Pandas 数值计算和统计基础
1.(1)
# 基本参数:axis、skipna import numpy as np
import pandas as pd df = pd.DataFrame({'key1':[4,5,3,np.nan,2],
'key2':[1,2,np.nan,4,5],
'key3':[1,2,3,'j','k']},
index = ['a','b','c','d','e'])
print(df)
print(df['key1'].dtype,df['key2'].dtype,df['key3'].dtype)
print('-----') m1 = df.mean()
print(m1,type(m1))
print('单独统计一列:',df['key2'].mean())
print('-----')
# np.nan :空值
# .mean()计算均值
# 只统计数字列,字符串的列不会进行统计了
# 可以通过索引单独统计一列 m2 = df.mean(axis=1)
print(m2)
print('-----')
# axis参数:默认为0,以列来计算,axis=1,以行来计算,这里就按照行来汇总了 m3 = df.mean(skipna=False)
print(m3)
print('-----')
# skipna参数:是否忽略NaN,默认True,如False,有NaN的列统计结果仍未NaN
输出结果:
key1 key2 key3
a 4.0 1.0 1
b 5.0 2.0 2
c 3.0 NaN 3
d NaN 4.0 j
e 2.0 5.0 k
float64 float64 object
-----
key1 3.5
key2 3.0
dtype: float64 <class 'pandas.core.series.Series'>
单独统计一列: 3.0
-----
a 2.5
b 3.5
c 3.0
d 4.0
e 3.5
dtype: float64
-----
key1 NaN
key2 NaN
dtype: float64
-----
(2)
import numpy
ar = numpy.random.rand(1000)
ar.mean() #数组同样计算 引用 输出结果:
0.50208686016230231
(3)
import numpy as np
import pandas as pd
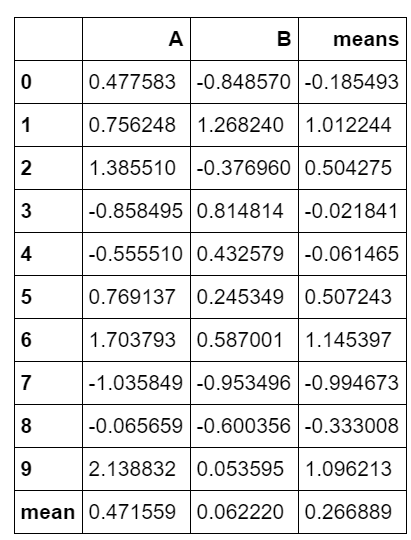
df = pd.DataFrame(np.random.randn(10,2),columns = ['A','B'])
df['means'] = df.mean(axis = 1) # 新增加一列,列名为’mean',axis= 1表示按行计算均值 ,并把计算的均值添加到列means中
print(df)
df.loc['mean'] = df.mean(axis = 0) # 新增加一行,行名为’mean',axis= 0表示按列计算均值 ,并把计算的均值添加到行mean中
df
输出结果:
A B means
0 0.477583 -0.848570 -0.185493
1 0.756248 1.268240 1.012244
2 1.385510 -0.376960 0.504275
3 -0.858495 0.814814 -0.021841
4 -0.555510 0.432579 -0.061465
5 0.769137 0.245349 0.507243
6 1.703793 0.587001 1.145397
7 -1.035849 -0.953496 -0.994673
8 -0.065659 -0.600356 -0.333008
9 2.138832 0.053595 1.096213
2.
# 主要数学计算方法,可用于Series和DataFrame(1)
df = pd.DataFrame({'key1':np.arange(10),
'key2':np.random.rand(10)*10})
print(df)
print('-----')
print(df.count(),'→ count统计非Na值的数量\n')
print(df.min(),'→ min统计最小值\n',df['key2'].max(),'→ max统计最大值\n')
print(df.quantile(q=0.75),'→ quantile统计分位数,参数q确定位置\n')
print(df.sum(),'→ sum求和\n')
print(df.mean(),'→ mean求平均值\n')
print(df.median(),'→ median求算数中位数,50%分位数\n')
print(df.std(),'\n',df.var(),'→ std,var分别求标准差,方差\n')
print(df.skew(),'→ skew样本的偏度\n')
print(df.kurt(),'→ kurt样本的峰度\n')
输出结果:
key1 key2
0 0 6.792638
1 1 1.049023
2 2 5.441224
3 3 4.667631
4 4 2.053692
5 5 9.813006
6 6 5.074884
7 7 1.526651
8 8 8.519215
9 9 3.543486
-----
key1 10
key2 10
dtype: int64 → count统计非Na值的数量 key1 0.000000
key2 1.049023
dtype: float64 → min统计最小值
9.81300585173231 → max统计最大值 key1 6.750000
key2 6.454785
Name: 0.75, dtype: float64 → quantile统计分位数,参数q确定位置 key1 45.00000
key2 48.48145
dtype: float64 → sum求和 key1 4.500000
key2 4.848145
dtype: float64 → mean求平均值 key1 4.500000
key2 4.871257
dtype: float64 → median求算数中位数,50%分位数 key1 3.027650
key2 2.931062
dtype: float64
key1 9.166667
key2 8.591127
dtype: float64 → std,var分别求标准差,方差 key1 0.000000
key2 0.352466
dtype: float64 → skew样本的偏度 key1 -1.20000
key2 -0.79798
dtype: float64 → kurt样本的峰度
3.
# 主要数学计算方法,可用于Series和DataFrame(2) df['key1_s'] = df['key1'].cumsum()
df['key2_s'] = df['key2'].cumsum()
print(df,'→ cumsum样本的累计和\n') df['key1_p'] = df['key1'].cumprod()
df['key2_p'] = df['key2'].cumprod()
print(df,'→ cumprod样本的累计积\n') print(df.cummax(),'\n',df.cummin(),'→ cummax,cummin分别求累计最大值,累计最小值\n')
# 会填充key1,和key2的值
输出结果:
key1 key2 key1_s key2_s
0 0 6.792638 0 6.792638
1 1 1.049023 1 7.841661
2 2 5.441224 3 13.282885
3 3 4.667631 6 17.950515
4 4 2.053692 10 20.004208
5 5 9.813006 15 29.817213
6 6 5.074884 21 34.892097
7 7 1.526651 28 36.418749
8 8 8.519215 36 44.937963
9 9 3.543486 45 48.481450 → cumsum样本的累计和 key1 key2 key1_s key2_s key1_p key2_p
0 0 6.792638 0 6.792638 0 6.792638
1 1 1.049023 1 7.841661 0 7.125633
2 2 5.441224 3 13.282885 0 38.772160
3 3 4.667631 6 17.950515 0 180.974131
4 4 2.053692 10 20.004208 0 371.665151
5 5 9.813006 15 29.817213 0 3647.152301
6 6 5.074884 21 34.892097 0 18508.874743
7 7 1.526651 28 36.418749 0 28256.595196
8 8 8.519215 36 44.937963 0 240724.006055
9 9 3.543486 45 48.481450 0 853002.188425 → cumprod样本的累计积 key1 key2 key1_s key2_s key1_p key2_p
0 0.0 6.792638 0.0 6.792638 0.0 6.792638
1 1.0 6.792638 1.0 7.841661 0.0 7.125633
2 2.0 6.792638 3.0 13.282885 0.0 38.772160
3 3.0 6.792638 6.0 17.950515 0.0 180.974131
4 4.0 6.792638 10.0 20.004208 0.0 371.665151
5 5.0 9.813006 15.0 29.817213 0.0 3647.152301
6 6.0 9.813006 21.0 34.892097 0.0 18508.874743
7 7.0 9.813006 28.0 36.418749 0.0 28256.595196
8 8.0 9.813006 36.0 44.937963 0.0 240724.006055
9 9.0 9.813006 45.0 48.481450 0.0 853002.188425
key1 key2 key1_s key2_s key1_p key2_p
0 0.0 6.792638 0.0 6.792638 0.0 6.792638
1 0.0 1.049023 0.0 6.792638 0.0 6.792638
2 0.0 1.049023 0.0 6.792638 0.0 6.792638
3 0.0 1.049023 0.0 6.792638 0.0 6.792638
4 0.0 1.049023 0.0 6.792638 0.0 6.792638
5 0.0 1.049023 0.0 6.792638 0.0 6.792638
6 0.0 1.049023 0.0 6.792638 0.0 6.792638
7 0.0 1.049023 0.0 6.792638 0.0 6.792638
8 0.0 1.049023 0.0 6.792638 0.0 6.792638
9 0.0 1.049023 0.0 6.792638 0.0 6.792638 → cummax,cummin分别求累计最大值,累计最小值
4.
# 唯一值:.unique()
s = pd.Series(list('asdvasdcfgg'))
sq = s.unique()
print(s)
print(sq,type(sq))
print(pd.Series(sq))
# 得到一个唯一值数组
# 通过pd.Series重新变成新的Series
sq.sort()
print(sq)
# 重新排序
输出结果:
0 a
1 s
2 d
3 v
4 a
5 s
6 d
7 c
8 f
9 g
10 g
dtype: object
['a' 's' 'd' 'v' 'c' 'f' 'g'] <class 'numpy.ndarray'>
0 a
1 s
2 d
3 v
4 c
5 f
6 g
dtype: object
['a' 'c' 'd' 'f' 'g' 's' 'v']
5.
# 值计数:.value_counts() sc = s.value_counts(sort = False) # 也可以这样写:pd.value_counts(sc, sort = False)
print(sc)
# 得到一个新的Series,计算出不同值出现的频率
# sort参数:排序,默认为True
输出结果:
d 2
a 2
s 2
c 1
f 1
g 2
v 1
dtype: int64
6.
# 成员资格:.isin() s = pd.Series(np.arange(10,15))
df = pd.DataFrame({'key1':list('asdcbvasd'),
'key2':np.arange(4,13)})
print(s)
print(df)
print('-----') print(s.isin([5,14])) #判断5和14是否在里面
print(df.isin(['a','bc','',8]))
# 用[]表示
# 得到一个布尔值的Series或者Dataframe
输出结果:
0 10
1 11
2 12
3 13
4 14
dtype: int32
key1 key2
0 a 4
1 s 5
2 d 6
3 c 7
4 b 8
5 v 9
6 a 10
7 s 11
8 d 12
-----
0 False
1 False
2 False
3 False
4 True
dtype: bool
key1 key2
0 True False
1 False False
2 False False
3 False False
4 False True
5 False False
6 True False
7 False False
8 False False
课后题:
写出一个输入元素直接生成数组的代码块,然后创建一个函数,该函数功能用于判断一个Series是否是唯一值数组,返回“是”和“不是”。

import numpy as np
import pandas as pd
#练习1
ar = eval(input("请输入一组元素,以列表的形式:"))
s =pd.Series(ar)
print(s) def f(s):
s1 =s.unique()
if len(s1) == len(s):
print("该数据是唯一值Series")
else:
print("该数据不是唯一值Series") f(s)
Pandas 数值计算和统计基础的更多相关文章
- pandas中的数值计算及统计基础
import pandas as pd import numpy as np df = pd.DataFrame({ 'key1': [4, 5, 3, np.nan, 2], 'key2': [1, ...
- 04. Pandas 3| 数值计算与统计、合并连接去重分组透视表文件读取
1.数值计算和统计基础 常用数学.统计方法 数值计算和统计基础 基本参数:axis.skipna df.mean(axis=1,skipna=False) -->> axis=1是按行来 ...
- Pandas之DataFrame——Part 3
''' [课程2.] 数值计算和统计基础 常用数学.统计方法 ''' # 基本参数:axis.skipna import numpy as np import pandas as pd df = pd ...
- pandas之数值计算与统计
数值计算与统计 对于DataFrame来说,求和.最大.最小.平均等统计方法,默认是按列进行统计,即axis = 0,如果添加参数axis = 1则会按照行进行统计. 如果存在空值,在统计时默认会忽略 ...
- Python 数值计算库之-[Pandas](六)
- Linux 中的数值计算和符号计算
不知道经常需要做科学计算的朋友们有没有这样的好奇:在 Linux 系统下使用什么工具呢?说到科学计算,首先想到的肯定是 Matlab,如果再说到符号计算,那就非 Mathematica 不可了.可惜, ...
- 【转载】使用Pandas创建数据透视表
使用Pandas创建数据透视表 本文转载自:蓝鲸的网站分析笔记 原文链接:使用Pandas创建数据透视表 目录 pandas.pivot_table() 创建简单的数据透视表 增加一个行维度(inde ...
- python与数值计算环境搭建
数值计算的编程的软件很多种,也见过一些编程绘图软件的对比. 利用Python进行数值计算,需要用到numpy(矩阵) ,scipy(公式符号), matplotlib(绘图)这些工具包. 1.Linu ...
- Python 数据处理扩展包: numpy 和 pandas 模块介绍
一.numpy模块 NumPy(Numeric Python)模块是Python的一种开源的数值计算扩展.这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list str ...
随机推荐
- jq中事件绑定的方法
在唯品会实习生面试中,被面试官问了这么一个问题,“jQuery中绑定事件的方法有几个?”,以click事件为例,我当时想到的只有.click(),.bind(),.on()这三种,然后面试官又追问,“ ...
- 编写tab切换插件
html: <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF ...
- Android基础Activity篇——其他隐式Intent
1.使用隐式Intent调用浏览器 修改FirstActivity中的按钮点击事件代码. Intent intent=new Intent(Intent.ACTION_VIEW); intent.se ...
- 安装xp系统步骤
下载魔方的绿色软件,使用U盘制作工具 下载xpghost系统. 制作PE,然后把下载的IOS解压后放在U盘 电脑bios设置从u盘启动进入pe系统 运行安装系统
- 如何将windows日志转成syslog格式并发到远程sysylog服务器
安装Snare, 随便找了个版本下载下来,安装一路next,除了中间让你输入一次http的管理登录口令. 2,配置 之后打开URL:http://192.168.37.23:6161/,输入默 ...
- 入坑Ubuntu手记-系统安装和简单配置
对于开发者而言,Linux的环境帮助是非常大的.同样的,Linux对很多Windows下的软件,尤其是游戏不支持,这也是一个非常重要的生产力的因素.嗯…我可能就是为了控制自己少玩游戏,直接上一个Ubu ...
- 使用browsermob代理出现错误java.lang.NoClassDefFoundError: org/littleshoot/proxy/HttpFiltersSource
使用browsermob代理做埋点数据,maven配置的包如下 <dependency> <groupId>net.lightbody.bmp</groupId> ...
- SpringMVC接受JSON参数详解
转:https://blog.csdn.net/LostSh/article/details/68923874 SpringMVC接受JSON参数详解及常见错误总结 最近一段时间不想使用Session ...
- sublime text 3 python 控制台输出中文乱码解决方案
自建的python运行环境如下:python3 找到python3.sublime-build文件打开,在文件中加入"env": { "PYTHONIOENCODING& ...
- 用蒙特卡洛方法计算派-python和R语言
用蒙特卡洛方法算pi-基于python和R语言 最近follow了MOOC上一门python课,开始学Python.同时,买来了概率论与数理统计,准备自学一下统计.(因为被鄙视过不是统计专业却想搞数据 ...