But what exactly do we mean by "gets closer to"?
https://rdipietro.github.io/friendly-intro-to-cross-entropy-loss/
【将输入转化为输出:概率分布】
When we develop a model for probabilistic classification, we aim to map the model's inputs to probabilistic predictions, and we often train our model by incrementally adjusting the model's parameters so that our predictions get closer and closer to ground-truth probabilities.
In this post, we'll focus on models that assume that classes are mutually exclusive. For example, if we're interested in determining whether an image is best described as a landscape or as a house or as something else, then our model might accept an image as input and produce three numbers as output, each representing the probability of a single class.
During training, we might put in an image of a landscape, and we hope that our model produces predictions that are close to the ground-truth class probabilities y=(1.0,0.0,0.0)Ty=(1.0,0.0,0.0)T. If our model predicts a different distribution, say y^=(0.4,0.1,0.5)Ty^=(0.4,0.1,0.5)T, then we'd like to nudge the parameters so that y^y^ gets closer to yy.
【cross entropy 交叉熵 提供了一种量化的解决办法】
But what exactly do we mean by "gets closer to"? In particular, how should we measure the difference between y^y^ and yy?
This post describes one possible measure, cross entropy, and describes why it's reasonable for the task of classification.
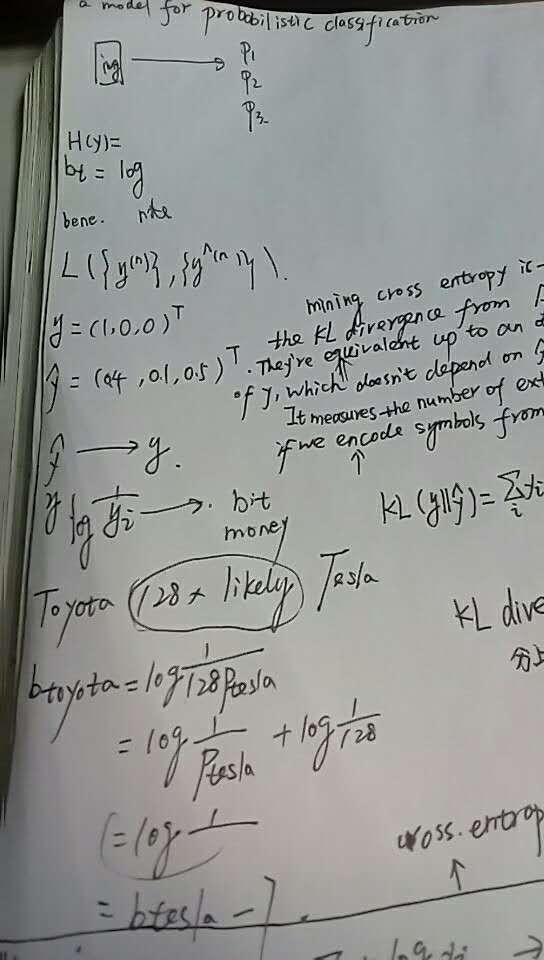
https://rdipietro.github.io/friendly-intro-to-cross-entropy-loss/

zh.wikipedia.org/wiki/相对熵
KL散度是两个概率分布P和Q差别的非对称性的度量。 KL散度是用来 度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数。 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
en.wikipedia.org/wiki/Kullback–Leibler_divergence
In the context of machine learning, DKL(P‖Q) is often called the information gain achieved if P is used instead of Q. By analogy with information theory, it is also called the relative entropy of P with respect to Q. In the context of coding theory, DKL(P‖Q) can be constructed as measuring the expected number of extra bits required to codesamples from P using a code optimized for Q rather than the code optimized for P.
https://rdipietro.github.io/friendly-intro-to-cross-entropy-loss/
When we develop a probabilistic model over mutually exclusive classes, we need a way to measure the difference between predicted probabilities y^y^ and ground-truth probabilities yy, and during training we try to tune parameters so that this difference is minimized.
But what exactly do we mean by "gets closer to"?的更多相关文章
- CSS——关于z-index及层叠上下文(stacking context)
以下内容根据CSS规范翻译. z-index 'z-index'Value: auto | <integer> | inheritInitial: autoApplies to: posi ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
- Java
2016-12-17 21:10:28 吉祥物:Duke(公爵) Logo:咖啡(爪哇岛盛产咖啡) An overview of the software development proce ...
- Netty实现高性能RPC服务器优化篇之消息序列化
在本人写的前一篇文章中,谈及有关如何利用Netty开发实现,高性能RPC服务器的一些设计思路.设计原理,以及具体的实现方案(具体参见:谈谈如何使用Netty开发实现高性能的RPC服务器).在文章的最后 ...
- 基于Netty打造RPC服务器设计经验谈
自从在园子里,发表了两篇如何基于Netty构建RPC服务器的文章:谈谈如何使用Netty开发实现高性能的RPC服务器.Netty实现高性能RPC服务器优化篇之消息序列化 之后,收到了很多同行.园友们热 ...
- Netty构建分布式消息队列实现原理浅析
在本人的上一篇博客文章:Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇 中,重点向大家介绍了AvatarMQ主要构成模块以及目前存在的优缺点.最后以一个生产者.消费者传递消息的例子, ...
- Fedora 24中的日志管理
Introduction Log files are files that contain messages about the system, including the kernel, servi ...
- [Mahout] 完整部署过程
概述 Mahout底层依赖Hadoop,部署Mahout过程中最困难的就是Hadoop的部署 本文假设用户本身没有进行Hadoop的部署,记述部署Mahout的过程 ...
- 【java】jstack
介绍 jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项"-J-d64",Windows的jsta ...
- Underscore.js
概述 Underscore.js是一个很精干的库,压缩后只有4KB.它提供了几十种函数式编程的方法,弥补了标准库的不足,大大方便了JavaScript的编程.MVC框架Backbone.js就将这个库 ...
随机推荐
- memcache运行机制(转)
网上其实有很多文章说明了memcached是如何运作的,特别是底层的内存分配是如何运作的.我参考过很多资料,比较有启发意义的有几个: 首先是官方的英文资料,虽然文章太多.很难看懂,我个人觉得说得也不是 ...
- JPEG编码(二)
来自CSDN评论区http://bbs.csdn.net/topics/190980 1. 色彩模型 JPEG 的图片使用的是 YCrCb 颜色模型, 而不是计算机上最常用的 RGB. 关于色彩模型, ...
- OpenSSL 有关密钥的那些事儿(HOWTO keys)
<DRAFT!> OpenSSL 有关密钥的那些事儿(HOWTO keys) 1. 介绍(Introduction) Keys are the basis of public key al ...
- UVA 111 (复习dp, 14.07.09)
History Grading Background Many problems in Computer Science involve maximizing some measure accor ...
- iOS技巧
在不使用加急的情况下,可以利用appstore“可以随时修改上架时间和发布国家.价格而无需再次审核”的规则,先提交小国市场快速过审,准备上架销售时再改回中国——如同样是中文版本,你可以先把游戏上到新加 ...
- Android学习(九) SharedPreferences
一.SharedPreferences:一种清醒的存储方式,基于XML存储key-value键值对方式的数据. SharedPreferences对象本身只能获取数据,而不能存储和修改数据,存储修改只 ...
- Php函数之end
Php函数之end end()函数 (PHP 4, PHP 5, PHP 7) end - 将数组的内部指针指向最后一个单元 说明 mixed end ( array &$array ) en ...
- 【BIEE】11_BIEE图形报表在谷歌浏览器64.0.3282.140中访问图例乱码解决
如上图,使用谷歌浏览器访问BIEE图形报表的时候,标题.图例等涉及到中文的地方全部乱码了!但是用IE打开是不会乱码的,这是由于:谷歌需要设置编码格式 但是55版本以后,谷歌公司为了加快浏览器的速度,提 ...
- Ros 中的多线程
参考文献:http://blog.csdn.net/sinat_27554409/article/details/48446611 老王说ROS http://blog.csdn.net/yake ...
- HDU4647:Another Graph Game(贪心)
Problem Description Alice and Bob are playing a game on an undirected graph with n (n is even) nodes ...