java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
环境: Spark2.1.0 、Hadoop-2.7.5 代码运行系统:Win 7
在运行Spark程序写出文件(savaAsTextFile)的时候,我遇到了这个错误:
// :: ERROR Utils: Aborting task
java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
at org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(Native Method)
at org.apache.hadoop.util.NativeCrc32.calculateChunkedSumsByteArray(NativeCrc32.java:)
at org.apache.hadoop.util.DataChecksum.calculateChunkedSums(DataChecksum.java:)
at org.apache.hadoop.fs.FSOutputSummer.writeChecksumChunks(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSOutputSummer.flushBuffer(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSOutputSummer.flushBuffer(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSOutputSummer.write1(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSOutputSummer.write(FSOutputSummer.java:)
at org.apache.hadoop.fs.FSDataOutputStream$PositionCache.write(FSDataOutputStream.java:)
at java.io.DataOutputStream.write(DataOutputStream.java:)
at org.apache.hadoop.mapred.TextOutputFormat$LineRecordWriter.writeObject(TextOutputFormat.java:)
at org.apache.hadoop.mapred.TextOutputFormat$LineRecordWriter.write(TextOutputFormat.java:)
at org.apache.spark.internal.io.SparkHadoopWriter.write(SparkHadoopWriter.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$$$anonfun$apply$.apply$mcV$sp(PairRDDFunctions.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$$$anonfun$apply$.apply(PairRDDFunctions.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$$$anonfun$apply$.apply(PairRDDFunctions.scala:)
at org.apache.spark.util.Utils$.tryWithSafeFinallyAndFailureCallbacks(Utils.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$.apply(PairRDDFunctions.scala:)
at org.apache.spark.rdd.PairRDDFunctions$$anonfun$saveAsHadoopDataset$$$anonfun$.apply(PairRDDFunctions.scala:)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:)
at org.apache.spark.scheduler.Task.run(Task.scala:)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:)
at java.lang.Thread.run(Thread.java:)
// :: ERROR Executor: Exception in task 0.0 in stage 11.0 (TID )
查到的还是什么window远程访问Hadoop的错误,最后查阅官方文档HADOOP-11064
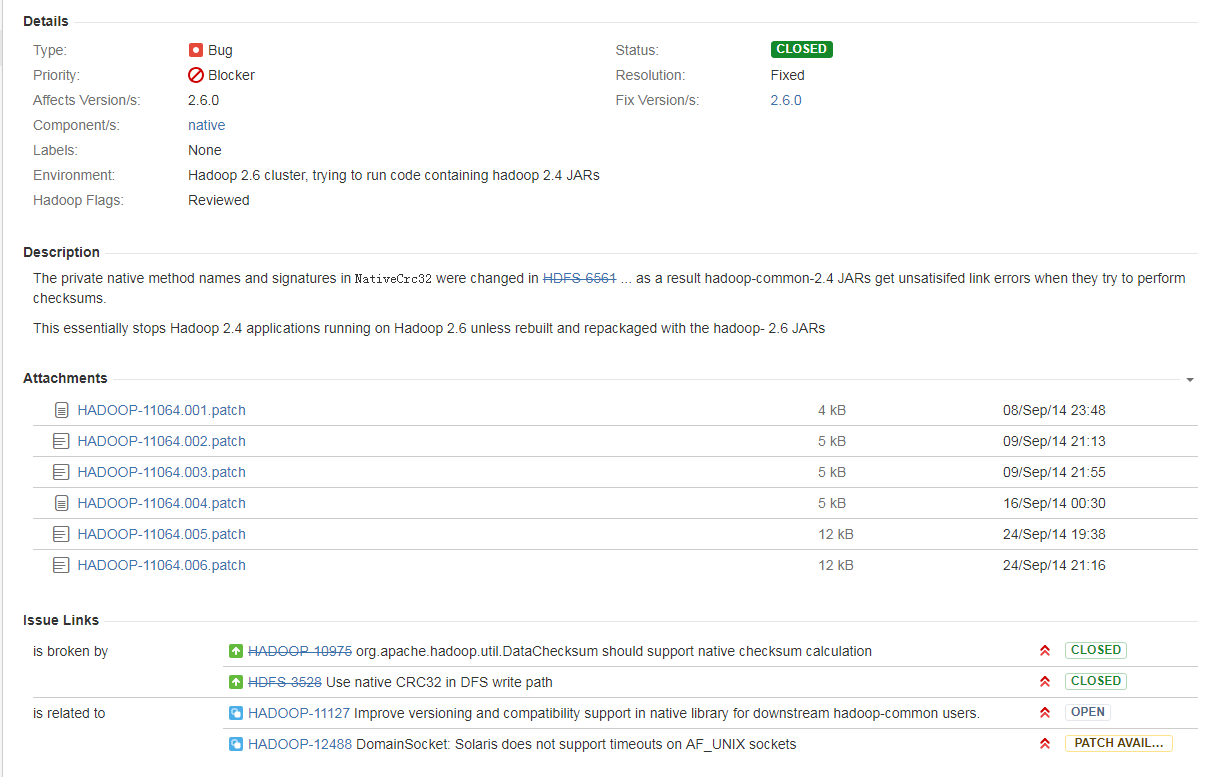
后来在网上找到解决方案是:由于hadoop.dll 版本问题出现的,这是由于hadoop.dll 版本问题,2.4之前的和之后的需要的不一样,需要选择正确的版本(包括操作系统的版本),并且在 Hadoop/bin上将其替换。
我的hadoop是2.7.5的,我之前用的是1.2的hadoop.dll,后来根据网上的说法换了hadoop.dll,找了2.6的还是不行,原来我找的2.6的是32位操作系统的,后来幸运找到了2.6的64位的hadoop.dll。
Hadoop的在windows系统中运行时需要添加win系统的支持,最开始找的版本比较老换成新的dell文件即可
java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V的更多相关文章
- Exceptionin thread "main" java.lang.UnsatisfiedLinkError:org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava
这是由于hadoop.dll 版本问题,2.4之前的和自后的需要的不一样 需要选择正确的版本并且在 Hadoop/bin和 C:\windows\system32 上将其替换
- win7上代码连接hadoop出现错误 :org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
在idea和eclipse中调试hadoop中hdfs文件,之前好好的,结果突然就出现java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.Na ...
- Exceptionin thread "main" java.lang.UnsatisfiedLinkError:org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjav
在eclipse上运行hadoop报错:Exceptionin thread "main" java.lang.UnsatisfiedLinkError:org.apache.ha ...
- [bug] Window远程连接hdfs错误:java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComput
原因 hadoop.dll 版本问题 解决 查询远程主机中hadoop版本,下载相同或稍高版本的hadoop.dll,将下载的 hadoop.dll 复制到windows系统的c:/window/sy ...
- java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
在 windows 上运行 MapReduce 时报如下异常 Exception in thread "main" java.lang.UnsatisfiedLinkError: ...
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z
1.window操作系统的eclipse运行wordcount程序出现如下所示的错误: Exception in thread "main" java.lang.Unsatisfi ...
- Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io .nativeio.NativeIO$Windows.createDirectoryWithMode0(Ljava/lang/String;I)V
首先,遇到这个问题的一个原因是windows环境中没有配置hadoophome.配置之后加入winutils工具 第二个原因,pom中执行的hadoop的版本与window环境中的hadoop的版本不 ...
- MapReduce wordcount 输入路径为目录 java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$POSIX.stat(Ljava/lang/String;)Lorg/apache/hadoop/io/nativeio/NativeIO$POSIX$Stat;
之前windows下执行wordcount都正常,今天执行的时候指定的输入路径是文件夹,然后就报了如题的错误,把输入路径改成文件后是正常的,也就是说目前的wordcount无法对多个文件操作 报的异常 ...
- 本地spark报:java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.createFileWithMode0(Ljava/lang/String;JJJI)Ljava/io/FileDescriptor;
我是在运行rdd.saveAsTextFile(fileName)的时候报的错,找了很多说法……最终是跑到hadoop/bin文件夹下删除了hadoop.dll后成功.之前某些说法甚至和这个解决方法自 ...
随机推荐
- 【spring教程之中的一个】创建一个最简单的spring样例
1.首先spring的主要思想,就是依赖注入.简单来说.就是不须要手动new对象,而这些对象由spring容器统一进行管理. 2.样例结构 如上图所看到的,採用的是mavenproject. 2.po ...
- day26<网络编程>
网络编程(网络编程概述) 网络编程(网络编程三要素之IP概述) 网络编程(网络编程三要素之端口号概述) 网络编程(网络编程三要素协议) 网络编程(Socket通信原理图解) 网络编程(UDP传输) 网 ...
- 7 -- Spring的基本用法 -- 3... Spring 的核心机制 : 依赖注入
7.3 Spring 的核心机制 : 依赖注入 Spring 框架的核心功能有两个. Spring容器作为超级大工厂,负责创建.管理所有的Java对象,这些Java对象被称为Bean. Spring容 ...
- Effective C++ Item 15 Provide access to raw resources in resource-managing classes
In last two item, I talk about resource-managing using RAII, now comes to the practical part. Often, ...
- C++11新特性之八——函数对象function
详细请看<C++ Primer plus>(第六版中文版) http://www.cnblogs.com/lvpengms/archive/2011/02/21/1960078.html ...
- Android英文文档翻译系列(1)——AlarmManager
原文:个人翻译,水平有限,欢迎看官指正. public class Ala ...
- css选择器的性能
性能排序: 1.id选择器(#myid) 2.类选择器(.myclassname) 3.标签选择器(div,h1,p) 4.相邻选择器(h1+p) 5.子选择器(ul < li) 6.后代选择器 ...
- 在Linux中的.iso文件的处理方法
1,mkdir /a 2,mount MLNX_OFED_LINUX-4.4-2.0.7.0-rhel7.3-x86_64.iso /a3,cd /a4,这样就可以对文件进行操作了
- 自定义事件类EventManager (TS中...args的使用例子)
一个自定义事件类 初衷是使用Egret的事件有两点比较麻烦 1 在事件处理函数时,需要从e中获取data hander(e:egret.Event){ let data = e.data; } 2 ...
- 【BZOJ3678】wangxz与OJ Splay
[BZOJ3678]wangxz与OJ Description 某天,wangxz神犇来到了一个信息学在线评测系统(Online Judge).由于他是一位哲♂学的神犇,所以他不打算做题.他发现这些题 ...