Hadoop学习笔记3---安装并运行Hadoop
本文环境是在Ubuntu10.04环境下运行的。
在Linux上安装Hadoop之前,首先安装两个程序:
1、JDK1.6(或更高版本)。Hadoop是用Java编写的程序,Hadoop编译及MapReduce的运行都需要使用JDK。因此在安装Hadoop之前,必须安装JDK1.6或更高版本。
2、SSH( Secure Shell 安全外壳协议)。SSH 为建立在应用层和传输层基础上的安全协议。SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。利用 SSH 协议可以有效防止远程管理过程中的信息泄露问题。Hadoop需要SSH来启动Slave(从机)列表中各台主机的守护进程,推荐安装OpenSSH。
(1)下载并安装JDK1.6
进入http://www.oracle.com/technetwork/java/javasebusiness/downloads/java-archive-downloads-javase6-419409.html#jdk-6u45-oth-JPR页面下载JDK1.6 linux版本(根据自己的OS选择32为或64位版本的),如 jdk-6u45-linux-i586.bin(32位)或者jdk-6u45-linux-x64.bin(64位)。
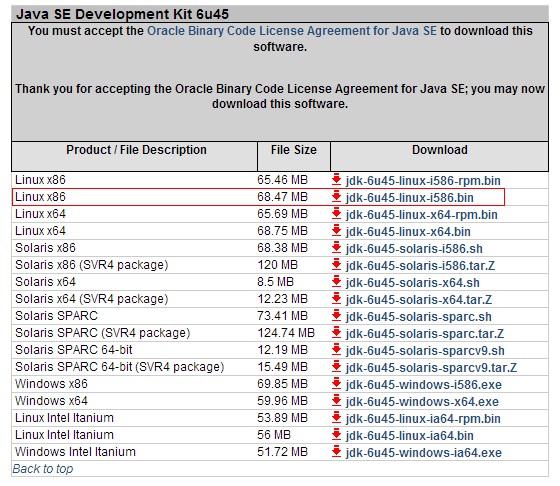
(2)安装并配置JDk环境变量
进入 jdk-6u45-linux-i586.bin的目录输入以下命令进行安装:
sudo chmod u+x jdk-6u45-linux-i586.bin //修改权限
sudo -s ./jdk-6u45-linux-i586.bin //安装
安装完毕后就可以配置环境变量了。
环境变量配置文件为/etc/profile,输入一下命令打开profile文件。在文件的末尾输入一下内容。
#set JAVA Environment
exprt JAVA_HOME=/usr/local/jdk1.6.0_45 //设置JDK的JAVA_HOME,为JDK安装的根目录
export CLASSPATH=".:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib" //设置JDK的CLASSPATH
export PATH="$JAVA_HOME/bin:$JRE_HOME/bin:$PATH" //设置JDK的PATH路径
环境变量配置好以后,系统就可以找到JDK了。
输入一下命令:java -version 会出现如下信息:

说明JDK已经安装成功。
如果没有出现上述情景,说明当前安装的JDK并未设置成Ubuntu系统默认的JDK,还要手动将安装的JDK设置成系统默认的JDK。具体操作如下:
在终端依次输入如下命令:
sudo update-alternatives --install /usr/bin/java java /usr/local/jdk1.6.0_45/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/local/jdk1.6.0_45/bin/javac 300
sudo update-alternatives --config java
接下来再次输入java -version命令 就可以看到JDK的版本信息了。
2、配置SSH免密码登陆
首先安装ssh,输入命令:
sudo apt-get install ssh
然后,输入一下命令:
ssh-keygen -t dsa -P ' ' -f ~/ .ssh/id_dsa
ssh-keygen代表生成密钥:-t表示生成指定的密钥类型;
dsa是dsa密钥认证的意思,即密钥类型:用于提供密语;-f 生成指定的密钥文件; ~/ 表示在当前用户文件夹下。
这个命令会在.ssh文件夹下创建id_dsa及id_dsa.pub两个文件,这是SSH的一对私钥和公钥,类似于钥匙和锁,把id_dsa.pub(公钥)追加到授权的key中去。
输入命令:
cat ~/ .ssh/id_dsa.pub >> ~/ .ssh/authorized_keys
这个命令时把公钥加到用于认证的公钥文件中,这里的authorized_keys是用于认证的公钥文件。到此为止,免密码登陆本机已配置完毕。
输入一下命令:
ssh -version
显示如下结果:

输入命令:
ssh localhost
会有如下显示:
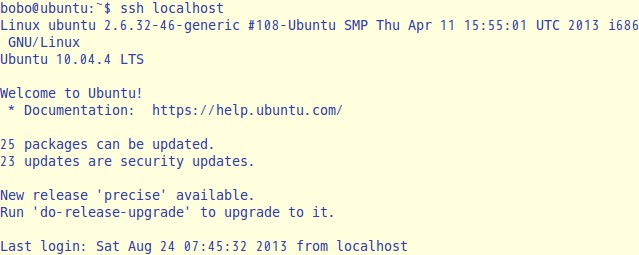
这说明已经安装成功,第一次登陆时会询问是否继续链接,输入yes即可进入。
实际上,在Hadoop的安装过程中,是否免密码登陆是无关紧要,但是如果不配置免密码登陆,每次启动Hadoop都需要输入密码以登陆到每台机器的DataNode上,考虑到一般的Hadoop集群有成败上千台机器,因此都会配置SSH的免密码登陆。
3、安装并运行Hadoop
进入Hadoop官网下载地址:http://mirrors.cnnic.cn/apache/hadoop/common/hadoop-1.2.1/,下载Hadoop最新版,并将其解压。
hadoop的配置详解请请参照上一篇笔记 http://www.cnblogs.com/bester/p/3279368.html。
进入conf文件夹,修改配置文件。
(1)hadoop-env.sh:

指定JDK的安装位置,将红圈的部分修改为:export JAVA_HOME=/usr/lib/jvm/jdk1.6.0_45 并去掉 #
(2)conf/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop_home/var</value>
</property>
</configuration>
fs.default.name:NameNode的URI。hdfs://主机名:端口/
hadoop.tmp.dir:Hadoop的默认临时路径,这个最好配置,如果在新增节点或者其他情况下莫名其妙的DataNode启动不了,就删除此文件中的tmp目录即可。
不过如果删除了NameNode机器的此目录,那么就需要重新执行NameNode格式化的命令。
(3)conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.name.dir</name> //指定name镜像文件存放目录,如不指定则默认为core-site中配置的tmp目录
<value>/bobo/Software/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.data.dir</name> //数据存放的目录,如果不写默认为core-site中配置的tmp目录
<value>/bobo/Software/hadoop/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configruation>
dfs.name.dir是NameNode持久存储名字空间及事务日志的本地文件系统路径。当这个值是一个逗号分割的目录列表时,nametable数据将会被复制到所有目录中做冗余备份。
dfs.data.dir是DataNode存放块数据的本地文件系统路径,逗号分割的列表。当这个值是逗号分割的目录列表时,数据将被存储在所有目录下,通常分布在不同设备上。
dfs.replication是数据需要备份的数量,默认是3,单机版需将此改为1,如果此数大于集群的机器数会出错。
(4)conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
mapred.job.tracker是JobTracker的主机(或者IP)和端口。主机:端口。
在启动Hadoop之前,需要格式化Hadoop的文件系统HDFS。进入Hadoop文件夹,输入命令:
bin/hadoop namenode -format //注意 namenode 必须小写 否则 会有异常出现
格式化文件系统,接下来启动Hadoop,输入命令:
bin/start-all.sh
最后验证Hadoop是否安装成功。
打开游览器,输入一下网址:
http://localhost:50070/(MapReduce的Web页面)
http://localhost:50030/(HDFS的Web页面)
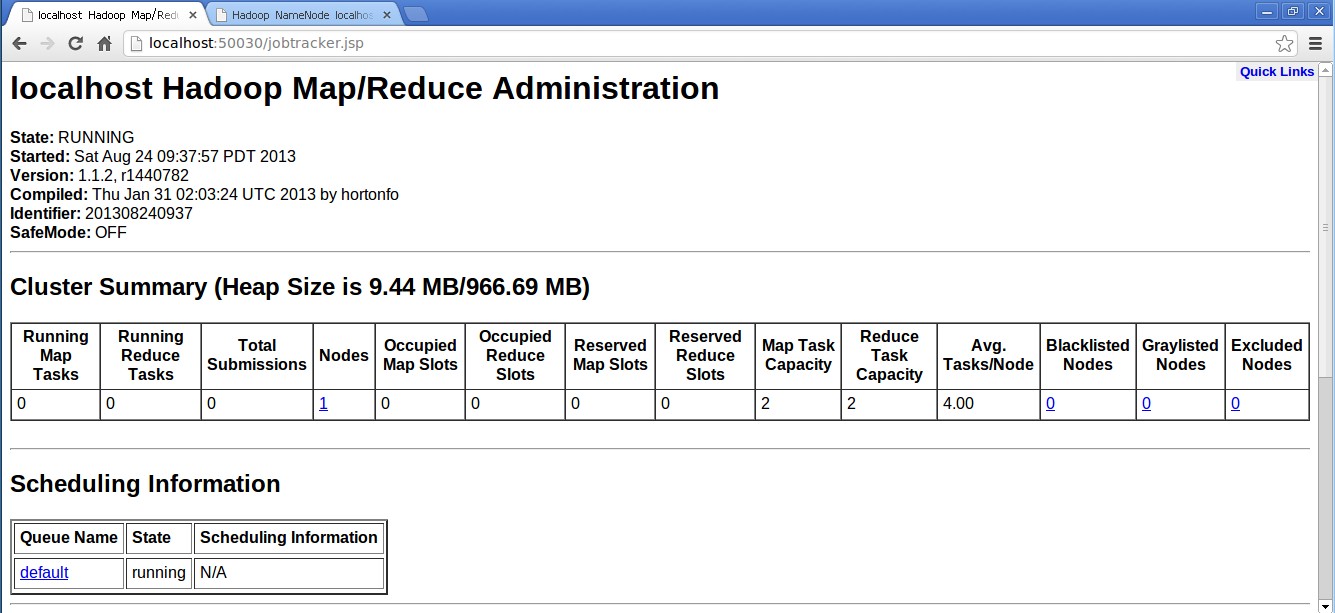
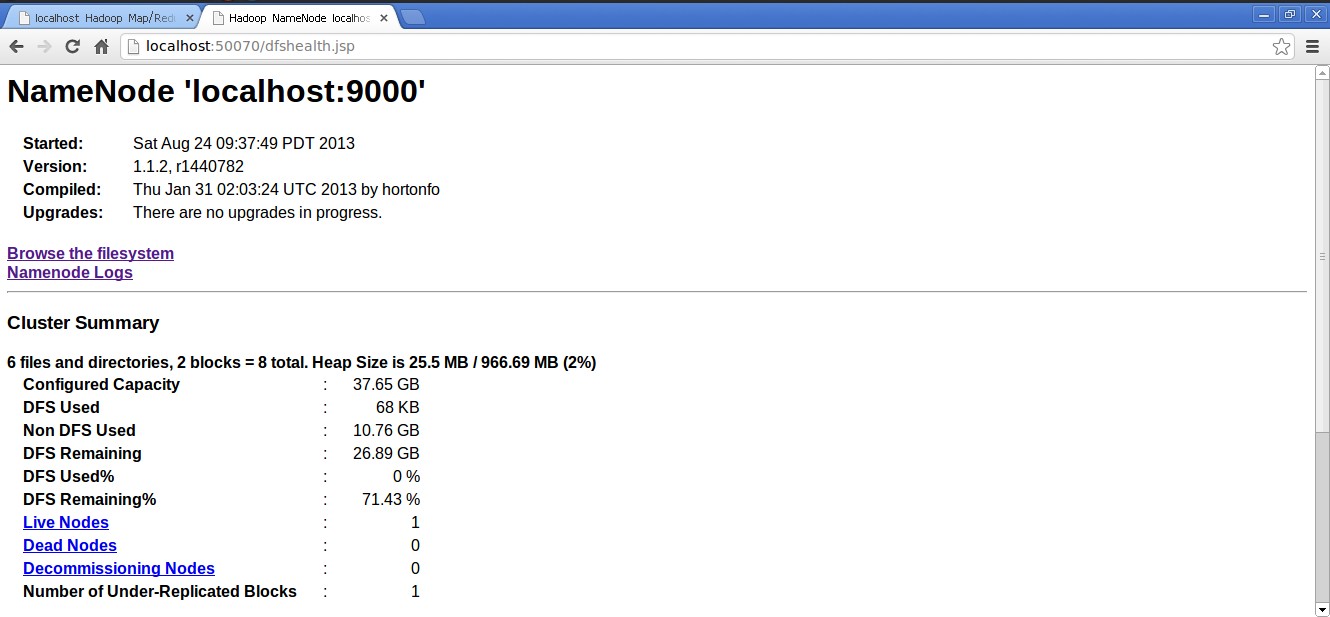
说明已经安装成功了。
下一节将介绍HDFS文件系统。
作者:Bester
出处:http://www.cnblogs.com/bester/p/3279884.html
Hadoop学习笔记3---安装并运行Hadoop的更多相关文章
- Hadoop学习笔记: 安装配置Hadoop
安装前的一些环境配置: 1. 给用户添加sudo权限,输入su - 进入root账号,然后输入visudo,进入编辑模式,找到这一行:"root ALL=(ALL) ALL"在下面 ...
- Hadoop学习笔记: 安装配置Hive
1. 在官网http://hive.apache.org/下载所需要版本的Hive,以下我们就以hive 2.1.0版为例. 2. 将下载好的压缩包放到指定文件夹解压,tar -zxvf apache ...
- 十三、Hadoop学习笔记————Hive安装先决条件以及部署
内嵌模式,存储于本地的Derby数据库中,只支持单用户 本地模式,支持多用户多会话,例如存入mysql 下载解压hive后,进到conf路径,将模板拷贝 出现该错误表示权限不够 该目录未找到 新建一个 ...
- hadoop学习笔记(三):hadoop文件结构
hadoop完整安装目录结构: 比较重要的包有以下4个: src hadoop源码包.最核心的代码所在目录为core.hdfs和mapred,他们分别实现了hadoop最重要的3个模块:基础公共库.H ...
- hadoop学习笔记(六):hadoop全分布式集群的环境搭建
本文原创,如需转载,请注明作者以及原文链接! 一.前期准备: 1.jdk安装 不要用centos7自带的openJDK2.hostname 配置 配置位置:/etc/s ...
- hadoop 学习笔记(第三章 Hadoop分布式文件系统 )
map->shuffle->reduce map(k1,v1)--->(k2,v2) reduce(k2,List<v2>)--->(k2,v3) 传输类型:org ...
- hadoop学习笔记(一):hadoop生态系统及简介
一.hadoop1.x的生态系统 HBase:实时分布式数据库 相当于关系型数据库,数据放在文件中,文件就放在HDFS中.因此HBase是基于HDFS的关系型数据库.实时性:延迟非常低,实时性高. 举 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记(2)
Hadoop学习笔记(2) ——解读Hello World 上一章中,我们把hadoop下载.安装.运行起来,最后还执行了一个Hello world程序,看到了结果.现在我们就来解读一下这个Hello ...
随机推荐
- Open_Newtonsoft_Json 的序列化和反序列化
Newtonsoft.Json,一款.NET中开源的Json序列化和反序列化类库(下载地址http://json.codeplex.com/). 特别注明:本人转自 陈 晨 博客园的 Newtonso ...
- BZOJ 1502 月下柠檬树(simpson积分)
题目链接:http://61.187.179.132/JudgeOnline/problem.php?id=1502 题意:给出如下一棵分层的树,给出每层的高度和每个面的半径.光线是平行的,与地面夹角 ...
- java获取系统指定时间年月日
java获取系统指定时间年月日 private String setDateTime(String falg) { Calendar c = Calendar.getInstance(); c.set ...
- 如何将SD卡或者TF卡的debian系统刷入nand
1. 在windows端下载辅助文件: a) http://dl.cubieforums.com/loz/boot_partition/bootloader/cubie_nand_uboot_part ...
- [ionic开源项目教程] - 第8讲 根据菜单分类加载数据(重要)
[ionic开源项目教程] - 第8讲 根据菜单分类加载数据(重要) [效果图] 注意 今天遇到一个比较棘手的问题,就是左右滑动菜单的设计不合理性,所以tab1.html对应的视图层和control ...
- 51nod1437 迈克步
傻叉单调栈 #include<cstdio> #include<cstring> #include<cctype> #include<algorithm> ...
- UVA 11865 Stream My Contest 组网 (朱刘算法,有向生成树,树形图)
题意: 给n个点编号为0~n-1,0号点为根,给m条边(含自环,重边),每条边有个代价,也有带宽.给定c,问代价不超过c,树形图的最小带宽的最大值能达到多少? 思路: 点数才60,而带宽范围也不大,可 ...
- ecshop 更新首页flash样式
未测试 ECSHOP默认的只有几种很普通的FLASH图片切换样式,想不想自己也换一种呢? 今天摸索了下,算是弄懂了,和大家分享下 首先在网上找到你想要的FLASH切换样式[google一下],把那个S ...
- (六) 6.2 Neurons Networks Backpropagation Algorithm
今天得主题是BP算法.大规模的神经网络可以使用batch gradient descent算法求解,也可以使用 stochastic gradient descent 算法,求解的关键问题在于求得每层 ...
- Btn要记得对状态进行设置
self.catBtn = [UIButtonbuttonWithType:UIButtonTypeSystem]; self.catBtn.backgroundColor = [UIColorred ...