Hive(一)基础知识
一、Hive的基本概念 (安装的是Apache hive 1.2.1)
1、hive简介
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表, 并提供类 SQL 查询功能, hive 底层是将 SQL 语句转换为 MapReduce 任务运行(类似于插件Pig\impala\Spark Sql)
结构化:有行有列,格式整齐标准
非结构化:格式不统一,不标准,有长有短
半结构化:参差不齐,有规律,并不是完全有规律
2、为什么使用HIVE
直接使用 Hadoop 所面临的问题:
人员学习成本太高
项目周期要求太短
MapReduce 实现复杂查询逻辑开发难度太大
为什么要使用 Hive
操作接口采用类 SQL 的语法,提供快速开发的能力
避免了写 MapReduce,减少开发人员的学习成本
功能扩展很方便
3、hive的特点
可扩展性(横向扩展)
Hive 可以自由的扩展集群的规模,而且一般情况下不需要重启服务
延展性
Hive 支持自定义函数,用户可以根据自己的需求来实现自己的函数
容错
良好的容错性,可以保障即使有节点出现问题, SQL 语句仍可完成执行
( 横向扩展:通过分担压力的方式扩展集群规模 纵向扩展:扩展线程,扩展内存等这种方式就是纵向扩展 )
4、hive架构
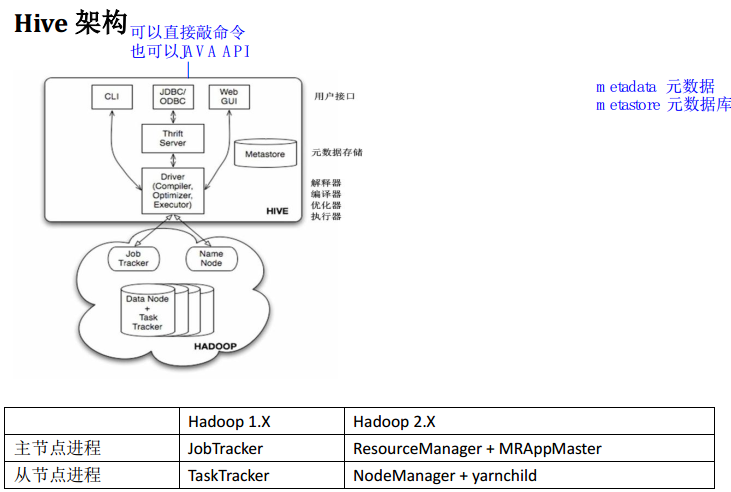
用户接口:
CLI, shell 终端命令行,最常用(学习,调试,生产)
JDBC/ODBC,是 hive 的基于 JDBC 操作提供的客户端, 用户(开发员,运维人员) 通过 这连接至 hive server
Web UI ,通过浏览器访问 hive
元数据存储:
元数据,通俗的讲, 就是存储在 Hive 中的数据的描述信息。
Hive 中的元数据通常包括:表的名字,表的列和分区及其属性,表的属性(内部表和外部表),表的数据所在目录
Metastore 默认存在自带的 Derby 数据库中。缺点就是不适合多用户操作,并且数据存 储目录不固定。数据库跟着 hive 走,极度不方便管理
解决方案:通常存我们自己创建的 MySQL 库(本地 或 远程)
解释器,编译器,优化器,执行器
这四大组件完成 HQL 查询语句从词法分析,语法分析,编译,优化,以及生成查询计 划的生成。生成的查询计划存储在 HDFS 中,并随后由 MapReduce 调用执行
执行流程:
HiveQL 通过命令行或者客户端提交,经过 Compiler 编译器,运用 Metastore 中的元数据 进行类型检测和语法分析,生成一个逻辑方案(logical plan),然后通过的优化处理,产生一 个 MapReduce 任务。
5、hive和hadoop的关系
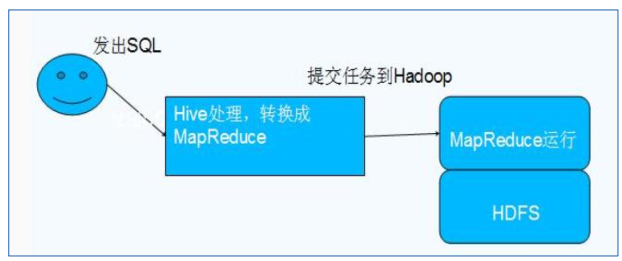
Hive 依赖于 HDFS 存储数据
Hive 将 HQL 转换成 MapReduce 执行
所以说 Hive 是基于 hadoop 的一个数据仓库工具,实质就是一款基于 HDFS 的 MapReduce 计 算框架
6、hive和RDBMS的对比
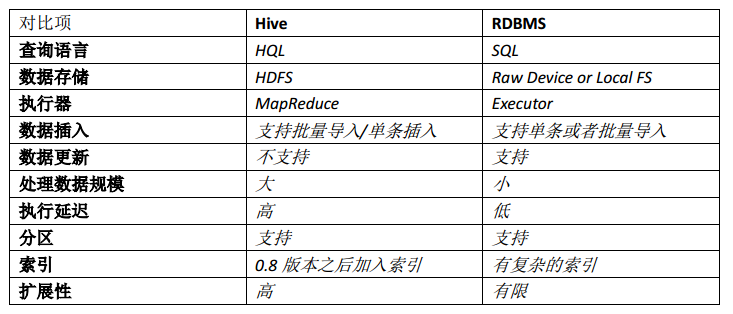
总结: hive 具有 sql 数据库的外表,但应用场景完全不同, hive 只适合用来做批量海量数据 统计分析
7、hive的数据存储
(1) Hive 中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持 Text,SequenceFile, ParquetFile, RCFILE 等)
SequenceFile 是 hadoop 中的一种文件格式:文件内容是以序列化的 kv 对象来组织的
(2) 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符, Hive 就可以解析数据
(3) Hive 中包含以下数据模型:
db:在 hdfs 中表现为${hive. metastore.warehouse.dir}目录下一个文件夹
table:在 hdfs 中表现所属 db 目录下一个文件夹
external table:与 table 类似,不过其数据存放位置可以在任意指定路径
partition:在 hdfs 中表现为 table 目录下的子目录
bucket:在 hdfs 中表现为同一个表目录下根据 hash 散列之后的多个文件
(内界表,删除时,元数据和数据都删除;外界表删除时,表中数据还在,删除的是元数据信息)
二、hive环境搭建
第一种版本:内嵌Derby版本
1、 上传安装包 apache-hive-1.2.1-bin.tar.gz
2、 解压安装包 tar –zxvf apache-hive-1.2.1-bin.tar.gz
3、 进入到 bin 目录,运行 hive 脚本: [hadoop@hadoop01 bin]$ ./hive

第二种版本:外置mysql版本
1、 安装 MySQL
2、 上传安装包 apache-hive-1.2.1-bin.tar.gz
3、 解压安装包 tar –zxvf apache-hive-1.2.1-bin.tar.gz
4、 修改配置文件
[root@hadoop01 conf]# vi hive-site.xml
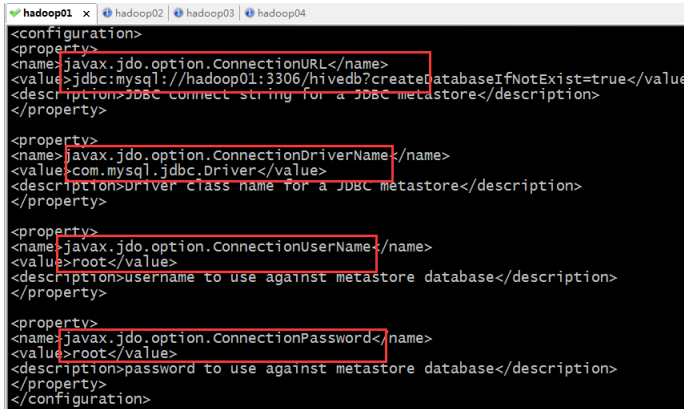
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop02:3306/hivedb?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
<description>password to use against metastore database</description>
</property>
</configuration>
5、 一定要记得加入 mysql 的驱动包( mysql-connector-java-5.1.31-bin.jar)
6、 启动 hive
三、hive使用方式,即三种连接方式
1、CLI
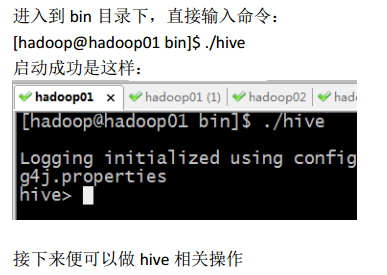
2、HiveServer2/beeline
第一种:
启动方式,(假如是在 hadoop02 上):
启动为前台: bin/hiveserver2
启动为后台: nohup bin/hiveserver2 1>/var/log/hiveserver.log 2>/var/log/hiveserver.err &
或者:nohup bin/hiveserver2 1>/dev/null 2>/dev/null &
nohup bin/hiveserver2 >/dev/null 2>&1 & (两个日志文件标准输出到同一个文件中)
1:表示标准日志输出
2:表示错误日志输出
如果我没有配置日志的输出路径,日志会生成在当前工作目录, 默认的日志名称叫做: nohup.xxx
nohup 命令:如果你正在运行一个进程,而且你觉得在退出帐户时该进程还不会结束, 那么可以使用 nohup 命令。该命令可以在你退出帐户/关闭终端之后继续运行相应的进程。
nohup 就是不挂起的意思( no hang up)。
该命令的一般形式为: nohup command &
然后启动客户端去连接:bin/beeline -u jdbc:hive2://hadoop02:10000 -n root (root为用户名)
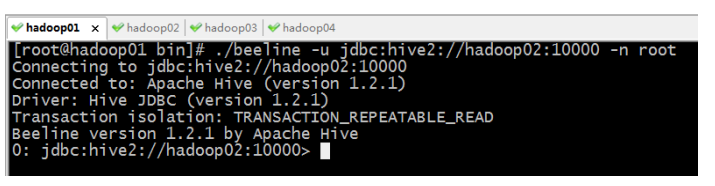
第二种:
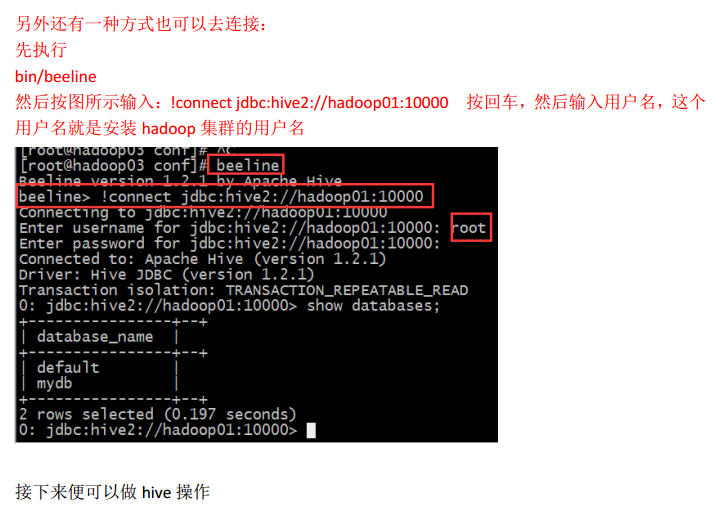
3、web UI
(1) 下载对应版本的 src 包: apache-hive-1.2.1-src.tar.gz
(2) 上传,解压
tar -zxvf apache-hive-1.2.1-src.tar.gz
(3) 然后进入目录${HIVE_SRC_HOME}/hwi/web,执行打包命令:
jar -cvf hive-hwi-1.2.1.war *
在当前目录会生成一个 hive-hwi-1.2.1.war
(4) 得到 hive-hwi-1.2.1.war 文件,复制到 hive 下的 lib 目录中。
cp hive-hwi-1.2.1.war ${HIVE_HOME}/lib
(5) 修改配置文件 hive-site.xml
<property>
<name>hive.hwi.listen.host</name>
<value>0.0.0.0</value>
<description>监听的地址</description>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>监听的端口号</description>
</property>
<property>
<name>hive.hwi.war.file</name>
<value>lib/hive-hwi-1.2.1.war</value>
<description>war 包所在的地址,注意这里不支持绝对路径,坑! </description>
</property>
(6) 复制 tools.jar
cp ${JAVA_HOME}/lib/tools.jar ${HIVE_HOME}/lib
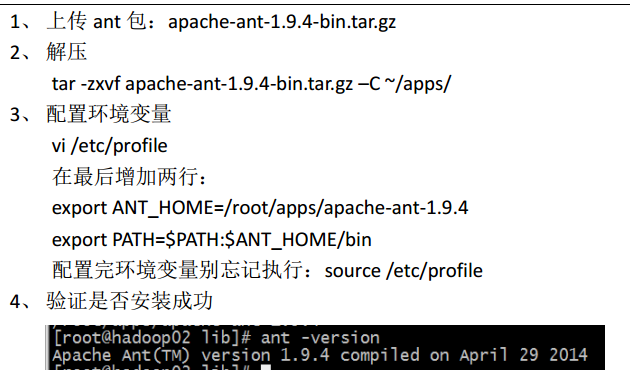
(7)安装ant
(8) 上面的步骤都配置完,基本就大功告成了。进入${HIVE_HOME}/bin 目录:
hive --service hwi
或者让在后台运行:
nohup bin/hive --service hwi > /dev/null 2> /dev/null &
(9) 前面配置了端口号为 9999,所以这里直接在浏览器中输入:
hadoop02:9999/hwi
(10)至此大功告成
四、hive的基本使用
1、 创建库: create database mydb;
2、 查看库: show databases;
3、 创建表: create table t_user(id string, name string)
或 create table t_user2 (id string, name string) row format delimited fields terminated by ',';
4、 插入数据: insert into tables t_user values (‘001’,’mazhonghua’)
5、 查询数据: select * from t_user;
6、 导入数据:
a) 导入 HDFS 数据: load data inpath '/mingxing.txt' into table t_user1;
b) 导入本地数据: load data local inpath '/root/hivedata/mingxing.txt' into table t_user1;
指定分隔 符,建表之后就不能改变,除非复制重新建表
Hive(一)基础知识的更多相关文章
- Hive 这些基础知识,你忘记了吗?
Hive 其实是一个客户端,类似于navcat.plsql 这种,不同的是Hive 是读取 HDFS 上的数据,作为离线查询使用,离线就意味着速度很慢,有可能跑一个任务需要几个小时甚至更长时间都有可能 ...
- Hive HiveQL基础知识及常用语句总结
基础语句 CREATE DROP 建表.删表 建表 -------------------------------------- -- 1. 直接建表 ------------------------ ...
- 《Programming Hive》读书笔记(两)Hive基础知识
<Programming Hive>读书笔记(两)Hive基础知识 :第一遍读是浏览.建立知识索引,由于有些知识不一定能用到,知道就好.感兴趣的部分能够多研究. 以后用的时候再具体看.并结 ...
- 大数据基础知识问答----spark篇,大数据生态圈
Spark相关知识点 1.Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduce的通用的并行计算框架 dfsSpark基于mapredu ...
- 最全的spark基础知识解答
原文:http://www.36dsj.com/archives/61155 一. Spark基础知识 1.Spark是什么? UCBerkeley AMPlab所开源的类HadoopMapReduc ...
- Hive框架基础(二)
* Hive框架基础(二) 我们继续讨论hive框架 * Hive的外部表与内部表 内部表:hive默认创建的是内部表 例如: create table table001 (name string , ...
- Hive的基本知识与操作
Hive的基本知识与操作 目录 Hive的基本知识与操作 Hive的基本概念 为什么使用Hive? Hive的特点: Hive的优缺点: Hive应用场景 Hive架构 Client Metastor ...
- .NET面试题系列[1] - .NET框架基础知识(1)
很明显,CLS是CTS的一个子集,而且是最小的子集. - 张子阳 .NET框架基础知识(1) 参考资料: http://www.tracefact.net/CLR-and-Framework/DotN ...
- RabbitMQ基础知识
RabbitMQ基础知识 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然 ...
随机推荐
- 用原生JS实现一个轮播(包含全部代码和详细思路)
在我看来要想实现轮播主要是要知道当前位于的页面和即将位于的页面.这个案例是通过改变图片的透明度来实现轮播的效果. 我把涉及的知识点分为两个方面,分别是HTML+css和JS. 第一部分(html+cs ...
- day05 字典 dict
今日内容: 字典 成对的保存数据. 以key:value的形式保存 用{}表示,每一项内容都是key:value, 每项数据之间用逗号隔开 字典中的key是不能重复的. 存储是依靠着key来计算的. ...
- 产品需求文档(PRD)的写作 【转】
产品需求文档(PRD)的写作 一.文章的摘要介绍 无论我们做什么事都讲究方式方法,写产品需求文档(以下称PRD文档)也是如此,之前我通过四篇文章分享了自己写PRD文档的一些方法,而这一篇文章主要是 ...
- Linux sync命令的作用分析
Sync命令 在用reboot命令启动unix系统后,系统提示出错信息,部分应用程序不能正常工作.经仔细检查系统文件,并和初始的正确备份进行比较,发现某些文件确实被破坏了,翻来覆去找不到文件遭破坏 ...
- hadoop HA sshfen切换隔离时无法跳转ssh: bash: fuser: 未找到命令
在zkfc的日志里面,有一个warn:PATH=$PATH:/sbin:/usr/sbin fuser -v -k -n tcp 8090 via ssh: bash: fuser: 未找到命令原因是 ...
- tcp三次握手 四次挥手 (转)
转自: http://blog.csdn.net/whuslei/article/details/6667471 建立TCP需要三次握手才能建立,而断开连接则需要四次握手.整个过程如下图所示: 先来看 ...
- CSS中水平居中设置的几种方式
1.行内元素: 如果被设置元素为文本.图片等行内元素时,水平居中是通过给父元素设置 text-align:center 来实现的. <body> <div class="t ...
- “Hello World!”团队第三周召开的第二次会议
今天是我们团队“Hello World!”团队第三周召开的第二次会议.博客内容: 一.会议时间 二.会议地点 三.会议成员 四.会议内容 五.todo list 六.会议照片 七.燃尽图 一.会议时间 ...
- 按Right-BICEP要求的对任务二的测试用例
测试方法:Right-BICEP 测试计划 1.Right-结果是否正确? 2.B-是否所有的边界条件都是正确的? 3.P-是否满足性能要求? 4.是否有乘除法? 5.是否有括号? 6.是否有真分数? ...
- HDU 1754 I Hate It 线段树(单点更新,成段查询)
题目链接: hdu: http://acm.hdu.edu.cn/showproblem.php?pid=1754 题解: 单点更新,成段查询. 代码: #include<iostream> ...