k临近法的实现:kd树
k近邻算法
3.1 k近邻算法
k近邻算法简单、直观:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例,这k个实例的多数属于某个类,就把该输入实例分为这个类。下面先叙述k近邻算法,然后再讨论其细节。
算法3.1(k近邻法)
输入:训练数据集
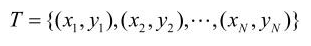

其中,xi∊x⊆Rn为实例的特征向量,yi∊ ={c1,c2,…,cK}为实例的类别,i=1,2,…,N;实例特征向量x;
={c1,c2,…,cK}为实例的类别,i=1,2,…,N;实例特征向量x;
输出:实例x所属的类y。
(1)根据给定的距离度量,在训练集T中找出与x最邻近的k个点,涵盖这k个点的x的邻域记作Nk(x);
(2)在Nk(x)中根据分类决策规则(如多数表决)决定x的类别y:
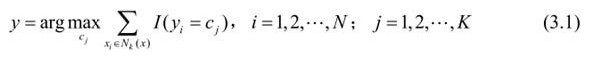

式(3.1)中,I为指示函数,即当yi=cj时I为1,否则I为0。
k近邻法的特殊情况是k=1的情形,称为最近邻算法。对于输入的实例点(特征向量)x,最近邻法将训练数据集中与x最邻近点的类作为x的类。
k近邻法没有显式的学习过程。
3.3k近邻法的实现:kd树
实现k近邻法时,主要考虑的问题是如何对训练数据进行快速k近邻搜索。这点在特征空间的维数大及训练数据容量大时尤其必要。
k近邻法最简单的实现方法是线性扫描(linear scan)。这时要计算输入实例与每一个训练实例的距离。当训练集很大时,计算非常耗时,这种方法是不可行的。
为了提高k近邻搜索的效率,可以考虑使用特殊的结构存储训练数据,以减少计算距离的次数。具体方法很多,下面介绍其中的kd树(kd tree)方法[1]。
3.3.1 构造kd树
kd树是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是二叉树,表示对k维空间的一个划分(partition)。构造kd树相当于不断地用垂直于坐标轴的超平面将k维空间切分,构成一系列的k维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。
构造kd树的方法如下:构造根结点,使根结点对应于k维空间中包含所有实例点的超矩形区域;通过下面的递归方法,不断地对k维空间进行切分,生成子结点。在超矩形区域(结点)上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);这时,实例被分到两个子区域。这个过程直到子区域内没有实例时终止(终止时的结点为叶结点)。在此过程中,将实例保存在相应的结点上。
通常,依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数(median)[2]为切分点,这样得到的kd树是平衡的。注意,平衡的kd树搜索时的效率未必是最优的。
下面给出构造kd树的算法。
算法3.2(构造平衡kd树)
输入:k维空间数据集T={x1,x2,…,xN},
输出:kd树。
(1)开始:构造根结点,根结点对应于包含T的k维空间的超矩形区域。
选择x(1)为坐标轴,以T中所有实例的x(1)坐标的中位数为切分点,将根结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴x(1)垂直的超平面实现。
由根结点生成深度为1的左、右子结点:左子结点对应坐标x(1)小于切分点的子区域,右子结点对应于坐标x(1)大于切分点的子区域。
将落在切分超平面上的实例点保存在根结点。
(2)重复:对深度为j的结点,选择x(l)为切分的坐标轴,l=j(modk)+1,以该结点的区域中所有实例的x(l)坐标的中位数为切分点,将该结点对应的超矩形区域切分为两个子区域。切分由通过切分点并与坐标轴x(l)垂直的超平面实现。
由该结点生成深度为j+1的左、右子结点:左子结点对应坐标x(l)小于切分点的子区域,右子结点对应坐标x(l)大于切分点的子区域。
将落在切分超平面上的实例点保存在该结点。
(3)直到两个子区域没有实例存在时停止。从而形成kd树的区域划分。
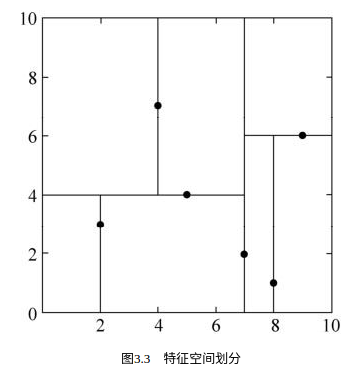
例3.2 给定一个二维空间的数据集:
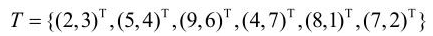

构造一个平衡kd树[3]。
解 根结点对应包含数据集T的矩形,选择x(1)轴,6个数据点的x(1)坐标的中位数是7,以平面x(1)=7将空间分为左、右两个子矩形(子结点);接着,左矩形以x(2)=4分为两个子矩形,右矩形以x(2)=6分为两个子矩形,如此递归,最后得到如图3.3所示的特征空间划分和如图3.4所示的kd树。

下面叙述用kd树的最近邻搜索算法。
算法3.3(用kd树的最近邻搜索)
输入:已构造的kd树;目标点x;
输出:x的最近邻。
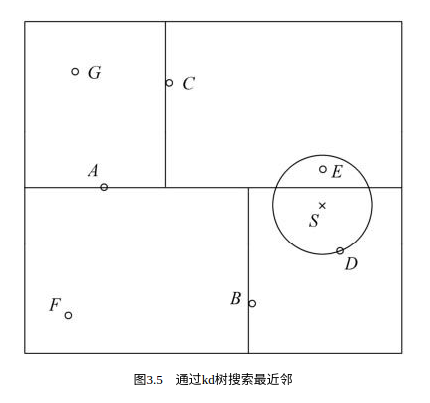
(1)在kd树中找出包含目标点x的叶结点:从根结点出发,递归地向下访问kd树。若目标点x当前维的坐标小于切分点的坐标,则移动到左子结点,否则移动到右子结点。直到子结点为叶结点为止。
(2)以此叶结点为“当前最近点”。
(3)递归地向上回退,在每个结点进行以下操作:
(a)如果该结点保存的实例点比当前最近点距离目标点更近,则以该实例点为“当前最近点”。
(b)当前最近点一定存在于该结点一个子结点对应的区域。检查该子结点的父结点的另一子结点对应的区域是否有更近的点。具体地,检查另一子结点对应的区域是否与以目标点为球心、以目标点与“当前最近点”间的距离为半径的超球体相交。
如果相交,可能在另一个子结点对应的区域内存在距目标点更近的点,移动到另一个子结点。接着,递归地进行最近邻搜索;
如果不相交,向上回退。
(4)当回退到根结点时,搜索结束。最后的“当前最近点”即为x的最近邻点。
如果实例点是随机分布的,kd树搜索的平均计算复杂度是O(logN),这里N是训练实例数。kd树更适用于训练实例数远大于空间维数时的k近邻搜索。当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线性扫描。
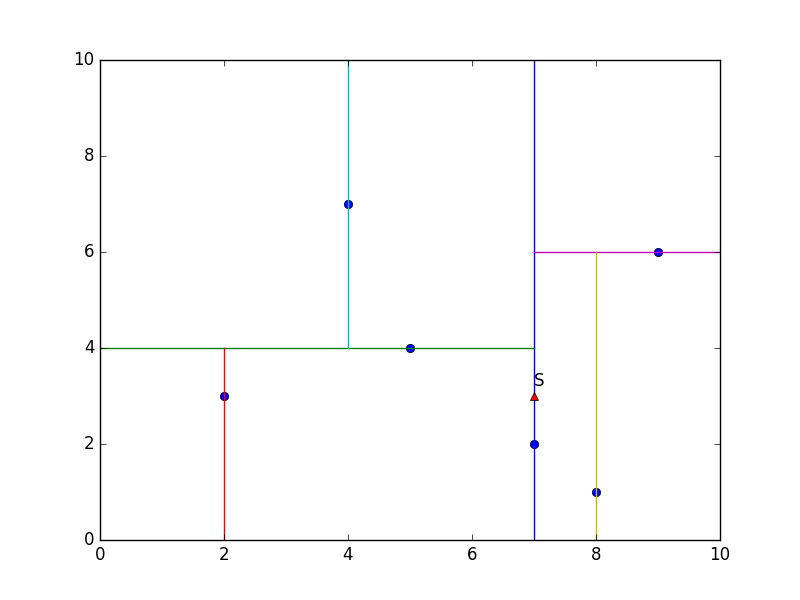
# coding:utf-8
import numpy as np
import matplotlib.pyplot as plt T = [[2, 3], [5, 4], [9, 6], [4, 7], [8, 1], [7, 2]]
S=[7, 3] class node:
def __init__(self, point):
self.left = None
self.right = None
self.point = point
self.parent = None
pass def set_left(self, left):
if left == None: pass
left.parent = self
self.left = left def set_right(self, right):
if right == None: pass
right.parent = self
self.right = right def median(lst):
m = len(lst) / 2
return lst[m], m def build_kdtree(data, d):
data = sorted(data, key=lambda x: x[d])
p, m = median(data)
tree = node(p)
del data[m]
if m > 0: tree.set_left(build_kdtree(data[:m], not d))
if len(data) > 1: tree.set_right(build_kdtree(data[m:], not d))
return tree def distance(a, b):
return ((a[0] - b[0]) ** 2 + (a[1] - b[1]) ** 2) ** 0.5 def search_kdtree(tree, target,best=[]):
if len(best)==0: best = [tree.point,distance(tree.point, target)]
if target[0] < tree.point[0]:
if tree.left != None:
return search_kdtree(tree.left, target, best)
else:
if tree.right != None:
return search_kdtree(tree.right, target, best)
def update_best(t, best):
if t == None: return
t = t.point
d = distance(t, target)
if d < best[1]:
best[1] = d
best[0] = t
while (tree.parent != None):
update_best(tree.parent.left, best)
update_best(tree.parent.right, best)
tree = tree.parent
return best[0] def showT(tree,d):
plt.plot(tree.point[0],tree.point[1],'ob')
if tree.parent==None:
plt.plot([tree.point[0],tree.point[0]],[0,10])
elif d:
if tree.point[0]<tree.parent.point[0]:
plt.plot([0,tree.parent.point[0]],[tree.point[1],tree.point[1]])
else:
plt.plot([tree.parent.point[0],10],[tree.point[1],tree.point[1]])
else:
if tree.point[1]<tree.parent.point[1]:
plt.plot([tree.point[0],tree.point[0]],[0,tree.parent.point[1]])
else:
plt.plot([tree.point[0],tree.point[0]],[tree.parent.point[1],10])
if tree.left != None:
showT(tree.left,not d)
if tree.right != None:
showT(tree.right,not d) kd_tree = build_kdtree(T, 0)
showT(kd_tree,0)
plt.annotate('S',xy = (S[0],S[1]+0.2))
plt.plot(S[0],S[1],'^r')
result=search_kdtree(kd_tree,S)
print result #[7, 2]
plt.show()
k临近法的实现:kd树的更多相关文章
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- 2018牛客多校6 - I Team Rocket KD树维护空间
题意:给出n条铁路区间\([L,R]\),共有m个boom依时间顺序放置在\(k_i\)中,区间与\(k_i\)有交集的都被炸掉 求每次炸掉的铁路个数和最后输出所有id被炸的时间点 炸弹能炸到的区间满 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- k近邻法的C++实现:kd树
1.k近邻算法的思想 给定一个训练集,对于新的输入实例,在训练集中找到与该实例最近的k个实例,这k个实例中的多数属于某个类,就把该输入实例分为这个类. 因为要找到最近的k个实例,所以计算输入实例与训练 ...
- kd树 求k近邻 python 代码
之前两篇随笔介绍了kd树的原理,并用python实现了kd树的构建和搜索,具体可以参考 kd树的原理 python kd树 搜索 代码 kd树常与knn算法联系在一起,knn算法通常要搜索k近邻, ...
- KD树——k=1时就是BST,里面的数学原理还是有不明白的地方,为啥方差划分?
Kd-Tree,即K-dimensional tree,是一棵二叉树,树中存储的是一些K维数据.在一个K维数据集合上构建一棵Kd-Tree代表了对该K维数据集合构成的K维空间的一个划分,即树中的每个结 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
- 【分类算法】K近邻(KNN) ——kd树(转载)
K近邻(KNN)的核心算法是kd树,转载如下几个链接: [量化课堂]一只兔子帮你理解 kNN [量化课堂]kd 树算法之思路篇 [量化课堂]kd 树算法之详细篇
随机推荐
- mysql 1067 启动错误!!!
图二:服务器启动不成功 -- 解决方法
- 知道创宇研发技能表v2.2
知道创宇研发技能表v2.2 2014/3/9 发布 by @知道创宇(www.knownsec.com) @余弦 & 行之 知道创宇是国内Geek十足且普遍被认为特别有前途的互联网安全公司, ...
- Codeforces Round #230 (Div. 2) 解题报告
Problem A. Nineteen 思路: 除了首位像连的n,其他的字母不能共用nineteenineteen.所以可以扫描一遍所有的字符串将出现次数保存到hash数组,n的次数(n - 1) / ...
- VS2013失去智能提示如何恢复
一般智能提示包括,输入智能提示,鼠标移到类,方法,接口,变量上面自动提示相关信息,VS2013常常会失去这种提示功能,遇到这种情况可以这样解决: 1.在开发环境中随便打开一个xxx.aspx页面,也就 ...
- [数据结构]RMQ问题小结
RMQ问题小结 by Wine93 2014.1.14 1.算法简介 RMQ问题可分成以下2种 (1)静态RMQ:ST算法 一旦给定序列确定后就不在更新,只查询区间最大(小)值!这类问题可以用倍增 ...
- [转]ELO等级分体系
[译前注:有读者问ELO等级分体系的说明.观网上好象没发现单篇文章就说得通俗清晰的,只好把找到几篇文章拿在一起合译互相补充.其间发现具体说法稍有差异,但总的来说概念一致.FIDE已经专门制定计算表了, ...
- jQuery实现一个全选复选框联动效果
类似邮件列表里的复选框 要求双向联动 ☛ [实现]: <body> <div> <input type="checkbox" name="c ...
- Sonar + Jacoco,强悍的UT, IT 双覆盖率统计(转)
以前做统计代码测试覆盖,一般用Cobertura.以前统计测试覆盖率,一般只算Unit Test,或者闭上眼睛把Unit Test和Integration Test一起算. 但是,我们已经过了迷信UT ...
- php-多态
<?php //面对对象三大特性//封装//目的:让类更安全//做法:成员变量变为私有的,通过方法来间接操作成员变量,在方法里面加限制条件 //继承//概念:子类可以继承父类的一切//方法重写: ...
- Evaluate Reverse Polish Notation
Evaluate the value of an arithmetic expression in Reverse Polish Notation. Valid operators are +, -, ...