浅谈Storm流式处理框架
Hadoop的高吞吐,海量数据处理的能力使得人们可以方便地处理海量数据。但是,Hadoop的缺点也和它的优点同样鲜明——延迟大,响应缓慢,运维复杂。
有需求也就有创造,在Hadoop基本奠定了大数据霸主地位的时候,很多的开源项目都是以弥补Hadoop的实时性为目标而被创造出来。而在这个节骨眼上Storm横空出世了。
Storm带着流式计算的标签华丽丽滴出场了,看看它的一些卖点:
- 分布式系统:可横向拓展,现在的项目不带个分布式特性都不好意思开源。
- 运维简单:Storm的部署的确简单。虽然没有Mongodb的解压即用那么简单,但是它也就是多安装两个依赖库而已。
- 高度容错:模块都是无状态的,随时宕机重启。
- 无数据丢失:Storm创新性提出的ack消息追踪框架和复杂的事务性处理,能够满足很多级别的数据处理需求。不过,越高的数据处理需求,性能下降越严重。
- 多语言:实际上,Storm的多语言更像是临时添加上去似的。因为,你的提交部分还是要使用Java实现。
一.Storm简介
Storm是一个免费开源、分布式、高容错的实时计算系统。Storm令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求。Storm经常用于在实时分析、在线机器学习、持续计算、分布式远程调用和ETL等领域。Storm的部署管理非常简单,而且,在同类的流式计算工具,Storm的性能也是非常出众的。
Storm主要分为两种组件Nimbus和Supervisor。这两种组件都是快速失败的,没有状态。任务状态和心跳信息等都保存在Zookeeper上的,提交的代码资源都在本地机器的硬盘上。
- Nimbus负责在集群里面发送代码,分配工作给机器,并且监控状态。全局只有一个。
- Supervisor会监听分配给它那台机器的工作,根据需要启动/关闭工作进程Worker。每一个要运行Storm的机器上都要部署一个,并且,按照机器的配置设定上面分配的槽位数。
- Zookeeper是Storm重点依赖的外部资源。Nimbus和Supervisor甚至实际运行的Worker都是把心跳保存在Zookeeper上的。Nimbus也是根据Zookeerper上的心跳和任务运行状况,进行调度和任务分配的。
- Storm提交运行的程序称为Topology。
- Topology处理的最小的消息单位是一个Tuple,也就是一个任意对象的数组。
- Topology由Spout和Bolt构成。Spout是发出Tuple的结点。Bolt可以随意订阅某个Spout或者Bolt发出的Tuple。Spout和Bolt都统称为component。
下图是一个Topology设计的逻辑图的例子。
下图是Topology的提交流程图。
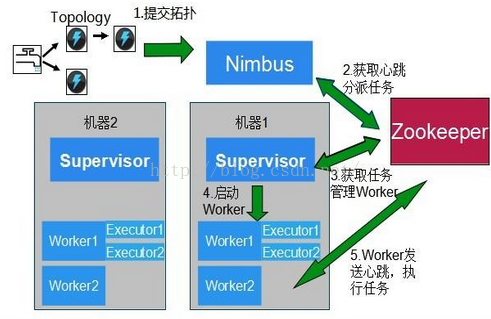
下图是Storm的数据交互图。可以看出两个模块Nimbus和Supervisor之间没有直接交互。状态都是保存在Zookeeper上。Worker之间通过ZeroMQ传送数据。

虽然,有些地方做得还是不太好,例如,底层使用的ZeroMQ不能控制内存使用(下个release版本,引入了新的消息机制使用netty代替ZeroMQ),多语言支持更多是噱头,Nimbus还不支持HA。但是,就像当年的Hadoop那样,很多公司选择它是因为它是唯一的选择。而这些先期使用者,反过来促进了Storm的发展。
二.Storm发展
Storm已经发展到0.10.0版本了,看一下两年多来,它取得的成就:
- 有50个大大小小的公司在使用Storm,相信更多的不留名的公司也在使用。这些公司中不乏淘宝,百度,Twitter,Groupon,雅虎等重量级公司。
- 从开源时候的0.5.0版本,到现在的0.10.0,和即将到来的0.10.0+。先后添加了以下重大的新特性:
- 使用kryo作为Tuple序列化的框架(0.6.0)
- 添加了Transactional topologies(事务性拓扑)的支持(0.7.0)
- 添加了Trident的支持(0.8.0)
- 引入netty作为底层消息机制(0.9.0)
Transactional topologies和Trident都是针对实际应用中遇到的重复计数问题和应用性问题的解决方案。可以看出,实际的商用给予了Storm很多良好的反馈。
- 在GitHub上超过6000个项目负责人。Storm集成了许多库,支持包括Kestrel、Kafka、JMS、Cassandra、Memcached以及更多系统。随着支持的库越来越多,Storm更容易与现有的系统协作。Storm的拥有一个活跃的社区和一群热心的贡献者。过去两年,Storm的发展是成功的。
Storm被广泛应用于实时分析,在线机器学习,持续计算、分布式远程调用等领域。来看一些实际的应用:
- 一淘-实时分析系统pora:实时分析用户的属性,并反馈给搜索引擎。最初,用户属性分析是通过每天在云梯上定时运行的MR job来完成的。为了满足实时性的要求,希望能够实时分析用户的行为日志,将最新的用户属性反馈给搜索引擎,能够为用户展现最贴近其当前需求的结果。
- 携程-网站性能监控:实时分析系统监控携程网的网站性能。利用HTML5提供的performance标准获得可用的指标,并记录日志。Storm集群实时分析日志和入库。使用DRPC聚合成报表,通过历史数据对比等判断规则,触发预警事件。
如果,业务场景中需要低延迟的响应,希望在秒级或者毫秒级完成分析、并得到响应,而且希望能够随着数据量的增大而拓展。那就可以考虑下,使用Storm了。
- 试想下,如果,一个游戏新版本上线,有一个实时分析系统,收集游戏中的数据,运营或者开发者可以在上线后几秒钟得到持续不断更新的游戏监控报告和分析结果,然后马上针对游戏的参数和平衡性进行调整。这样就能够大大缩短游戏迭代周期,加强游戏的生命力(实际上,zynga就是这么干的!虽然使用的不是Storm……Zynga研发之道探秘:用数据说话)。
- 除了低延迟,Storm的Topology灵活的编程方式和分布式协调也会给我们带来方便。用户属性分析的项目,需要处理大量的数据。使用传统的MapReduce处理是个不错的选择。但是,处理过程中有个步骤需要根据分析结果,采集网页上的数据进行下一步的处理。这对于MapReduce来说就不太适用了。但是,Storm的Topology就能完美解决这个问题。基于这个问题,我们可以画出这样一个Storm的Topology的处理图。

我们只需要实现每个分析的过程,而Storm帮我们把消息的传送和接受都完成了。更加激动人心的是,你只需要增加某个Bolt的并行度就能够解决掉某个结点上的性能瓶颈。
四.Storm的未来
在流式处理领域里,Storm的直接对手是S4。不过,S4冷淡的社区、半成品的代码,在实际商用方面输给Storm不止一条街。
如果把范围扩大到实时处理,Storm就一点都不寂寞了。
- Puma:Facebook使用puma和Hbase相结合来处理实时数据,使批处理 计算平台具备一定实时能力。 不过这不算是一个开源的产品。只是内部使用。
- HStreaming:尝试为Hadoop环境添加一个实时的组件HStreaming能让一个Hadoop平台在几天内转为一个实时系统。分商业版和免费版。也许HStreaming可以借Hadoop的东风,撼动Storm。
- Spark Streaming:作为UC Berkeley云计算software stack的一部分,Spark Streaming是建立在Spark上的应用框架,利用Spark的底层框架作为其执行基础,并在其上构建了DStream的行为抽象。利用DStream所提供的api,用户可以在数据流上实时进行count,join,aggregate等操作。
当然,Storm也有Yarn-Storm项目,能让Storm运行在Hadoop2.0的Yarn框架上,可以让Hadoop的MapReduce和Storm共享资源。
五.小结
知乎上有一个挺好的问答: 问:实时处理系统(类似s4, storm)对比直接用MQ来做好处在哪里? 答:好处是它帮你做了: 1) 集群控制。2) 任务分配。3) 任务分发 4) 监控 等等。
需要知道Storm不是一个完整的解决方案。使用Storm你需要加入消息队列做数据入口,考虑如何在流中保存状态,考虑怎样将大问题用分布式去解决。解决这些问题的成本可能比增加一个服务器的成本还高。但是,一旦下定决定使用了Storm并解决了那些恼人的细节,你就能享受到Storm给你带来的简单,可拓展等优势了。
浅谈Storm流式处理框架的更多相关文章
- 浅谈Storm流式处理框架(转)
Hadoop的高吞吐,海量数据处理的能力使得人们可以方便地处理海量数据.但是,Hadoop的缺点也和它的优点同样鲜明——延迟大,响应缓慢,运维复杂. 有需求也就有创造,在Hadoop基本奠定了大数据霸 ...
- Storm 流式计算框架
1. 简介 是一个分布式, 高容错的 实时计算框架 Storm进程常驻内存, 永久运行 Storm数据不经过磁盘, 在内存中流转, 通过网络直接发送给下游 流式处理(streaming) 与 批处理( ...
- 浅谈APP流式分页服务端设计(转)
http://www.jianshu.com/p/13941129c826 a.cursor游标式分页 select * from table where id >cursor limit pa ...
- 分布式流式处理框架:storm简介 + Storm术语解释
简介: Storm是一个免费开源.分布式.高容错的实时计算系统.它与其他大数据解决方案的不同之处在于它的处理方式.Hadoop 在本质上是一个批处理系统,数据被引入 Hadoop 文件系统 (HDFS ...
- Storm:分布式流式计算框架
Storm是一个分布式的.高容错的实时计算系统.Storm适用的场景: Storm可以用来用来处理源源不断的消息,并将处理之后的结果保存到持久化介质中. 由于Storm的处理组件都是分布式的,而且处理 ...
- 流式处理框架storm浅析(下篇)
本文来自网易云社区 作者:汪建伟 举个栗子 1 实现的目标 设计一个系统,来实现对一个文本里面的单词出现的频率进行统计. 2 设计Topology结构: 这是一个简单的例子,topology也非常简单 ...
- 流式处理框架storm浅析(上篇)
本文来自网易云社区 作者:汪建伟 前言 前一段时间参与哨兵流式监控功能设计,调研了两个可以做流式计算的框架:storm和spark streaming,我负责storm的调研工作.断断续续花了一周的时 ...
- 浅谈一下流式处理平台Flink
浅谈一下流式处理平台(Flink) 大数据框架听过很多,比如 Hadoop,HDFS...不过自己的项目都没有上过 为什么突然提到 Flink,因为最近一个项目需要用到,所以学习最好的方式就是项目驱动 ...
- 【流处理】Kafka Stream-Spark Streaming-Storm流式计算框架比较选型
Kafka Stream-Spark Streaming-Storm流式计算框架比较选型 elasticsearch-head Elasticsearch-sql client NLPchina/el ...
随机推荐
- Linux命令详解-help
help命令顾名思义就是显示帮助信息的,它是个Bash内建命令,也只是用来显示Bash内建命令的帮助信息的(Display helpful information about builtin co ...
- L192 Virgin Galactic Completes Test of Spaceship to Carry Tourists
Virgin Galactic says its spacecraft designed to launch tourists into space completed an important te ...
- timer Compliant Controller project (2)--Project Demonstration
1software flow diagram As we know, Embedded design is the core of Electronic Product Design. Di ...
- ubuntu:NVIDIA设置性能模式,以降低CPU使用、温度
NVIDIA设置性能模式,以降低CPU使用.温度 ubuntu安装完NVIDIA显卡驱动后 终端输入 nvidia-settings 选择OpenGL Settings->Image Setti ...
- C语言--第三次作业
要求一 . 1)C高级第三次PTA作业(1) 题目6-1 1.设计思路 (1)主要描述题目算法 第一步:将月份分别赋值: 第二步:利用switch语句,输 ...
- Linux 进程、线程运行在指定CPU核上
/******************************************************************************** * Linux 进程.线程运行在指定 ...
- 事务的隔离级别以及oracle中的锁
事务的概念及特性 事务,一般是指要做的或所做的事情.在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序执行单元(unit). 例如:在关系数据库中,一个事务可以是一条SQL语句,一组SQL语 ...
- 2018-2019-2 《网络对抗技术》Exp0 Kali安装 20165222
Exp0 Kali安装 安装时没进行截图,只有最终结果.包含共享文件夹,拼音输入法,网络也能正常使用. . 遇到的问题 安装时,安装程序提示找不到网卡. 我猜测应该是我的主机正在使用,程序无法检测到, ...
- POI2015题解
POI2015题解 吐槽一下为什么POI2015开始就成了破烂波兰文题目名了啊... 咕了一道3748没写打表题没什么意思,还剩\(BZOJ\)上的\(14\)道题. [BZOJ3746][POI20 ...
- Oracle基本操作命令
一.Oracle监听命令 1.启动监听 lsnrctl start 五.Oracle 查看表空间的大小及使用情况sql语句 --1.查看表空间的名称及大小 SELECT t.tablespace_na ...