第一次写python爬虫
花了4天终于把写完了把国内的几个漏洞平台爬完了,第一次写py,之前一直都在说学习,然后这周任务是把国内的漏洞信息爬取一下。花了1天学PY,剩下的1天一个。期间学习到了很多。总结如下:
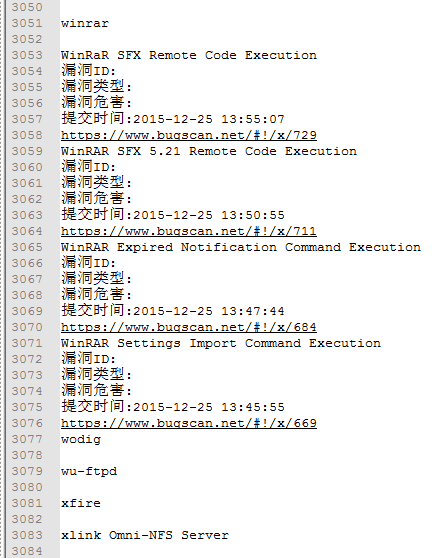

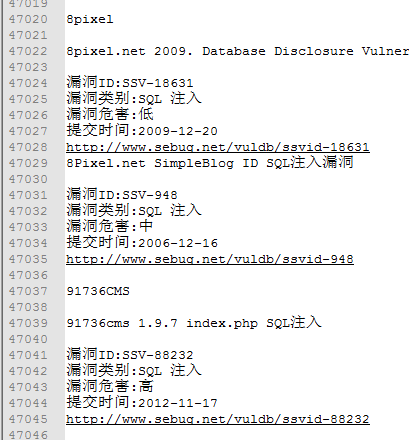
====================================================================


=====================================================================================================
期间用了几个不错的类库:
urllib2 re chardet sys bs4 BeautifulSoup requests json
比如获取某个标签beautifulsoup,find/findAll/find_all
获取标签的内容XXX.contents[i]
还有AJAX的爬虫:requests.post()期间用了这个方法和别的来爬的时候需要POST,但是一直是GET,纠结了一个晚上,最后问了腾讯某小伙伴解决了问题
只要是data=xxx 都会使用urlencode编码,所以一直是GET
返回的是JSON,如果用字符串处理的话相当麻烦,问了长亭的朋友,推荐用了Json的类库(爬AJAX的时候最好设置个头)
result=requests.post(url,json=payload,headers=headers)
#print result.text
content=json.loads(result.text)
text=content['result'] =========================
apps=json.dumps(j)
app_json=json.loads(apps)
time=app_json['date']
用起来会方便了很多很多,如果需要搞PY爬虫的时候可以尝试下。因为也是刚学,代码只是实现了功能,代码的架构,没有加线程,速度也不是很好,后期可能会去优化。
如果你遇到什么问题,欢迎一起学习,可以发到我的邮箱:sevck#jdsec.com :)
###############
最后说一下,建议别在WINDOWS下写PY,建议LINUX
第一次写python爬虫的更多相关文章
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- 零基础教你写python爬虫
大家都知道python经常被用来做爬虫,用来在互联网上抓取我们需要的信息. 使用Python做爬虫,需要用到一些包: requests urllib BeautifulSoup 等等,关于python ...
- 第一次写python
这是一个在BJDP上学习Coding Kata的时候用到的一个练习,原来打算用Java写的,但是一想正好是学习的好机会. 就用Python了.第一次,写的有些复杂. 这个题目是关于购买图书的打折信息的 ...
- Python爬虫初探 - selenium+beautifulsoup4+chromedriver爬取需要登录的网页信息
目标 之前的自动答复机器人需要从一个内部网页上获取的消息用于回复一些问题,但是没有对应的查询api,于是想到了用脚本模拟浏览器访问网站爬取内容返回给用户.详细介绍了第一次探索python爬虫的坑. 准 ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- 十个Python爬虫武器库示例,十个爬虫框架,十种实现爬虫的方法!
一般比价小型的爬虫需求,我是直接使用requests库 + bs4就解决了,再麻烦点就使用selenium解决js的异步 加载问题.相对比较大型的需求才使用框架,主要是便于管理以及扩展等. 1.Scr ...
- 初次尝试python爬虫,爬取小说网站的小说。
本次是小阿鹏,第一次通过python爬虫去爬一个小说网站的小说. 下面直接上菜. 1.首先我需要导入相应的包,这里我采用了第三方模块的架包,requests.requests是python实现的简单易 ...
- 《精通Python网络爬虫》|百度网盘免费下载|Python爬虫实战
<精通Python网络爬虫>|百度网盘免费下载|Python爬虫实战 提取码:7wr5 内容简介 为什么写这本书 网络爬虫其实很早就出现了,最开始网络爬虫主要应用在各种搜索引擎中.在搜索引 ...
随机推荐
- Auto push git tag
CALL "C:\Program Files\TortoiseGit\bin\pageant.exe" "d:\CKey.ppk" set GIT_SSH=C: ...
- python通过win32api轻松获取控件的属性值
1.如何利用句柄操作windows窗体 首先,获得窗体的句柄 win32api.FindWindows() 第二,获得窗体中控件的id号,spy++ 第三,根据控件的ID获得控件的句柄(hwnd) ...
- java中==与equal()方法的区别
==比较的是对象的地址,也就是是否是同一个对象: equal比较的是对象的值. Integer r1 = new Integer(900);//定义r1整型对象Integer r2 = new Int ...
- flex 右键连接
var menuItem:ContextMenuItem = new ContextMenuItem("技术支持:中科天宇软件有限公司", true, true); menuIte ...
- JVM 指令集
指令码 助记符 说明 0x00 nop 什么都不做 0x01 aconst_null 将null推送至栈顶 0x02 iconst_m1 将int型-1推送至栈顶 0x03 iconst_0 将int ...
- MongoDB C# / .NET Driver
MongoDB C# Driver是官方提供的.NET C#驱动. Getting Started with the C# Driver C# Driver Tutorial C# Driver LI ...
- 【Pro ASP.NET MVC 3 Framework】.学习笔记.8.SportsStore:管理
管理功能,如何身份认证,对controller和action方法过滤安全的访问,并在用户需要时提供证书. 1 添加分类管理 方便管理的controller,有两类页面,List页面和edit页面. 1 ...
- linux中Iptables限制同一IP连接数防CC/DDOS攻击方法
1.限制与80端口连接的IP最大连接数为10,可自定义修改. 代码如下 复制代码 iptables -I INPUT -p tcp --dport 80 -m connlimit --connlim ...
- PHP给图片加文字(水印)
准备工作: 代码: <?php header("Content-type: image/jpeg"); //浏览器输出,如不需要可去掉此行 $im = @imagecreat ...
- HDU 4825:Xor Sum(Trie)
http://acm.hdu.edu.cn/showproblem.php?pid=4825 题意:给出N个数,M个询问,每个询问给出一个X,问在这N个数中哪个数和X异或后结果最大. 思路:可以用Tr ...