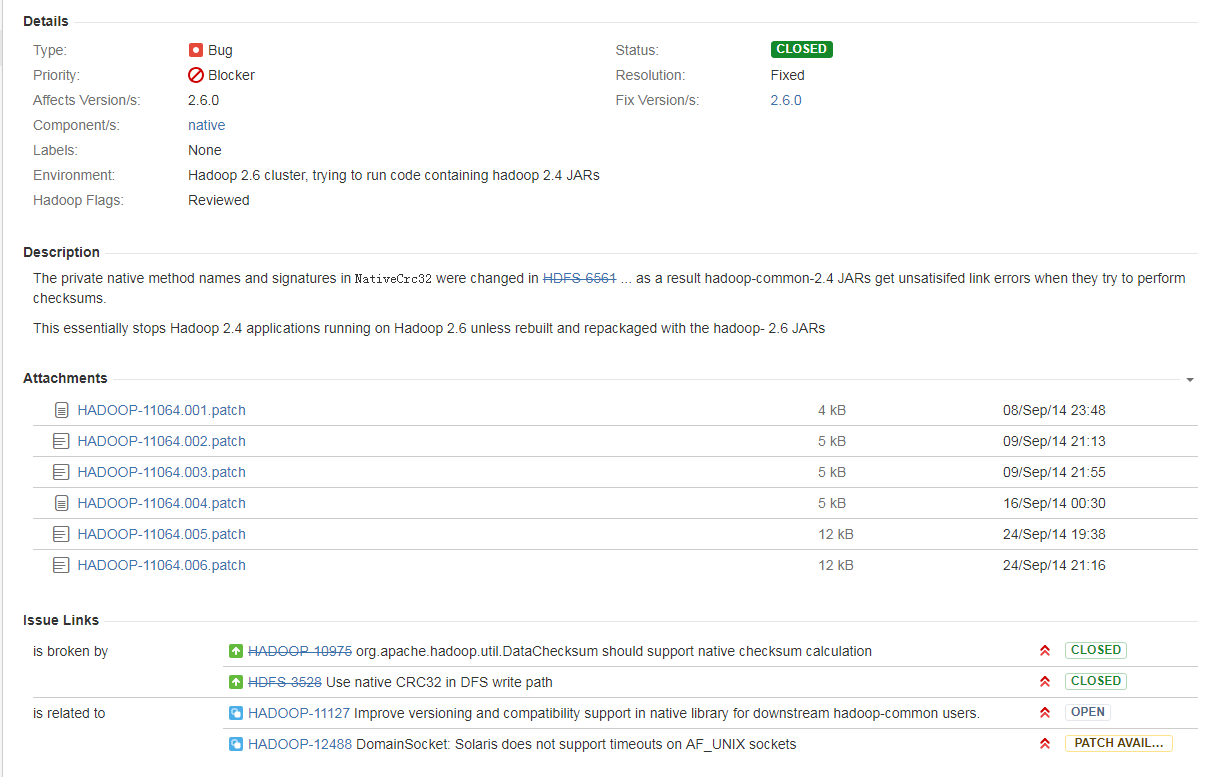
后来在网上找到解决方案是:由于hadoop.dll 版本问题出现的,这是由于hadoop.dll 版本问题,2.4之前的和之后的需要的不一样,需要选择正确的版本(包括操作系统的版本),并且在 Hadoop/bin上将其替换。
我的hadoop是2.7.5的,我之前用的是1.2的hadoop.dll,后来根据网上的说法换了hadoop.dll,找了2.6的还是不行,原来我找的2.6的是32位操作系统的,后来幸运找到了2.6的64位的hadoop.dll。
Hadoop的在windows系统中运行时需要添加win系统的支持,最开始找的版本比较老换成新的dell文件即可
java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V的更多相关文章
- Exceptionin thread "main" java.lang.UnsatisfiedLinkError:org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava
这是由于hadoop.dll 版本问题,2.4之前的和自后的需要的不一样 需要选择正确的版本并且在 Hadoop/bin和 C:\windows\system32 上将其替换
- win7上代码连接hadoop出现错误 :org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
在idea和eclipse中调试hadoop中hdfs文件,之前好好的,结果突然就出现java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.Na ...
- Exceptionin thread "main" java.lang.UnsatisfiedLinkError:org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjav
在eclipse上运行hadoop报错:Exceptionin thread "main" java.lang.UnsatisfiedLinkError:org.apache.ha ...
- [bug] Window远程连接hdfs错误:java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComput
原因 hadoop.dll 版本问题 解决 查询远程主机中hadoop版本,下载相同或稍高版本的hadoop.dll,将下载的 hadoop.dll 复制到windows系统的c:/window/sy ...
- java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
在 windows 上运行 MapReduce 时报如下异常 Exception in thread "main" java.lang.UnsatisfiedLinkError: ...
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
1.window操作系统的eclipse运行wordcount程序出现如下所示的错误: Exception in thread "main" java.lang.Unsatisfi ...
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io .nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
首先,遇到这个问题的一个原因是windows环境中没有配置hadoophome.配置之后加入winutils工具 第二个原因,pom中执行的hadoop的版本与window环境中的hadoop的版本不 ...
- MapReduce wordcount 输入路径为目录 java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;)Lorg/apache/hadoop/io/nativeio/NativeIO$POSIX$Stat;
之前windows下执行wordcount都正常,今天执行的时候指定的输入路径是文件夹,然后就报了如题的错误,把输入路径改成文件后是正常的,也就是说目前的wordcount无法对多个文件操作 报的异常 ...
- 本地spark报:java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createFileWithMode0(Ljava/lang/String;JJJI)Ljava/io/FileDescriptor;
我是在运行rdd.saveAsTextFile(fileName)的时候报的错,找了很多说法……最终是跑到hadoop/bin文件夹下删除了hadoop.dll后成功.之前某些说法甚至和这个解决方法自 ...
随机推荐
- c++ 类数据成员的定义、声明
C++为类中提供类成员的初始化列表类对象的构造顺序是这样的:1.分配内存,调用构造函数时,隐式/显示的初始化各数据成员2.进入构造函数后在构造函数中执行一般计算 1.类里面的任何成员变量在定义时是不 ...
- DM8168 PWM驱动与測试程序
昨天把DM8168的Timer设置给摸了一遍,为写PWM的底层驱动做好了准备,如今就要进入主题了. dm8168_pwm.c: #include <linux/module.h> #inc ...
- Scala 读文件
环境: Cent OS 6.3 以下说明怎样读取一个文件. 代码: $ cat fileRead.scala import scala.io.Source if (args.length > 0 ...
- 超全面的JavaWeb笔记day13<JSTL&自定义标签>
1.JSTL标签库(重点) core out set remove url if choose when otherwise forEach fmt formatDate formatNumber 2 ...
- os.path模块【python】
os.path.abspath(path) #返回绝对路径 os.path.basename(path) #返回文件名 os.path.commonprefix(list) #返回list(多个路径) ...
- SYN攻击处理
针对SYN攻击的几个环节,提出相应的处理方法: 方式1:减少SYN-ACK数据包的重发次数(默认是5次): sysctl -w net.ipv4.tcp_synack_retries=3 sysctl ...
- 新唐ARM9之NUC972学习历程之系统的搭建和BSP包的使用
说到嵌入式,我们首先想到的,就是它的复杂程度,LINUX,BSP,UBOOT,交叉编译,寄存器配置,等等一系列的问题,甚至有的时候我们对此一头雾水,很是头疼,不过我们今天要说的就是关于NUC972的一 ...
- 让你变成ASP木马高手
.名称:如何制作图片ASP木马 (可显示图片) 建一个asp文件,内容为<!--#i nclude file="ating.jpg"--> 找一个正常图片ating.j ...
- vue脚手架一
一准备: 在F:/xampp/htdocs/文件夹下检查: 1,node -v; 2,npm -v; 3,淘宝镜像(选装): npm install -g cnpm --registry= https ...
- 关于OS命令注入的闭合问题
1.在Windows下 windows下非常好办,只需要&肯定可以执行: C:\Users\xxx\Desktop>aaaa | 127.0.0.1 'aaaa' 不是内部或外部命令,也 ...