Hawk 1.2 快速入门2 (大众点评18万美食数据)
本文将讲解通过本软件,获取大众点评的所有美食数据,可选择任一城市,也可以很方便地修改成获取其他生活门类信息的爬虫。
本文将省略原理,一步步地介绍如何在20分钟内完成爬虫的设计,基本不需要编程,还能自动并行抓取。
看完这篇文章,你应该就能举一反三地抓取绝大多数网站的数据了。Hawk是一整套工具,它的能力取决于你的设计和思路。希望你会喜欢它。
详细过程视频可参考:http://v.qq.com/page/z/g/h/z01891n1rgh.html,值得注意的是,由于软件不断升级,因此细节和视频可能有所出入。
准备好了么?Let's do it!
1.做饭先生火:自动设置cookie:
我们先打开大众点评的美食列表页面:
http://www.dianping.com/search/category/2/10/g311
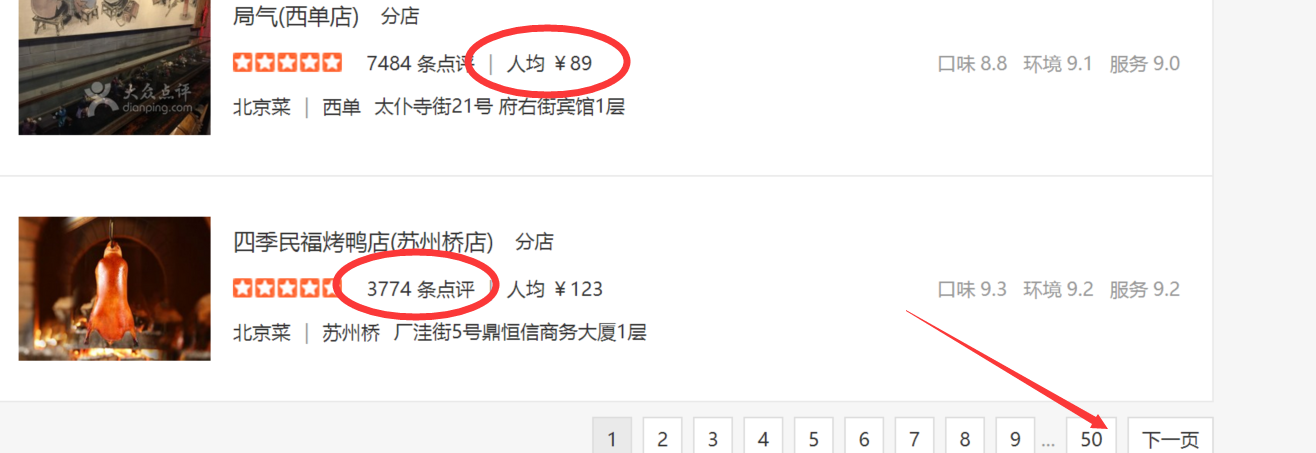
这是北京的"北京菜"列表,但你会注意到,只能抓取前50页数据(如箭头所示),是一种防爬虫策略,我们之后来破解它。
我们双击打开一个网页采集器:
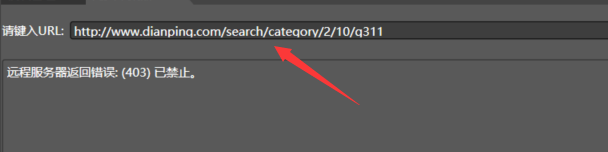
之后在最上方的地址栏里填写地址:
(新版本的Hawk已经能自动模拟浏览器,对大众点评,自动嗅探可以忽略)
但会发现远程服务器拒绝了请求,原因是大众点评认为Hawk是爬虫而不是浏览器。
没有关系,我们让Hawk来监控浏览器的行为,在右侧的自动嗅探窗口中,填写url过滤和内容筛选,之后点击开始。浏览器会自动打开该网页,程序后台自动记录了所有的行为,之后点击关闭按钮(切记点击关闭)。
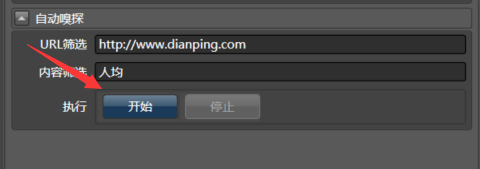
(此处大概介绍原理:Hawk在点击开始之后,会自动成为代理,所有的浏览器请求都会经过Hawk,在输入特定的URL筛选前缀和关键字,则Hawk会自动拦截符合要求的Request,并将其详细信息记录下来,并最终模拟它)。
之后,我们点击右方的“高级设置”里,能够看到Hawk已经把这次访问的cookie和headers自动保存下来:
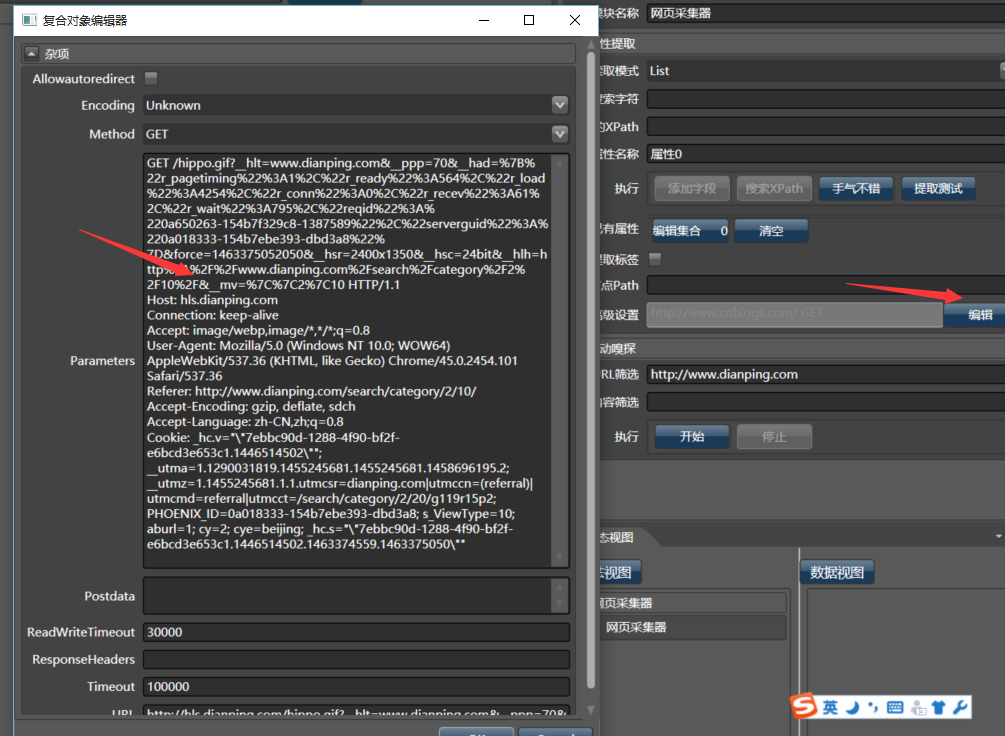
我们再次点击刷新网页,可以看到已经能成功获取网页内容:
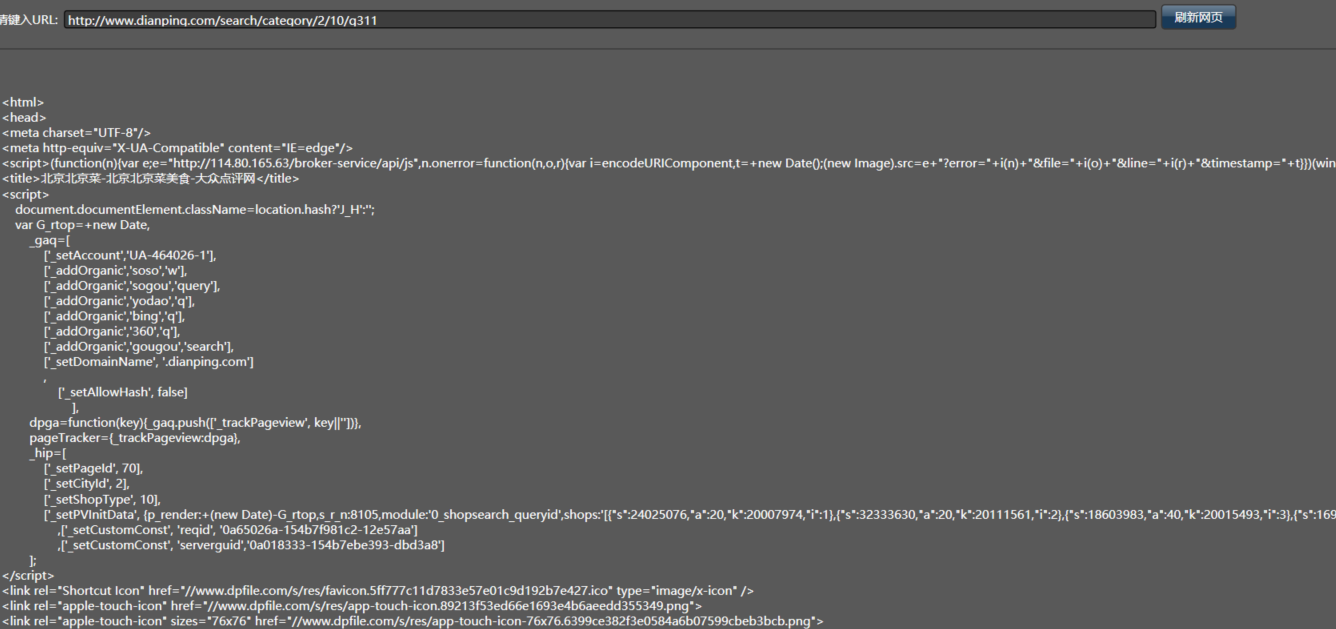
完成这一步之后,我们就能够像普通网页那样免登陆抓取信息了。这也适合需要登录的各类网站。
2.洗菜切菜:获取门店列表
我们通过自动和手动两种方式来获取门店列表,你可以两种都试试。
2.1 全自动获取
直接点击手气不错即可,不需要其他操作:
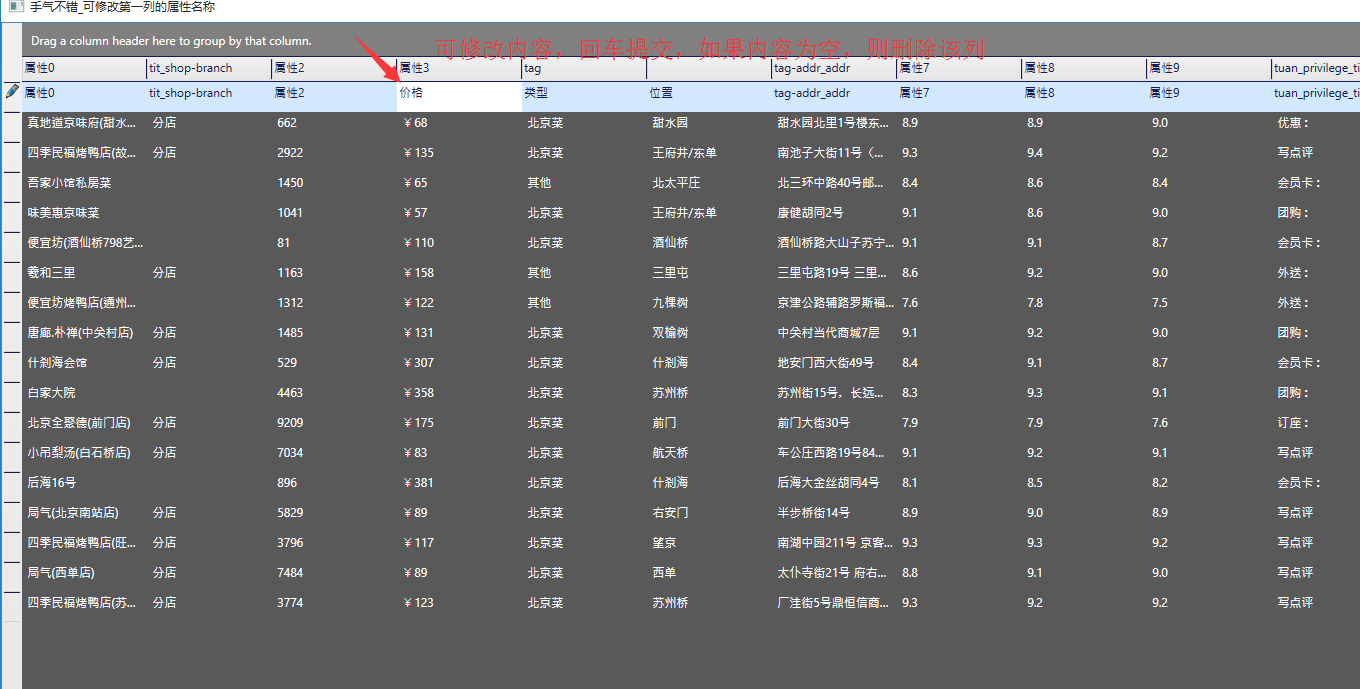
2.2 纯手工获取
我们先手工输入筛选条件吧:
输入上面的关键字3774,命名为点评:
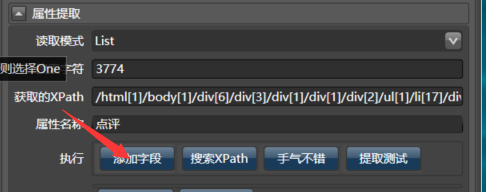
接着,填入89,你会发现是下面这样:

注意XPath表达式和点评的表达式不大一样,这是因为89太普通,在网页中出现多次,再次点击搜索XPath,即可找到正确的位置。
类似地,将所有你认为需要的属性添加进去,加上合适的命名,大概是这个样子:
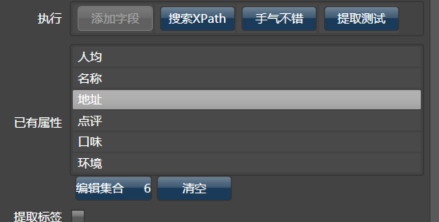
当然,我们还需要门店的ID,但在页面上并不提供,那在浏览器上点击那个“四季民福烤鸭店”(沙漠君厌恶吃鸭子),你会看到它的链接为:

我们将18002657添加并搜索,发现不论怎么点都搜索不到,此时勾选提取标签,系统会在标签中搜索:
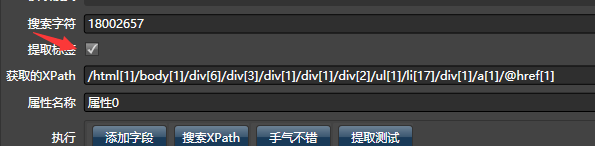
之后获取了全部属性后,点击提取测试,系统会自动优化XPath,列表父节点会显示在下方。
笔者建议自动加手动配合的方式,自动抓取大部分数据,再用手动修改调整,手气不错虽然智能,但并不是什么时候都管用。
将本模块命名为门店列表,供之后备用:

3.餐前甜点:获取50页数据
我们先用50页数据试试手,在刚才那个浏览器页面的最下方,点击翻页,可以发现是如下的结构:
http://www.dianping.com/search/category/2/10/g311p2
http://www.dianping.com/search/category/2/10/g311p3
http://www.dianping.com/search/category/2/10/g311p4
...好,新建数据清洗,随便给它起个名字,从左面拖入生成区间数,双击配置列名为page,最大值填50,再拖入合并多列到page列,配置如下:
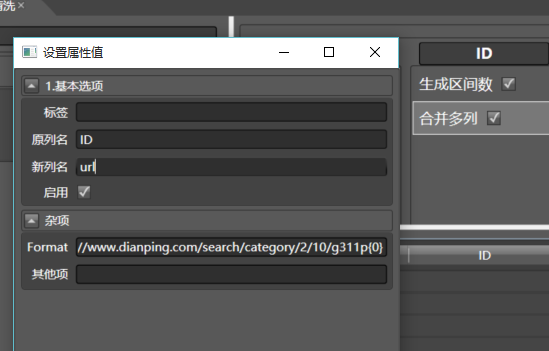
其中Format设置为:
http://www.dianping.com/search/category/2/10/g311p{0}
这是C#的一种字符串替换语法,{0}会被依次替换为1,2,3...
最后,拖从爬虫转换到url列,奇迹出现了吧?
为了保存结果,我们拖写入数据表到任意一列,这里选择了名称列,配置如下:
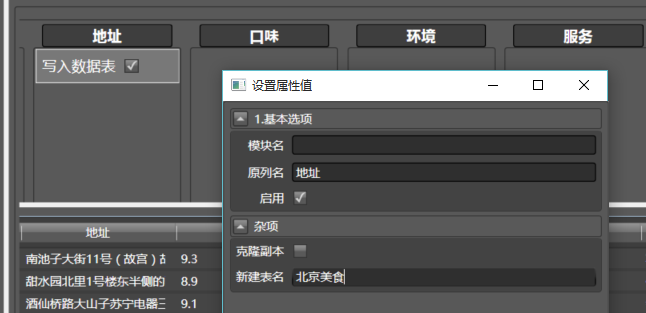
之后,在右侧选择并行或串行模式(随你),点击执行即可。
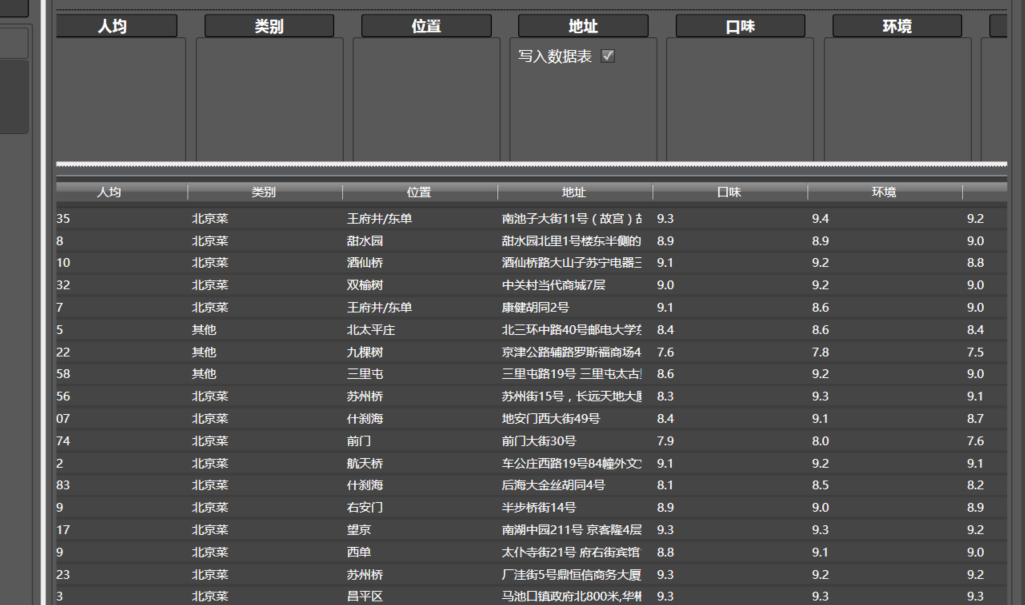
数据采集完成了!
如果看到这一步累了,可以不看下面的内容,但如果想获取全部内容,步骤就复杂多了,如果你下决心学习,我们接着往下看
4. 准备葱蒜:获取城市的美食门类
解决问题的办法是分而治之,获取每个区县(如北京的海淀区)下的某一种美食门类(东北菜),自然就没50页那么多了。所以,要获取美食门类,再获取所有的区域。
先找到所有美食门类的位置:
http://www.dianping.com/shopall/2/0
为了获取此页面上的信息,我们再新建一个网页采集器,命名为通用采集器,它的目标是获取整个HTML页面,因此
读取模式改成One,将刚才门店列表采集器里的高级设置->Parameters的内容拷贝到本采集器对应的窗口中。
(其实也可以做嗅探,但这个更快一些)。
之后,我们来获取这个页面上的所有美食门类,新建数据清洗,命名为门类,然后从左侧拖从文本生成到右侧任意一列,命名如下:
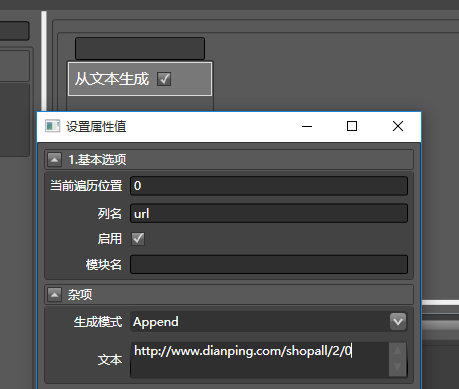
再拖入从爬虫转换,配置如下:

即可调用刚才的通用采集器。另外,左侧的工具栏支持搜索,直接关键字即可快速定位,结果如下:
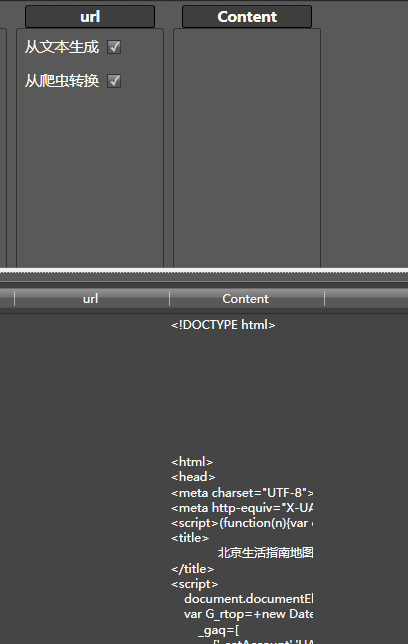

为了获取下图的北京菜所在的位置,虽然可以用Hawk,但为了方便可以使用Chrome,搜狗和360浏览器的F12开发者工具功能,找到对应的元素,点击右键,拷贝XPath:
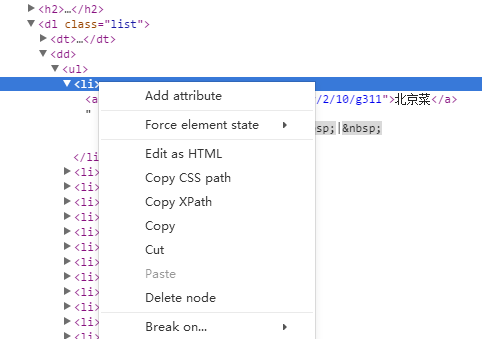
内容为://*[@id="top"]/div[6]/div/div[1]/dl[1]/dd/ul/li[1],
因为要获取所有的子li,在刚才的数据清洗中,向Content列拖入XPath筛选器,配置如下:

由于要获取所有的li子节点,所以去掉了最后的1,可以适当复习XPath语法。
奇迹出现了:

接下来步骤很简单,我不截图了:
- 拖入HTML字符转义到Text列,可以清除该列的乱码
- 再拖入字符串分割到Text,勾选空格分割,可对该数据用空格分割,并获取默认的第一个子串
- 拖入删除该列到OHTML,该列没有用
再拖入正则转换器到HTML,配置如下:
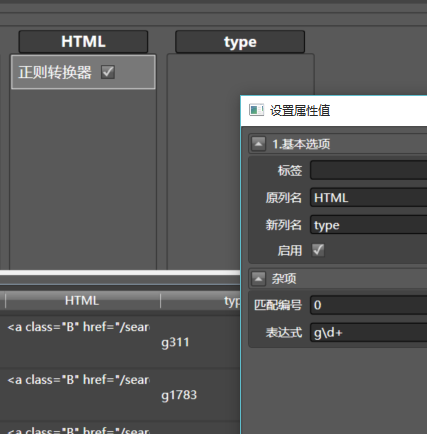
g\d+代表匹配那个门类的ID,比如刚才的g311- 拖入删除该列到HTML
直接在Text列的上方修改名称为门类
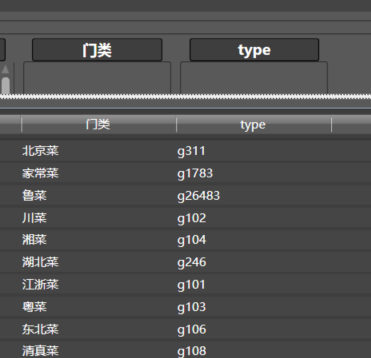
最终结果如下:
5.获取北京的区域
这一步和上一步非常类似,因此我很简明地介绍一下。
区域在这个页面:
http://www.dianping.com/search/category/2/10/g311p2

这些节点的XPath是://*[@id="region-nav"]/a
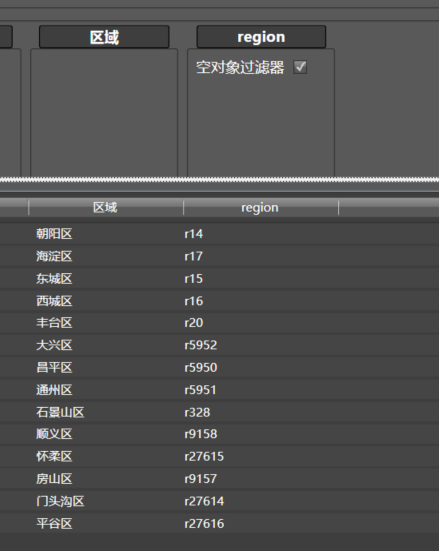
你可以按照刚才类似的步骤进行,也是创建新的数据清洗,把这个子模块命名为区域,最终结果如下:
如果自己做不下来,也没有关系,加载Github上大众点评的教程.xml,可以直接用这个现成的模块,也可以单步调试之,看看它是怎么写的。
6. 正菜开始:主流程
下面是最难也是最复杂的部分。我们的思路是,组合所有的门类和区域,构成m*n的一组序对,如海淀区-北京菜,朝阳区-火锅等等,获取对应序对的页数,再将所有结果拼接起来。
准备好了么?我们继续。
新建数据清洗,命名为主流程,我们要调用刚才定义的模块,拖入子流-生成到任意一列,配置如下:
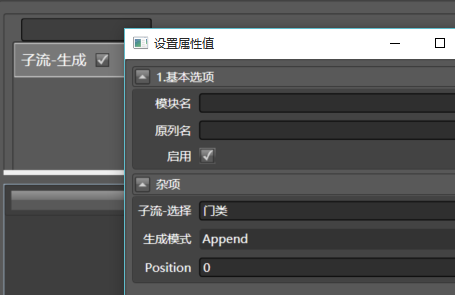
记得要勾选启用,这些模块默认是不启用的。
再拖入子流-生成到任意一列,配置如下:
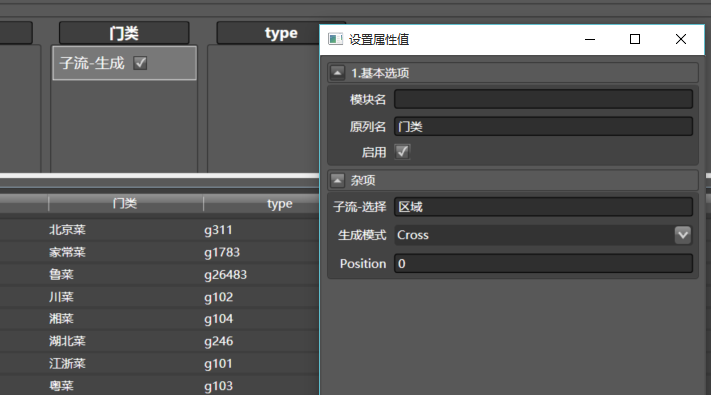
注意生成模式改为Cross。
具体不同模式的工作方式,可参考这篇文章:http://www.cnblogs.com/buptzym/p/5501003.html
之后,就是这个样子:
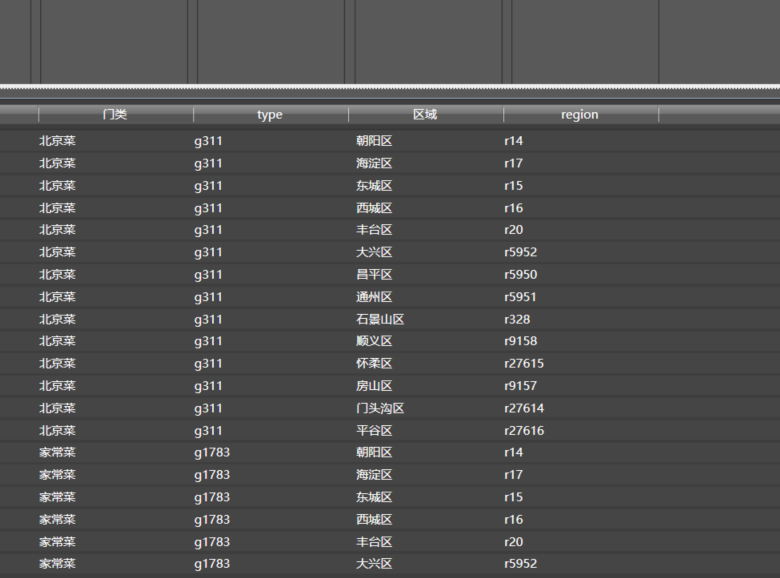
我们将两列组合起来,可看到Url为如下的形式:
http://www.dianping.com/search/category/2/10/**g311r14**
拖合并多列到type,配置如下:
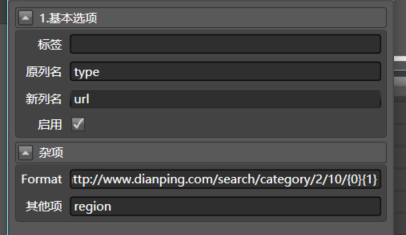
{0}{1}相当于组合了多个元素,拖入的当前列为第0元素,其他项用空格分割,分别代表第1,2...个元素。
为了获取每个门类的页数,需要在页面上找一下:
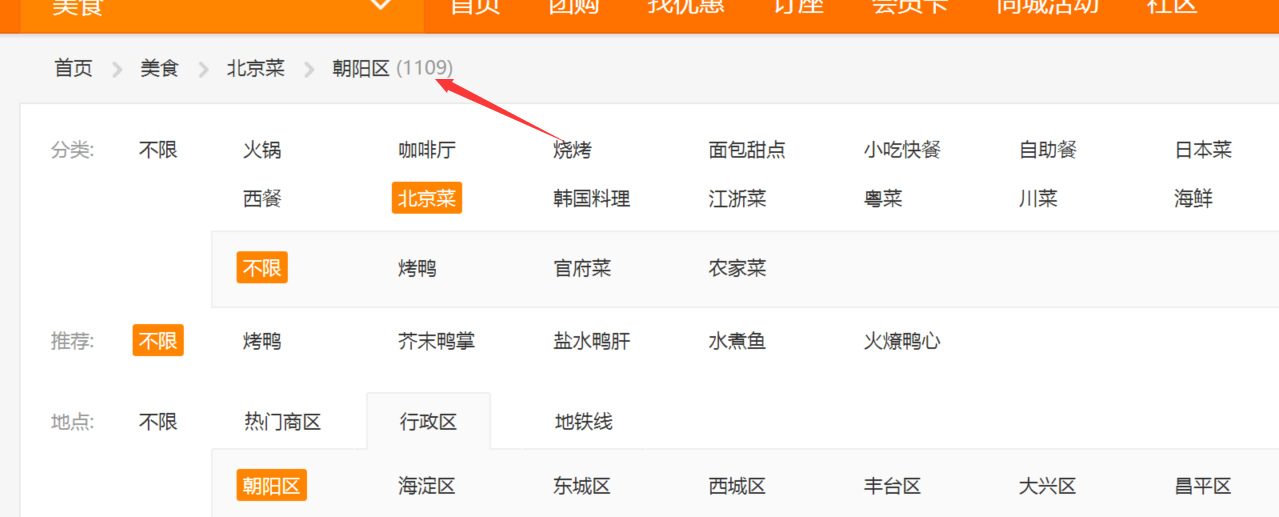
它的XPath是/html[1]/body[1]/div[6]/div[1]/span[7]
- 拖入从爬虫转换到url列,配置爬虫选择为通用采集器,就能获取对应的HTML
- 拖入XPath筛选器到HTML所在的Content列,XPath表达式如上
/html[1]/body[1]/div[6]/div[1]/span[7]。只获取一个数据,新列名为count - 拖入删除该列到Content列。
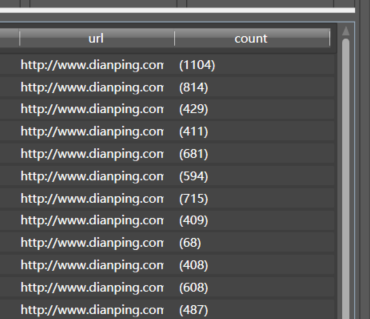
- 拖入提取数字到count列
拖入Python转换器到count列,这是本文唯一要写的代码:
配置如下:
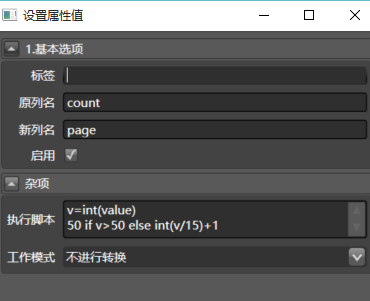
代码在下面:v=int(value) 50 if v>50 else int(v/15)+1Python代码很好理解吧,大概是说超过50页就按50页处理,页数等于数量除以每页15个,取整后+1。
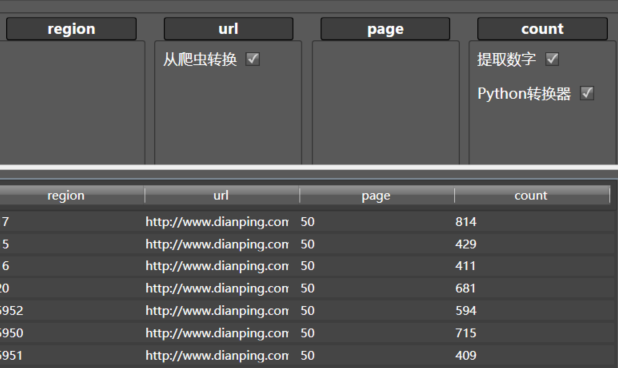
你会发现即使这样,每个门类还是超过了50页,这个问题我们之后再讨论。
为了方便并行,拖入流实例化到任意一列,配置如下:
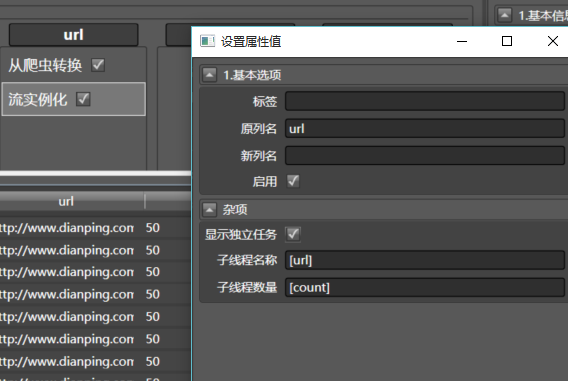 。
。
执行器会将每一个门类区县对分配一个独立的线程,注意方括号[url]的写法,系统会把url列的内容赋值到这里,如果你只写url,那所有的线程名称都叫url了。你可以不添加流实例化,看看系统最后是怎么工作的。
接下来,我们要把page列展开,生成[0-page]的区间数,一页一页去抓取。拖生成区间数到page列,配置如下:
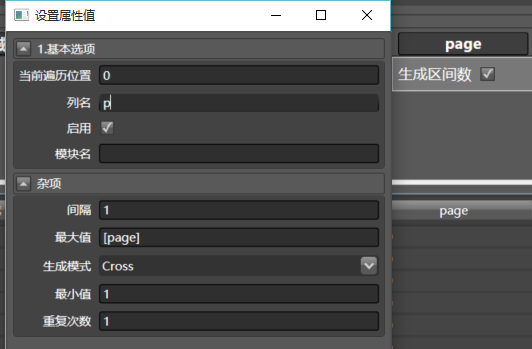
注意Cross和[page],我就不多解释了。
把刚才的url和现在的p列合并,就构成了每一页的真实url.
拖入合并多列到url,配置如下:
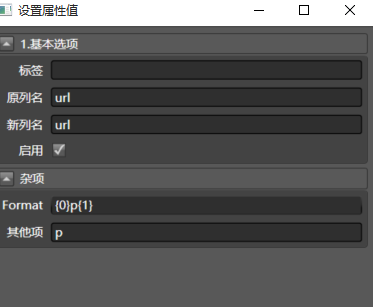
仔细理解一下配置的意思,尤其是{0}p{1},我觉得读者到了这一步,已经对整个系统有点感觉了。
雄关漫道真如铁,我们马上到达目的地了。
现在url列已经是这个样子了(点击查看样例即可)
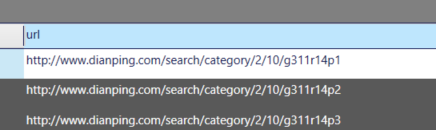
将从爬虫转换到url,配置爬虫来源为门店列表!然后等待奇迹出现
(卖个关子,我就不截图了)
然后拖入写入数据表到任意一列,为表名起个名字,点击执行去跑就可以了。
如果你到这一步就满意了,那么文章可以不用往下看了。
7 .注重细节
一道大菜要非常注意细节,爬虫也一样。
7.1 保留原始表的信息
你看到数据表里没有这家店的区县,也没有所在的页数,感觉从爬虫转换丢失了原始表的一部分信息,事实上它在1转多的时候,原始表默认都会丢掉。
因此在下图的位置,点击编辑集合,选择最后的那个从爬虫转换,配置如下:

它会将p和区域两列,添加到新表中。
7.2 我想写入数据库
目前Hawk没有强的自动建表功能,因此建议使用MongoDB,如果你已经安装了,在模块管理的数据源哪里,点击右键,可新建MongoDB连接器。
可以在主流程的最后位置,在拖入写入数据库,即可。
7.3 还是没有获取所有数据
即使是刚才这样的复杂操作,依然不能获取所有的美食,因为火锅太火,朝阳海淀的火锅都超过了50页,解决方法是再细分商区,比如朝阳的三元桥,国贸,望京...这样就能完整解决了。但本文限于篇幅就不讨论了。
7.4 如何将数据表导出到文件?
在右下角的数据管理,在要导出的表上点右键,建议输出为xml,json和txt文件,excel文件在数据量较大(5万以上)会有性能问题。
7.5 这种图形化操作有什么优势?
效率!所见即所得!你可以试着用任意一种代码去写,烦死你
7.6 如何保存所有操作?
会将所有刚才的操作保存在工程文件中。
7.6 我的服务器在Linux上,怎么办
Hawk是WPF,C#开发的,因此只能在Windows上运行,不过它生成的xml可以被Python解释,参考github上的etlpy.
7.7 Hawk是你一个人写的吗?用了多久
目前来看是这样的。业余时间四年
7.8我想获取各个城市的,不限于美食的数据
这个就更复杂了,可以借助脚本实现,这是下一篇的话题。
8.总结
为了方便大家学习使用,刚才的整个操作已经上传到了Github。地址为https://github.com/ferventdesert/Hawk-Projects
大众点评-教程.xml
有任何问题,欢迎留言。
Hawk 1.2 快速入门2 (大众点评18万美食数据)的更多相关文章
- Hawk: 20分钟无编程抓取大众点评17万数据
1. 主角出场:Hawk介绍 Hawk是沙漠之鹰开发的一款数据抓取和清洗工具,目前已经在Github开源.详细介绍可参考:http://www.cnblogs.com/buptzym/p/545419 ...
- Hawk 1.1 快速入门(链家二手房)
链家的同学请原谅我,但你们的网站做的真是不错. 1. 设计网页采集器 我们以爬取链家二手房为例,介绍网页采集器的使用.首先双击图标,加载采集器: 在最上方的地址栏中,输入要采集的目标网址,本次是htt ...
- ADO.NET 快速入门(九):使用关系型数据
DataSet 可以包含非关联表,也可以包含关联表.你可以把 DataSet 想象成一个文档数据.事实上,除了 DataSet 是基于层级模型的,其它和 XML 数据文档是一样的.由于数据通常存储在关 ...
- AngularJS快速入门指南20:快速参考
thead>tr>th, table.reference>tbody>tr>th, table.reference>tfoot>tr>th, table ...
- Mybatis3 快速入门
Mybatis3 快速入门 目前常见的持久层java框架有Hibernate,Mybatis,SpringData.笔者比较喜欢用SpringData.Hibernate 和 Mybatis 也经常用 ...
- 【Python3爬虫】大众点评爬虫(破解CSS反爬)
本次爬虫的爬取目标是大众点评上的一些店铺的店铺名称.推荐菜和评分信息. 一.页面分析 进入大众点评,然后选择美食(http://www.dianping.com/wuhan/ch10),可以看到一页有 ...
- Spark2.x学习笔记:Spark SQL快速入门
Spark SQL快速入门 本地表 (1)准备数据 [root@node1 ~]# mkdir /tmp/data [root@node1 ~]# cat data/ml-1m/users.dat | ...
- 大众点评开源分布式监控平台 CAT 深度剖析
一.CAT介绍 CAT系统原型和理念来源于eBay的CAL的系统,CAT系统第一代设计者吴其敏在eBay工作长达十几年,对CAL系统有深刻的理解.CAT不仅增强了CAL系统核心模型,还添加了更丰富的报 ...
- 【腾讯Bugly干货分享】美团大众点评 Hybrid 化建设
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:http://mp.weixin.qq.com/s/rNGD6SotKoO8frmxIU8-xw 本期 T ...
随机推荐
- 程序猿都没对象,JS竟然有对象?
现在做项目基本是套用框架,不论是网上的前端还是后端框架,也会寻找一些封装好的插件拿来即用,但还是希望拿来时最好自己过后再回过头了解里面的原理,学习里面优秀的东西,不论代码封装性,还是小到命名. 好吧, ...
- C#制作简易屏保
前言:前段时间,有个网友问我C#制作屏保的问题,我瞬间懵逼了(C#还可以制作屏保!).于是我去查阅相关资料,下面把C#如何制作屏保的过程及我学习过程的心得也记录下来,希望对需要的人能有帮助. 基本思路 ...
- H3 BPM让天下没有难用的流程之产品概述
一.产品简介 BPM(Business Process Management),是指根据业务环境的变化,推进人与人之间.人与系统之间以及系统与系统之间的整合及调整的经营方法与解决方案的IT工具. H3 ...
- Android Socket连接PC出错问题及解决
最近测试问题:Android 通过Socket链接电脑,ip和端口都是正确的,也在同一网段,可android端就是报异常如下: 解决办法:测试电脑的防火墙可能开着,在控制面板把防火墙打开即可.
- sql 删除表中的重复记录
嗯,遇见了表中存在重复的记录的问题,直接写sql删除时最快的,才不要慢慢的复制到excel表中慢慢的人工找呢.哼. 如下sql,找出重复的记录,和重复记录中ID值最小的记录(表中ID为自增长) sel ...
- Oracle 列数据聚合方法汇总
网上流传众多列数据聚合方法,现将各方法整理汇总,以做备忘. wm_concat 该方法来自wmsys下的wm_concat函数,属于Oracle内部函数,返回值类型varchar2,最大字符数4000 ...
- SQL Server事务、视图和索引
废话不多说,直接上干货 14:13:23 事务 概括:事务是一种机制,一个操作序列,包含一组数据库操作命令,并且把所有的命令作为一个整体一起 向系统提交或撤销操作 请求. 事务的特性: 1.原子性 ...
- Apache2.4:AH01630 client denied by server configuration
问题说明:Apache服务总共有4个,是为了防止单点故障和负载均衡,负载均衡控制由局方的F5提供. 访问的内容在NAS存储上,现象是直接访问每个apache的服务内容都是没有问题,但是从负载地址过来的 ...
- ASP.NET 5 和Entity Framework 7公告仓库
ASP.NET 5 有一个公告仓库来介绍ASP.NET 5和 Entity Framework 7的主要变更说明,这个对于日夜更新的项目来说,很多人经常会遇到问题但是不知道去哪里寻找帮助,很多同学在做 ...
- Dubbo学习小记
前言 周一入职的新公司,到了公司第一件事自然是要熟悉新公司使用的各种技术,搭建本地的环境. 熟悉新公司技术的过程中,首先就是Maven,这个前面已经写过文章了,然后就是Dubbo----公司的服务都是 ...