But what exactly do we mean by "gets closer to"?
https://rdipietro.github.io/friendly-intro-to-cross-entropy-loss/
【将输入转化为输出:概率分布】
When we develop a model for probabilistic classification, we aim to map the model's inputs to probabilistic predictions, and we often train our model by incrementally adjusting the model's parameters so that our predictions get closer and closer to ground-truth probabilities.
In this post, we'll focus on models that assume that classes are mutually exclusive. For example, if we're interested in determining whether an image is best described as a landscape or as a house or as something else, then our model might accept an image as input and produce three numbers as output, each representing the probability of a single class.
During training, we might put in an image of a landscape, and we hope that our model produces predictions that are close to the ground-truth class probabilities y=(1.0,0.0,0.0)Ty=(1.0,0.0,0.0)T. If our model predicts a different distribution, say y^=(0.4,0.1,0.5)Ty^=(0.4,0.1,0.5)T, then we'd like to nudge the parameters so that y^y^ gets closer to yy.
【cross entropy 交叉熵 提供了一种量化的解决办法】
But what exactly do we mean by "gets closer to"? In particular, how should we measure the difference between y^y^ and yy?
This post describes one possible measure, cross entropy, and describes why it's reasonable for the task of classification.
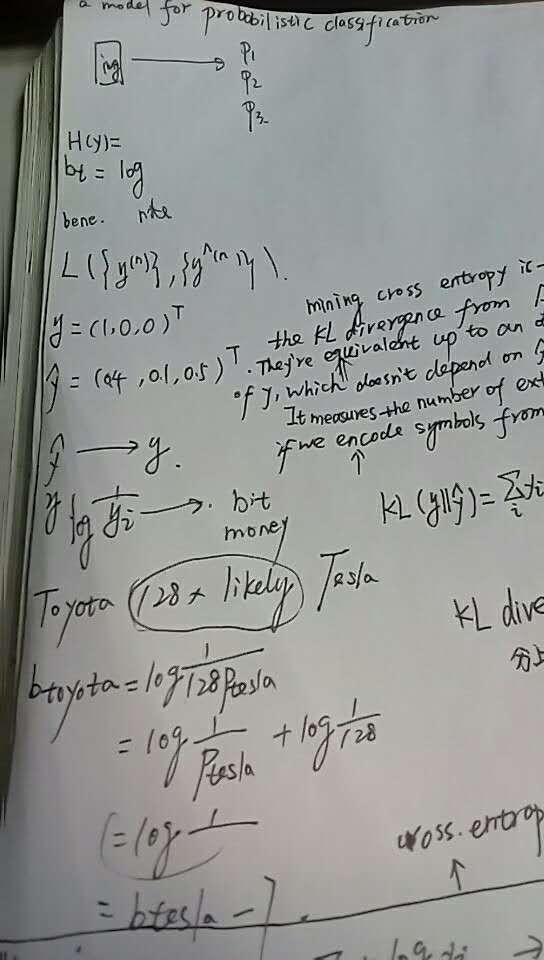
https://rdipietro.github.io/friendly-intro-to-cross-entropy-loss/

zh.wikipedia.org/wiki/相对熵
KL散度是两个概率分布P和Q差别的非对称性的度量。 KL散度是用来 度量使用基于Q的编码来编码来自P的样本平均所需的额外的位元数。 典型情况下,P表示数据的真实分布,Q表示数据的理论分布,模型分布,或P的近似分布。
en.wikipedia.org/wiki/Kullback–Leibler_divergence
In the context of machine learning, DKL(P‖Q) is often called the information gain achieved if P is used instead of Q. By analogy with information theory, it is also called the relative entropy of P with respect to Q. In the context of coding theory, DKL(P‖Q) can be constructed as measuring the expected number of extra bits required to codesamples from P using a code optimized for Q rather than the code optimized for P.
https://rdipietro.github.io/friendly-intro-to-cross-entropy-loss/
When we develop a probabilistic model over mutually exclusive classes, we need a way to measure the difference between predicted probabilities y^y^ and ground-truth probabilities yy, and during training we try to tune parameters so that this difference is minimized.
But what exactly do we mean by "gets closer to"?的更多相关文章
- CSS——关于z-index及层叠上下文(stacking context)
以下内容根据CSS规范翻译. z-index 'z-index'Value: auto | <integer> | inheritInitial: autoApplies to: posi ...
- 基于Ubuntu Hadoop的群集搭建Hive
Hive是Hadoop生态中的一个重要组成部分,主要用于数据仓库.前面的文章中我们已经搭建好了Hadoop的群集,下面我们在这个群集上再搭建Hive的群集. 1.安装MySQL 1.1安装MySQL ...
- Java
2016-12-17 21:10:28 吉祥物:Duke(公爵) Logo:咖啡(爪哇岛盛产咖啡) An overview of the software development proce ...
- Netty实现高性能RPC服务器优化篇之消息序列化
在本人写的前一篇文章中,谈及有关如何利用Netty开发实现,高性能RPC服务器的一些设计思路.设计原理,以及具体的实现方案(具体参见:谈谈如何使用Netty开发实现高性能的RPC服务器).在文章的最后 ...
- 基于Netty打造RPC服务器设计经验谈
自从在园子里,发表了两篇如何基于Netty构建RPC服务器的文章:谈谈如何使用Netty开发实现高性能的RPC服务器.Netty实现高性能RPC服务器优化篇之消息序列化 之后,收到了很多同行.园友们热 ...
- Netty构建分布式消息队列实现原理浅析
在本人的上一篇博客文章:Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇 中,重点向大家介绍了AvatarMQ主要构成模块以及目前存在的优缺点.最后以一个生产者.消费者传递消息的例子, ...
- Fedora 24中的日志管理
Introduction Log files are files that contain messages about the system, including the kernel, servi ...
- [Mahout] 完整部署过程
概述 Mahout底层依赖Hadoop,部署Mahout过程中最困难的就是Hadoop的部署 本文假设用户本身没有进行Hadoop的部署,记述部署Mahout的过程 ...
- 【java】jstack
介绍 jstack用于打印出给定的java进程ID或core file或远程调试服务的Java堆栈信息,如果是在64位机器上,需要指定选项"-J-d64",Windows的jsta ...
- Underscore.js
概述 Underscore.js是一个很精干的库,压缩后只有4KB.它提供了几十种函数式编程的方法,弥补了标准库的不足,大大方便了JavaScript的编程.MVC框架Backbone.js就将这个库 ...
随机推荐
- 遗传算法解决TSP问题
1实验环境 实验环境:CPU i5-2450M@2.50GHz,内存6G,windows7 64位操作系统 实现语言:java (JDK1.8) 实验数据:TSPLIB,TSP采样实例库中的att48 ...
- Linux修改SSH端口
为什么要修改默认22端口 最近公司ssh全部换掉了默认的22端口,主要是为了防止被黑客大规模的扫描. 修改步骤 如果有需要请关闭防火墙(防止改错端口无法登陆) 修改sshd_config vim /e ...
- EffectiveJava(2)应对多个构造函数应当使用构建器
** 应对多个构造函数应当使用构建器 ** 静态工厂和构造器都不能很好的扩展到大量的可选参数,遇到大量参数有大量可选域时,只能重复生成可选参数递增的构造方法,这种构造模式叫做重叠构造器模式 javaB ...
- Python<1>List
list里的元素以逗号隔开,以[]包围,当中元素的类型随意 官方一点的说:list列表是一个随意类型的对象的位置相关的有序集合. 它没有固定的大小(1).通过对偏移量 (2)进行赋值以及其它各种列表的 ...
- Angular 学习笔记——ng-Resource
<!DOCTYPE HTML> <html ng-app="myApp"> <head> <meta http-equiv="C ...
- 关于websocket和ajax无刷新
HTTP无状态: Ajax只能实现用户和服务器单方面响应(单工机制). 如果设置为长轮询(ajax设置多少秒进行一次请求,时间间隙可能会有延迟,且浪费资源) 如果设置为长连接(客户端请求一次,服务器保 ...
- shell 命令行语句
第一步:ssh免密码登陆[用公钥,私钥] 第二步: #!/bin/bash while read server;do ssh -n $server >& |sed "s/^/$ ...
- Android RxJava使用介绍(四) RxJava的操作符
本篇文章继续介绍下面类型的操作符 Combining Observables(Observable的组合操作符) Error Handling Operators(Observable的错误处理操作符 ...
- index+small+row+if经典函数组合应用
EXCEL中index+small+row+if 函数组合可以查出满足同一条件的所有记录,通过实例讲解: 本文为原创,转载需标明出处,谢谢! 例:查找出一年级的所有班级及人数: A B C D 1 年 ...
- myeclipse svn安装
安装subclipse, SVN 插件 1.从官网下载site-1.6.9.zip文件,网址是:subclipse.tigris.org, 2.从中解压出features与plugins文件夹,复制到 ...